 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling and Optimizing the Provisioning of Exhaustible Capabilities for Simultaneous Task Allocation and Scheduling
Feb 14, 2026Deploying heterogeneous robot teams to accomplish multiple tasks over extended time horizons presents significant computational challenges for task allocation and planning. In this paper, we present a comprehensive, time-extended, offline heterogeneous multi-robot task allocation framework, TRAITS, which we believe to be the first that can cope with the provisioning of exhaustible traits under battery and temporal constraints. Specifically, we introduce a nonlinear programming-based trait distribution module that can optimize the trait-provisioning rate of coalitions to yield feasible and time-efficient solutions. TRAITS provides a more accurate feasibility assessment and estimation of task execution times and makespan by leveraging trait-provisioning rates while optimizing battery consumption -- an advantage that state-of-the-art frameworks lack. We evaluate TRAITS against two state-of-the-art frameworks, with results demonstrating its advantage in satisfying complex trait and battery requirements while remaining computationally tractable.
Going with the Flow: Koopman Behavioral Models as Implicit Planners for Visuo-Motor Dexterity
Feb 07, 2026There has been rapid and dramatic progress in robots' ability to learn complex visuo-motor manipulation skills from demonstrations, thanks in part to expressive policy classes that employ diffusion- and transformer-based backbones. However, these design choices require significant data and computational resources and remain far from reliable, particularly within the context of multi-fingered dexterous manipulation. Fundamentally, they model skills as reactive mappings and rely on fixed-horizon action chunking to mitigate jitter, creating a rigid trade-off between temporal coherence and reactivity. In this work, we introduce Unified Behavioral Models (UBMs), a framework that learns to represent dexterous skills as coupled dynamical systems that capture how visual features of the environment (visual flow) and proprioceptive states of the robot (action flow) co-evolve. By capturing such behavioral dynamics, UBMs can ensure temporal coherence by construction rather than by heuristic averaging. To operationalize these models, we propose Koopman-UBM, a first instantiation of UBMs that leverages Koopman Operator theory to effectively learn a unified representation in which the joint flow of latent visual and proprioceptive features is governed by a structured linear system. We demonstrate that Koopman-UBM can be viewed as an implicit planner: given an initial condition, it analytically computes the desired robot behavior while simultaneously ''imagining'' the resulting flow of visual features over the entire skill horizon. To enable reactivity and adaptation, we introduce an online replanning strategy in which the model acts as its own runtime monitor that automatically triggers replanning when predicted and observed visual flow diverge beyond a threshold. Across seven simulated tasks and two real-world tasks, we demonstrate that K-UBM matches or exceeds the performance of state-of-the-art baselines, while offering considerably faster inference, smooth execution, robustness to occlusions, and flexible replanning.
Learning and Optimizing the Efficacy of Spatio-Temporal Task Allocation under Temporal and Resource Constraints
Jan 05, 2026Complex multi-robot missions often require heterogeneous teams to jointly optimize task allocation, scheduling, and path planning to improve team performance under strict constraints. We formalize these complexities into a new class of problems, dubbed Spatio-Temporal Efficacy-optimized Allocation for Multi-robot systems (STEAM). STEAM builds upon trait-based frameworks that model robots using their capabilities (e.g., payload and speed), but goes beyond the typical binary success-failure model by explicitly modeling the efficacy of allocations as trait-efficacy maps. These maps encode how the aggregated capabilities assigned to a task determine performance. Further, STEAM accommodates spatio-temporal constraints, including a user-specified time budget (i.e., maximum makespan). To solve STEAM problems, we contribute a novel algorithm named Efficacy-optimized Incremental Task Allocation Graph Search (E-ITAGS) that simultaneously optimizes task performance and respects time budgets by interleaving task allocation, scheduling, and path planning. Motivated by the fact that trait-efficacy maps are difficult, if not impossible, to specify, E-ITAGS efficiently learns them using a realizability-aware active learning module. Our approach is realizability-aware since it explicitly accounts for the fact that not all combinations of traits are realizable by the robots available during learning. Further, we derive experimentally-validated bounds on E-ITAGS' suboptimality with respect to efficacy. Detailed numerical simulations and experiments using an emergency response domain demonstrate that E-ITAGS generates allocations of higher efficacy compared to baselines, while respecting resource and spatio-temporal constraints. We also show that our active learning approach is sample efficient and establishes a principled tradeoff between data and computational efficiency.
