 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Monitoring in Heterogeneous Multi-robot Systems through Network Reconfiguration
Aug 04, 2020



We propose a framework for resilience in a networked heterogeneous multi-robot team subject to resource failures. Each robot in the team is equipped with resources that it shares with its neighbors. Additionally, each robot in the team executes a task, whose performance depends on the resources to which it has access. When a resource on a particular robot becomes unavailable (\eg a camera ceases to function), the team optimally reconfigures its communication network so that the robots affected by the failure can continue their tasks. We focus on a monitoring task, where robots individually estimate the state of an exogenous process. We encode the end-to-end effect of a robot's resource loss on the monitoring performance of the team by defining a new stronger notion of observability -- \textit{one-hop observability}. By abstracting the impact that {low-level} individual resources have on the task performance through the notion of one-hop observability, our framework leads to the principled reconfiguration of information flow in the team to effectively replace the lost resource on one robot with information from another, as long as certain conditions are met. Network reconfiguration is converted to the problem of selecting edges to be modified in the system's communication graph after a resource failure has occurred. A controller based on finite-time convergence control barrier functions drives each robot to a spatial location that enables the communication links of the modified graph. We validate the effectiveness of our framework by deploying it on a team of differential-drive robots estimating the position of a group of quadrotors.
Inferring and Learning Multi-Robot Policies by Observing an Expert
Sep 17, 2019
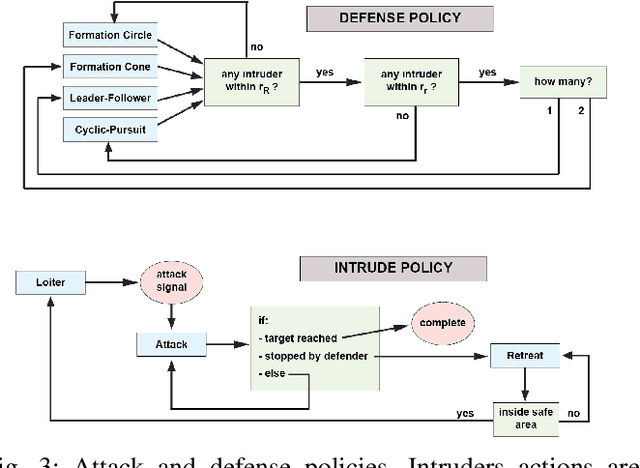

In this paper we present a technique for learning how to solve a multi-robot mission that requires interaction with an external environment by repeatedly observing an expert system executing the same mission. We define the expert system as a team of robots equipped with a library of controllers, each designed to solve a specific task, supervised by an expert policy that appropriately selects controllers based on the states of robots and environment. The objective is for an un-trained team of robots equipped with the same library of controllers, but agnostic to the expert policy, to execute the mission, with performances comparable to those of the expert system. From observations of the expert system, the Interactive Multiple Model technique is used to estimate individual controllers executed by the expert policy. Then, the history of estimated controllers and environmental state is used to learn a policy for the un-trained robots. Considering a perimeter protection scenario on a team of simulated differential-drive robots, we show that the learned policy endows the un-trained team with performances comparable to those of the expert system.
A Reinforcement Learning Framework for Sequencing Multi-Robot Behaviors
Sep 13, 2019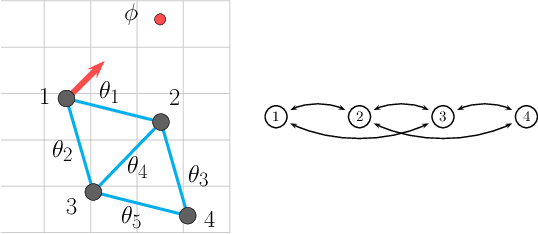

