 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasiNav: Asymmetric Cost-Aware Navigation Planning with Constrained Quasimetric Reinforcement Learning
Oct 22, 2024Autonomous navigation in unstructured outdoor environments is inherently challenging due to the presence of asymmetric traversal costs, such as varying energy expenditures for uphill versus downhill movement. Traditional reinforcement learning methods often assume symmetric costs, which can lead to suboptimal navigation paths and increased safety risks in real-world scenarios. In this paper, we introduce QuasiNav, a novel reinforcement learning framework that integrates quasimetric embeddings to explicitly model asymmetric costs and guide efficient, safe navigation. QuasiNav formulates the navigation problem as a constrained Markov decision process (CMDP) and employs quasimetric embeddings to capture directionally dependent costs, allowing for a more accurate representation of the terrain. This approach is combined with adaptive constraint tightening within a constrained policy optimization framework to dynamically enforce safety constraints during learning. We validate QuasiNav across three challenging navigation scenarios-undulating terrains, asymmetric hill traversal, and directionally dependent terrain traversal-demonstrating its effectiveness in both simulated and real-world environments. Experimental results show that QuasiNav significantly outperforms conventional methods, achieving higher success rates, improved energy efficiency, and better adherence to safety constraints.
Inferring and Learning Multi-Robot Policies by Observing an Expert
Sep 17, 2019
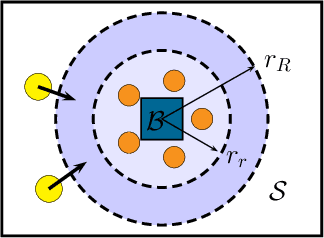
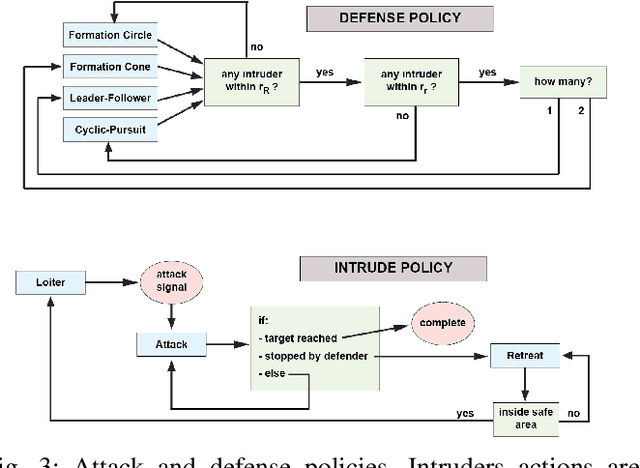

In this paper we present a technique for learning how to solve a multi-robot mission that requires interaction with an external environment by repeatedly observing an expert system executing the same mission. We define the expert system as a team of robots equipped with a library of controllers, each designed to solve a specific task, supervised by an expert policy that appropriately selects controllers based on the states of robots and environment. The objective is for an un-trained team of robots equipped with the same library of controllers, but agnostic to the expert policy, to execute the mission, with performances comparable to those of the expert system. From observations of the expert system, the Interactive Multiple Model technique is used to estimate individual controllers executed by the expert policy. Then, the history of estimated controllers and environmental state is used to learn a policy for the un-trained robots. Considering a perimeter protection scenario on a team of simulated differential-drive robots, we show that the learned policy endows the un-trained team with performances comparable to those of the expert system.