 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Robot Coordination through Locality-Based Factorized Multi-Agent Actor-Critic Algorithm
Mar 24, 2025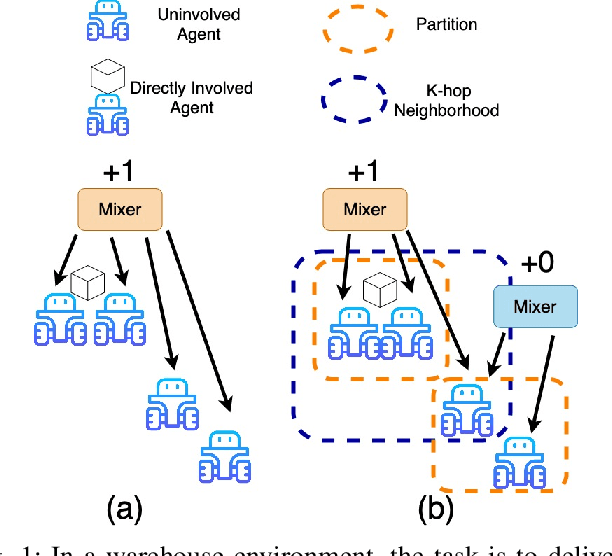
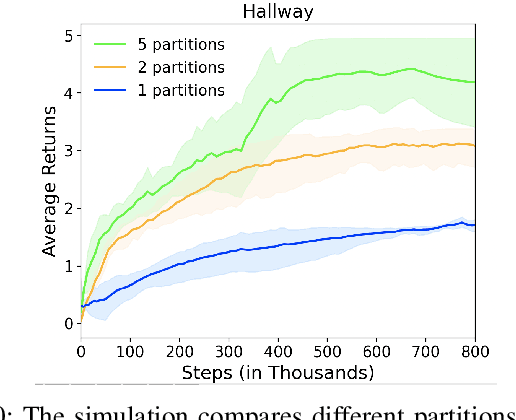
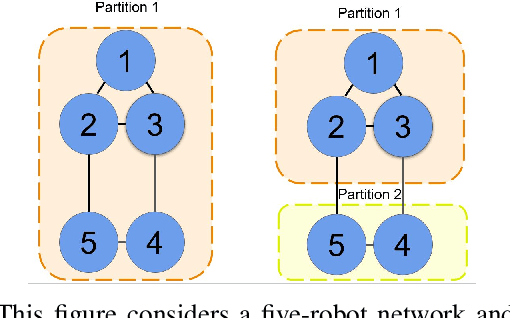
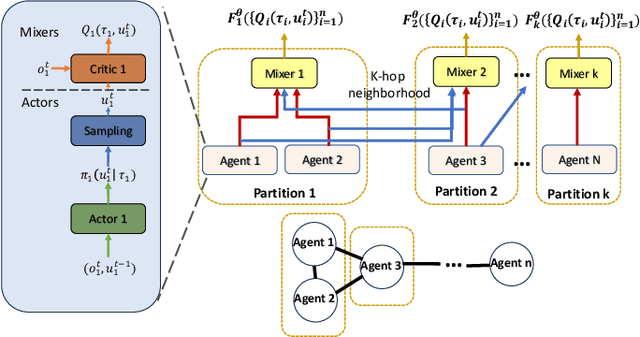
In this work, we present a novel cooperative multi-agent reinforcement learning method called \textbf{Loc}ality based \textbf{Fac}torized \textbf{M}ulti-Agent \textbf{A}ctor-\textbf{C}ritic (Loc-FACMAC). Existing state-of-the-art algorithms, such as FACMAC, rely on global reward information, which may not accurately reflect the quality of individual robots' actions in decentralized systems. We integrate the concept of locality into critic learning, where strongly related robots form partitions during training. Robots within the same partition have a greater impact on each other, leading to more precise policy evaluation. Additionally, we construct a dependency graph to capture the relationships between robots, facilitating the partitioning process. This approach mitigates the curse of dimensionality and prevents robots from using irrelevant information. Our method improves existing algorithms by focusing on local rewards and leveraging partition-based learning to enhance training efficiency and performance. We evaluate the performance of Loc-FACMAC in three environments: Hallway, Multi-cartpole, and Bounded-Cooperative-Navigation. We explore the impact of partition sizes on the performance and compare the result with baseline MARL algorithms such as LOMAQ, FACMAC, and QMIX. The experiments reveal that, if the locality structure is defined properly, Loc-FACMAC outperforms these baseline algorithms up to 108\%, indicating that exploiting the locality structure in the actor-critic framework improves the MARL performance.