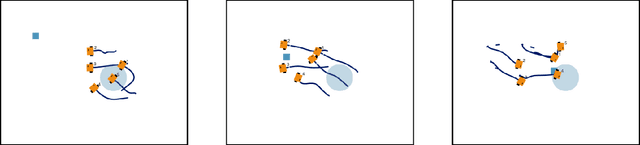
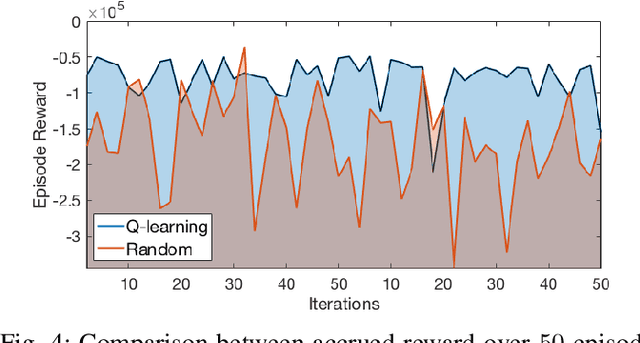
Given a list of behaviors and associated parameterized controllers for solving different individual tasks, we study the problem of selecting an optimal sequence of coordinated behaviors in multi-robot systems for completing a given mission, which could not be handled by any single behavior. In addition, we are interested in the case where partial information of the underlying mission is unknown, therefore, the robots must cooperatively learn this information through their course of actions. Such problem can be formulated as an optimal decision problem in multi-robot systems, however, it is in general intractable due to modeling imperfections and the curse of dimensionality of the decision variables. To circumvent these issues, we first consider an alternate formulation of the original problem through introducing a sequence of behaviors' switching times. Our main contribution is then to propose a novel reinforcement learning based method, that combines Q-learning and online gradient descent, for solving this reformulated problem. In particular, the optimal sequence of the robots' behaviors is found by using Q-learning while the optimal parameters of the associated controllers are obtained through an online gradient descent method. Finally, to illustrate the effectiveness of our proposed method we implement it on a team of differential-drive robots for solving two different missions, namely, convoy protection and object manipulation.
A Sequential Composition Framework for Coordinating Multi-Robot Behaviors
Jul 17, 2019


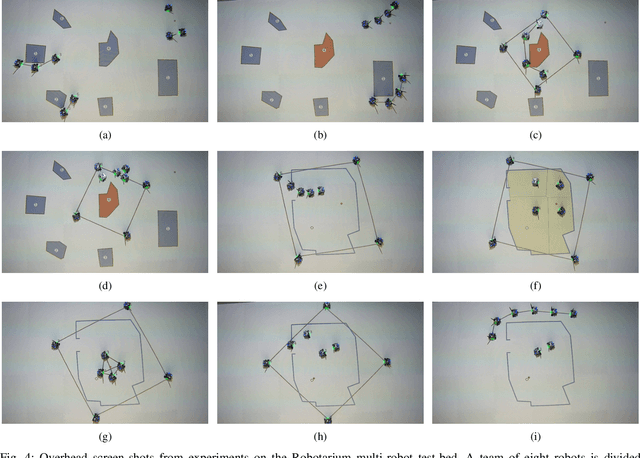
A number of coordinated behaviors have been proposed for achieving specific tasks for multi-robot systems. However, since most applications require more than one such behavior, one needs to be able to compose together sequences of behaviors while respecting local information flow constraints. Specifically, when the inter-agent communication depends on inter-robot distances, these constraints translate into particular configurations that must be reached in finite time in order for the system to be able to transition between the behaviors. To this end, we develop a framework based on finite-time convergence control barrier functions that drives the robots to the required configurations. In order to demonstrate the proposed framework, we consider a scenario where a team of eight planar robots explore an urban environment in order to localize and rescue a subject. The results are presented in the form of a case study, which is implemented on a multi-agent robotic test-bed.
Composition of Safety Constraints With Applications to Decentralized Fixed-Wing Collision Avoidance
Jun 10, 2019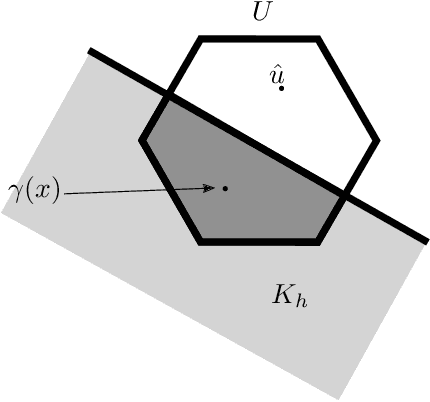


