 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERN: Simulation-Enhanced Realistic Navigation for Multi-Agent Robotic Systems in Contested Environments
Oct 22, 2024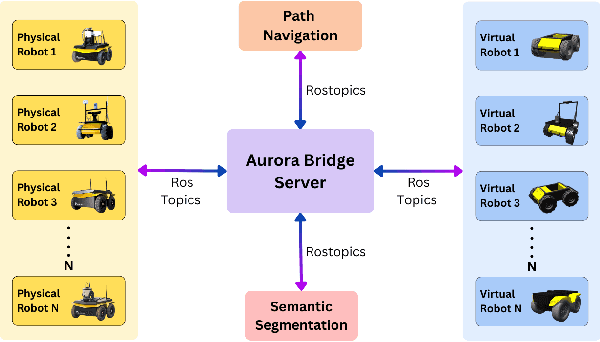
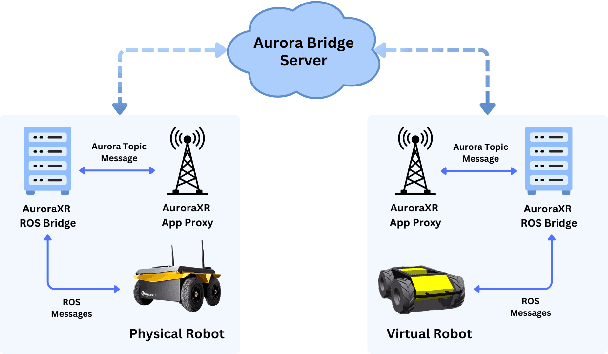
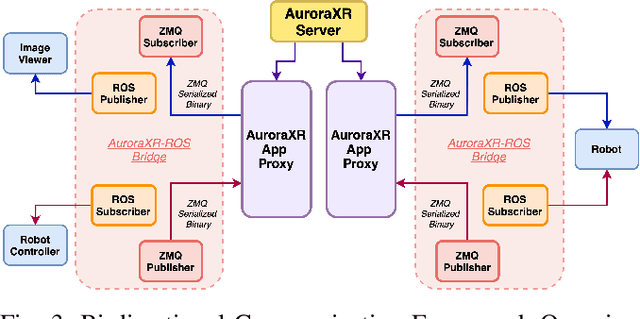
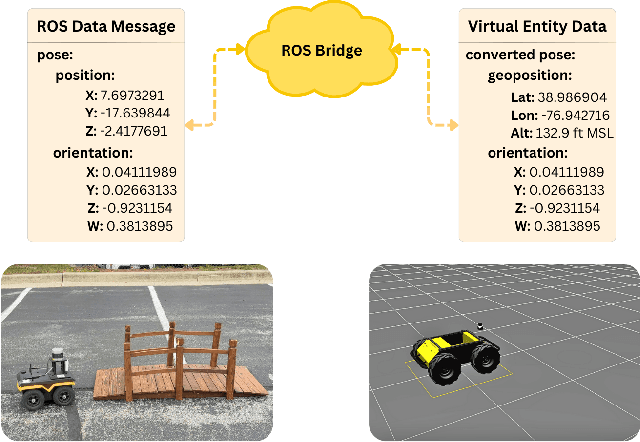
The increasing deployment of autonomous systems in complex environments necessitates efficient communication and task completion among multiple agents. This paper presents SERN (Simulation-Enhanced Realistic Navigation), a novel framework integrating virtual and physical environments for real-time collaborative decision-making in multi-robot systems. SERN addresses key challenges in asset deployment and coordination through a bi-directional communication framework using the AuroraXR ROS Bridge. Our approach advances the SOTA through accurate real-world representation in virtual environments using Unity high-fidelity simulator; synchronization of physical and virtual robot movements; efficient ROS data distribution between remote locations; and integration of SOTA semantic segmentation for enhanced environmental perception. Our evaluations show a 15% to 24% improvement in latency and up to a 15% increase in processing efficiency compared to traditional ROS setups. Real-world and virtual simulation experiments with multiple robots demonstrate synchronization accuracy, achieving less than 5 cm positional error and under 2-degree rotational error. These results highlight SERN's potential to enhance situational awareness and multi-agent coordination in diverse, contested environments.
QuasiNav: Asymmetric Cost-Aware Navigation Planning with Constrained Quasimetric Reinforcement Learning
Oct 22, 2024Autonomous navigation in unstructured outdoor environments is inherently challenging due to the presence of asymmetric traversal costs, such as varying energy expenditures for uphill versus downhill movement. Traditional reinforcement learning methods often assume symmetric costs, which can lead to suboptimal navigation paths and increased safety risks in real-world scenarios. In this paper, we introduce QuasiNav, a novel reinforcement learning framework that integrates quasimetric embeddings to explicitly model asymmetric costs and guide efficient, safe navigation. QuasiNav formulates the navigation problem as a constrained Markov decision process (CMDP) and employs quasimetric embeddings to capture directionally dependent costs, allowing for a more accurate representation of the terrain. This approach is combined with adaptive constraint tightening within a constrained policy optimization framework to dynamically enforce safety constraints during learning. We validate QuasiNav across three challenging navigation scenarios-undulating terrains, asymmetric hill traversal, and directionally dependent terrain traversal-demonstrating its effectiveness in both simulated and real-world environments. Experimental results show that QuasiNav significantly outperforms conventional methods, achieving higher success rates, improved energy efficiency, and better adherence to safety constraints.