SERN: Simulation-Enhanced Realistic Navigation for Multi-Agent Robotic Systems in Contested Environments
Oct 22, 2024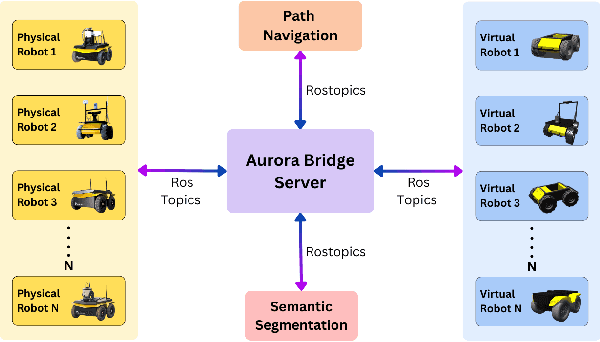
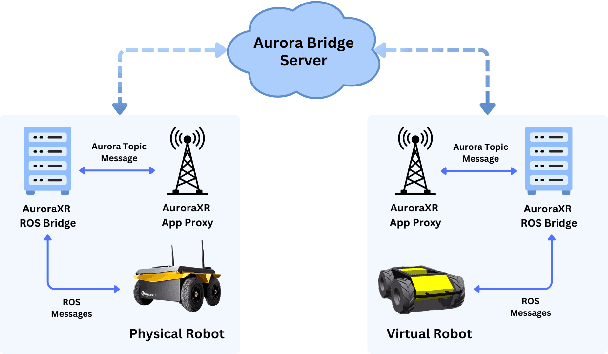
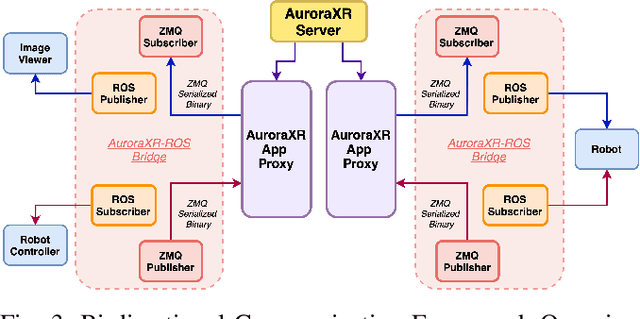
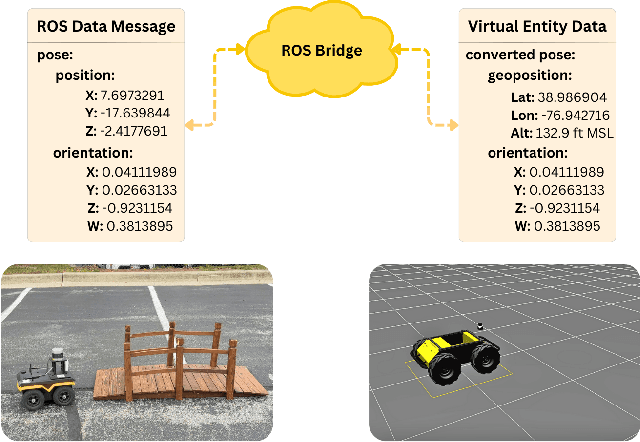
The increasing deployment of autonomous systems in complex environments necessitates efficient communication and task completion among multiple agents. This paper presents SERN (Simulation-Enhanced Realistic Navigation), a novel framework integrating virtual and physical environments for real-time collaborative decision-making in multi-robot systems. SERN addresses key challenges in asset deployment and coordination through a bi-directional communication framework using the AuroraXR ROS Bridge. Our approach advances the SOTA through accurate real-world representation in virtual environments using Unity high-fidelity simulator; synchronization of physical and virtual robot movements; efficient ROS data distribution between remote locations; and integration of SOTA semantic segmentation for enhanced environmental perception. Our evaluations show a 15% to 24% improvement in latency and up to a 15% increase in processing efficiency compared to traditional ROS setups. Real-world and virtual simulation experiments with multiple robots demonstrate synchronization accuracy, achieving less than 5 cm positional error and under 2-degree rotational error. These results highlight SERN's potential to enhance situational awareness and multi-agent coordination in diverse, contested environments.
