 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Grained Cross-modal Alignment for Learning Open-vocabulary Semantic Segmentation from Text Supervision
Mar 06, 2024Recently, learning open-vocabulary semantic segmentation from text supervision has achieved promising downstream performance. Nevertheless, current approaches encounter an alignment granularity gap owing to the absence of dense annotations, wherein they learn coarse image/region-text alignment during training yet perform group/pixel-level predictions at inference. Such discrepancy leads to suboptimal learning efficiency and inferior zero-shot segmentation results. In this paper, we introduce a Multi-Grained Cross-modal Alignment (MGCA) framework, which explicitly learns pixel-level alignment along with object- and region-level alignment to bridge the granularity gap without any dense annotations. Specifically, MGCA ingeniously constructs pseudo multi-granular semantic correspondences upon image-text pairs and collaborates with hard sampling strategies to facilitate fine-grained cross-modal contrastive learning. Further, we point out the defects of existing group and pixel prediction units in downstream segmentation and develop an adaptive semantic unit which effectively mitigates their dilemmas including under- and over-segmentation. Training solely on CC3M, our method achieves significant advancements over state-of-the-art methods, demonstrating its effectiveness and efficiency.
Towards Generalizable Referring Image Segmentation via Target Prompt and Visual Coherence
Dec 01, 2023
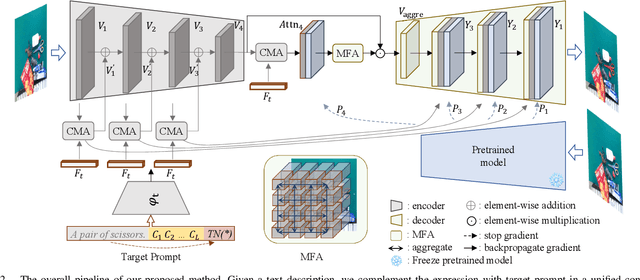
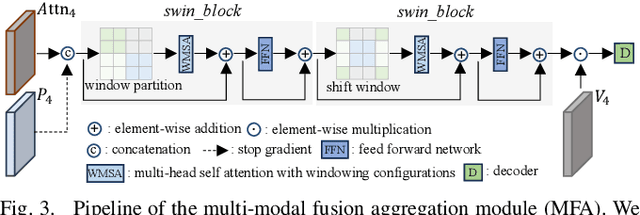

Referring image segmentation (RIS) aims to segment objects in an image conditioning on free-from text descriptions. Despite the overwhelming progress, it still remains challenging for current approaches to perform well on cases with various text expressions or with unseen visual entities, limiting its further application. In this paper, we present a novel RIS approach, which substantially improves the generalization ability by addressing the two dilemmas mentioned above. Specially, to deal with unconstrained texts, we propose to boost a given expression with an explicit and crucial prompt, which complements the expression in a unified context, facilitating target capturing in the presence of linguistic style changes. Furthermore, we introduce a multi-modal fusion aggregation module with visual guidance from a powerful pretrained model to leverage spatial relations and pixel coherences to handle the incomplete target masks and false positive irregular clumps which often appear on unseen visual entities. Extensive experiments are conducted in the zero-shot cross-dataset settings and the proposed approach achieves consistent gains compared to the state-of-the-art, e.g., 4.15\%, 5.45\%, and 4.64\% mIoU increase on RefCOCO, RefCOCO+ and ReferIt respectively, demonstrating its effectiveness. Additionally, the results on GraspNet-RIS show that our approach also generalizes well to new scenarios with large domain shifts.
An Empirical Study on Multi-Domain Robust Semantic Segmentation
Dec 08, 2022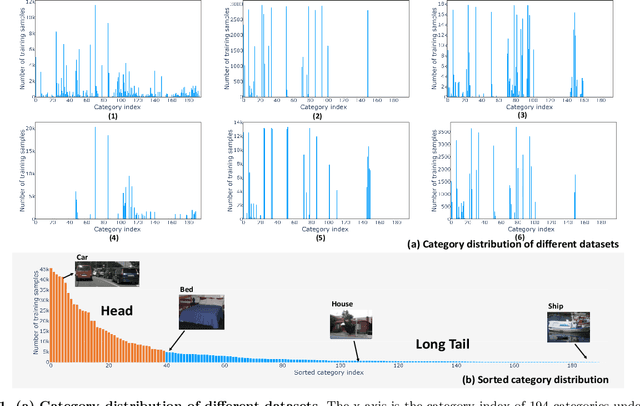

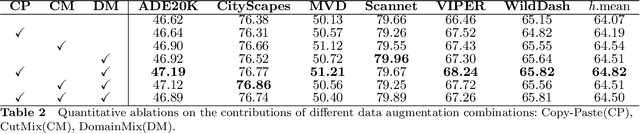
How to effectively leverage the plentiful existing datasets to train a robust and high-performance model is of great significance for many practical applications. However, a model trained on a naive merge of different datasets tends to obtain poor performance due to annotation conflicts and domain divergence.In this paper, we attempt to train a unified model that is expected to perform well across domains on several popularity segmentation datasets.We conduct a detailed analysis of the impact on model generalization from three aspects of data augmentation, training strategies, and model capacity.Based on the analysis, we propose a robust solution that is able to improve model generalization across domains.Our solution ranks 2nd on RVC 2022 semantic segmentation task, with a dataset only 1/3 size of the 1st model used.