EnCoMP: Enhanced Covert Maneuver Planning using Offline Reinforcement Learning
Mar 29, 2024Cover navigation in complex environments is a critical challenge for autonomous robots, requiring the identification and utilization of environmental cover while maintaining efficient navigation. We propose an enhanced navigation system that enables robots to identify and utilize natural and artificial environmental features as cover, thereby minimizing exposure to potential threats. Our perception pipeline leverages LiDAR data to generate high-fidelity cover maps and potential threat maps, providing a comprehensive understanding of the surrounding environment. We train an offline reinforcement learning model using a diverse dataset collected from real-world environments, learning a robust policy that evaluates the quality of candidate actions based on their ability to maximize cover utilization, minimize exposure to threats, and reach the goal efficiently. Extensive real-world experiments demonstrate the superiority of our approach in terms of success rate, cover utilization, exposure minimization, and navigation efficiency compared to state-of-the-art methods.
TopoNav: Topological Navigation for Efficient Exploration in Sparse Reward Environments
Feb 06, 2024
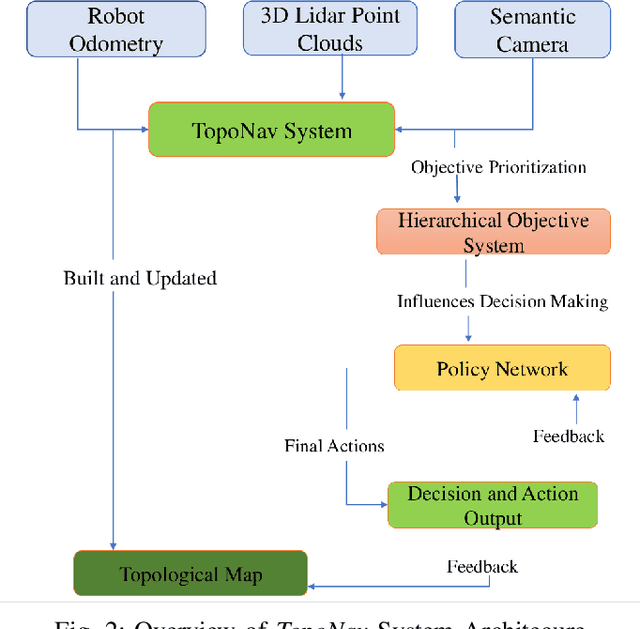


Autonomous robots exploring unknown areas face a significant challenge -- navigating effectively without prior maps and with limited external feedback. This challenge intensifies in sparse reward environments, where traditional exploration techniques often fail. In this paper, we introduce TopoNav, a novel framework that empowers robots to overcome these constraints and achieve efficient, adaptable, and goal-oriented exploration. TopoNav's fundamental building blocks are active topological mapping, intrinsic reward mechanisms, and hierarchical objective prioritization. Throughout its exploration, TopoNav constructs a dynamic topological map that captures key locations and pathways. It utilizes intrinsic rewards to guide the robot towards designated sub-goals within this map, fostering structured exploration even in sparse reward settings. To ensure efficient navigation, TopoNav employs the Hierarchical Objective-Driven Active Topologies framework, enabling the robot to prioritize immediate tasks like obstacle avoidance while maintaining focus on the overall goal. We demonstrate TopoNav's effectiveness in simulated environments that replicate real-world conditions. Our results reveal significant improvements in exploration efficiency, navigational accuracy, and adaptability to unforeseen obstacles, showcasing its potential to revolutionize autonomous exploration in a wide range of applications, including search and rescue, environmental monitoring, and planetary exploration.
CoverNav: Cover Following Navigation Planning in Unstructured Outdoor Environment with Deep Reinforcement Learning
Aug 12, 2023



Autonomous navigation in offroad environments has been extensively studied in the robotics field. However, navigation in covert situations where an autonomous vehicle needs to remain hidden from outside observers remains an underexplored area. In this paper, we propose a novel Deep Reinforcement Learning (DRL) based algorithm, called CoverNav, for identifying covert and navigable trajectories with minimal cost in offroad terrains and jungle environments in the presence of observers. CoverNav focuses on unmanned ground vehicles seeking shelters and taking covers while safely navigating to a predefined destination. Our proposed DRL method computes a local cost map that helps distinguish which path will grant the maximal covertness while maintaining a low cost trajectory using an elevation map generated from 3D point cloud data, the robot's pose, and directed goal information. CoverNav helps robot agents to learn the low elevation terrain using a reward function while penalizing it proportionately when it experiences high elevation. If an observer is spotted, CoverNav enables the robot to select natural obstacles (e.g., rocks, houses, disabled vehicles, trees, etc.) and use them as shelters to hide behind. We evaluate CoverNav using the Unity simulation environment and show that it guarantees dynamically feasible velocities in the terrain when fed with an elevation map generated by another DRL based navigation algorithm. Additionally, we evaluate CoverNav's effectiveness in achieving a maximum goal distance of 12 meters and its success rate in different elevation scenarios with and without cover objects. We observe competitive performance comparable to state of the art (SOTA) methods without compromising accuracy.