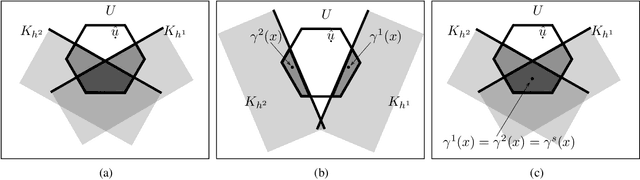
In this paper we discuss how to construct a barrier certificate for a control affine system subject to actuator constraints and motivate this discussion by examining collision avoidance for fixed-wing unmanned aerial vehicles (UAVs). In particular, the theoretical development in this paper is used to create a barrier certificate that ensures that two UAVs will not collide for all future times assuming the vehicles start in a safe starting configuration. We then extend this development by discussing how to ensure that multiple safety constraints are simultaneously satisfied in a decentralized manner (e.g., ensure robot distances are above some threshold for all pairwise combinations of UAVs for all future times) while ensuring output actuator commands are within specified limits. We validate the theoretical developments of this paper in the simulator SCRIMMAGE with a simulation of 20 UAVs that maintain safe distances from each other even though their nominal paths would otherwise cause a collision.
Voluntary Retreat for Decentralized Interference Reduction in Robot Swarms
Mar 10, 2019
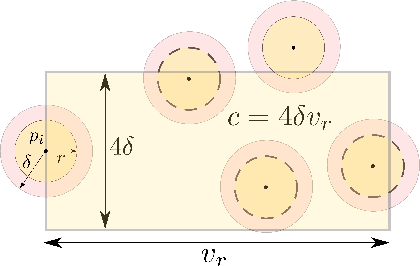

In densely-packed robot swarms operating in confined regions, spatial interference -- which manifests itself as a competition for physical space -- forces robots to spend more time navigating around each other rather than performing the primary task. This paper develops a decentralized algorithm that enables individual robots to decide whether to stay in the region and contribute to the overall mission, or vacate the region so as to reduce the negative effects that interference has on the overall efficiency of the swarm. We develop this algorithm in the context of a distributed collection task, where a team of robots collect and deposit objects from one set of locations to another in a given region. Robots do not communicate and use only binary information regarding the presence of other robots around them to make the decision to stay or retreat. We illustrate the efficacy of the algorithm with experiments on a team of real robots.
Fault Tolerant Control for Networked Mobile Robots
Sep 29, 2018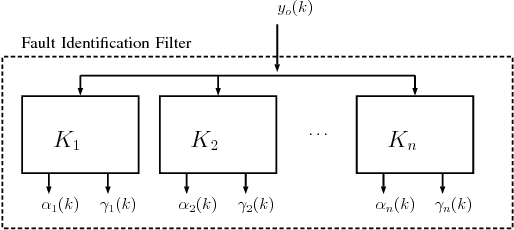



Teams of networked autonomous agents have been used in a number of applications, such as mobile sensor networks and intelligent transportation systems. However, in such systems, the effect of faults and errors in one or more of the sub-systems can easily spread throughout the network, quickly degrading the performance of the entire system. In consensus-driven dynamics, the effects of faults are particularly relevant because of the presence of unconstrained rigid modes in the transfer function of the system. Here, we propose a two-stage technique for the identification and accommodation of a biased-measurements agent, in a network of mobile robots with time invariant interaction topology. We assume these interactions to only take place in the form of relative position measurements. A fault identification filter deployed on a single observer agent is used to estimate a single fault occurring anywhere in the network. Once the fault is detected, an optimal leader-based accommodation strategy is initiated. Results are presented by means of numerical simulations and robot experiments.