Learning to Guide Multiple Heterogeneous Actors from a Single Human Demonstration via Automatic Curriculum Learning in StarCraft II
May 11, 2022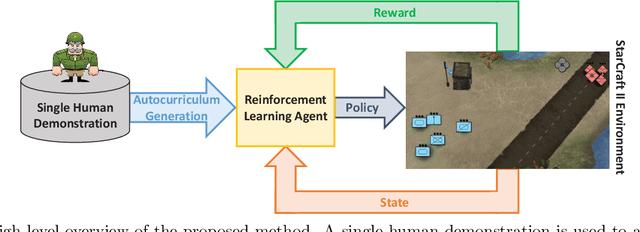


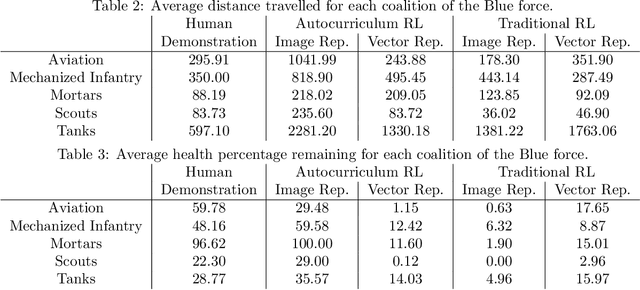
Traditionally, learning from human demonstrations via direct behavior cloning can lead to high-performance policies given that the algorithm has access to large amounts of high-quality data covering the most likely scenarios to be encountered when the agent is operating. However, in real-world scenarios, expert data is limited and it is desired to train an agent that learns a behavior policy general enough to handle situations that were not demonstrated by the human expert. Another alternative is to learn these policies with no supervision via deep reinforcement learning, however, these algorithms require a large amount of computing time to perform well on complex tasks with high-dimensional state and action spaces, such as those found in StarCraft II. Automatic curriculum learning is a recent mechanism comprised of techniques designed to speed up deep reinforcement learning by adjusting the difficulty of the current task to be solved according to the agent's current capabilities. Designing a proper curriculum, however, can be challenging for sufficiently complex tasks, and thus we leverage human demonstrations as a way to guide agent exploration during training. In this work, we aim to train deep reinforcement learning agents that can command multiple heterogeneous actors where starting positions and overall difficulty of the task are controlled by an automatically-generated curriculum from a single human demonstration. Our results show that an agent trained via automated curriculum learning can outperform state-of-the-art deep reinforcement learning baselines and match the performance of the human expert in a simulated command and control task in StarCraft II modeled over a real military scenario.
Strategic Maneuver and Disruption with Reinforcement Learning Approaches for Multi-Agent Coordination
Mar 17, 2022
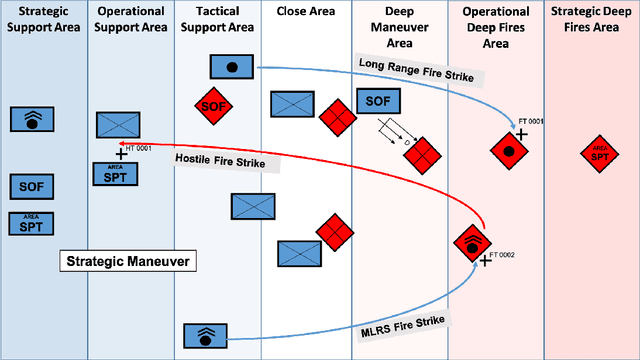
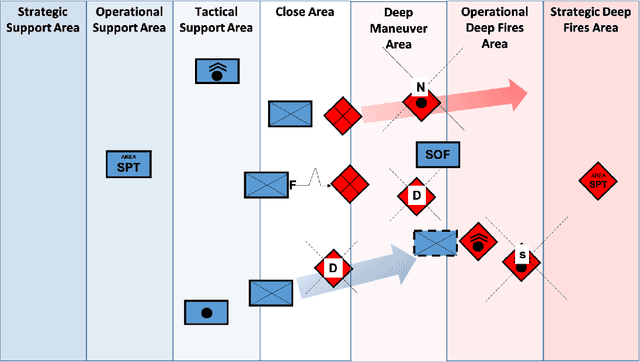
Reinforcement learning (RL) approaches can illuminate emergent behaviors that facilitate coordination across teams of agents as part of a multi-agent system (MAS), which can provide windows of opportunity in various military tasks. Technologically advancing adversaries pose substantial risks to a friendly nation's interests and resources. Superior resources alone are not enough to defeat adversaries in modern complex environments because adversaries create standoff in multiple domains against predictable military doctrine-based maneuvers. Therefore, as part of a defense strategy, friendly forces must use strategic maneuvers and disruption to gain superiority in complex multi-faceted domains such as multi-domain operations (MDO). One promising avenue for implementing strategic maneuver and disruption to gain superiority over adversaries is through coordination of MAS in future military operations. In this paper, we present overviews of prominent works in the RL domain with their strengths and weaknesses for overcoming the challenges associated with performing autonomous strategic maneuver and disruption in military contexts.
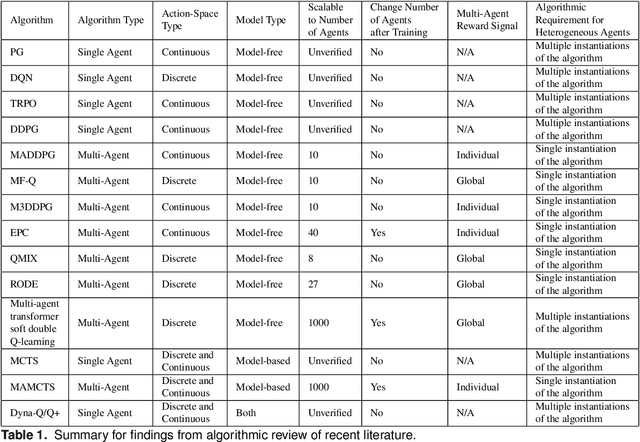
Survey of Recent Multi-Agent Reinforcement Learning Algorithms Utilizing Centralized Training
Jul 29, 2021Much work has been dedicated to the exploration of Multi-Agent Reinforcement Learning (MARL) paradigms implementing a centralized learning with decentralized execution (CLDE) approach to achieve human-like collaboration in cooperative tasks. Here, we discuss variations of centralized training and describe a recent survey of algorithmic approaches. The goal is to explore how different implementations of information sharing mechanism in centralized learning may give rise to distinct group coordinated behaviors in multi-agent systems performing cooperative tasks.
* This article appeared in the news at: https://www.army.mil/article/247261/army_researchers_develop_innovative_framework_for_training_ai