JaxRobotarium: Training and Deploying Multi-Robot Policies in 10 Minutes
May 10, 2025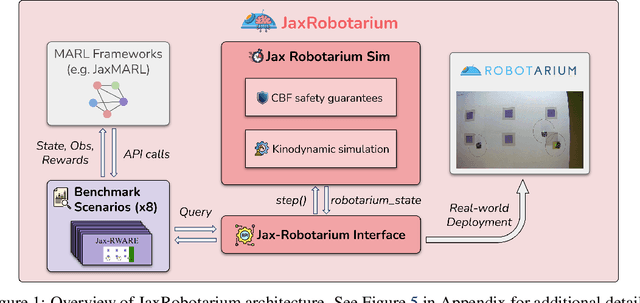
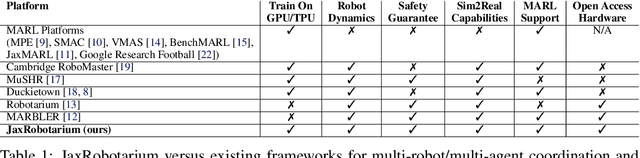
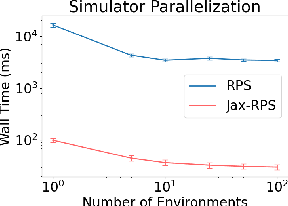

Multi-agent reinforcement learning (MARL) has emerged as a promising solution for learning complex and scalable coordination behaviors in multi-robot systems. However, established MARL platforms (e.g., SMAC and MPE) lack robotics relevance and hardware deployment, leaving multi-robot learning researchers to develop bespoke environments and hardware testbeds dedicated to the development and evaluation of their individual contributions. The Multi-Agent RL Benchmark and Learning Environment for the Robotarium (MARBLER) is an exciting recent step in providing a standardized robotics-relevant platform for MARL, by bridging the Robotarium testbed with existing MARL software infrastructure. However, MARBLER lacks support for parallelization and GPU/TPU execution, making the platform prohibitively slow compared to modern MARL environments and hindering adoption. We contribute JaxRobotarium, a Jax-powered end-to-end simulation, learning, deployment, and benchmarking platform for the Robotarium. JaxRobotarium enables rapid training and deployment of multi-robot reinforcement learning (MRRL) policies with realistic robot dynamics and safety constraints, supporting both parallelization and hardware acceleration. Our generalizable learning interface provides an easy-to-use integration with SOTA MARL libraries (e.g., JaxMARL). In addition, JaxRobotarium includes eight standardized coordination scenarios, including four novel scenarios that bring established MARL benchmark tasks (e.g., RWARE and Level-Based Foraging) to a realistic robotics setting. We demonstrate that JaxRobotarium retains high simulation fidelity while achieving dramatic speedups over baseline (20x in training and 150x in simulation), and provides an open-access sim-to-real evaluation pipeline through the Robotarium testbed, accelerating and democratizing access to multi-robot learning research and evaluation.
Learning Flexible Heterogeneous Coordination with Capability-Aware Shared Hypernetworks
Jan 10, 2025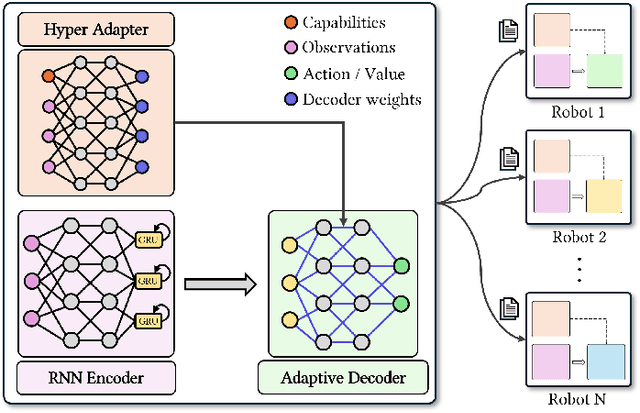
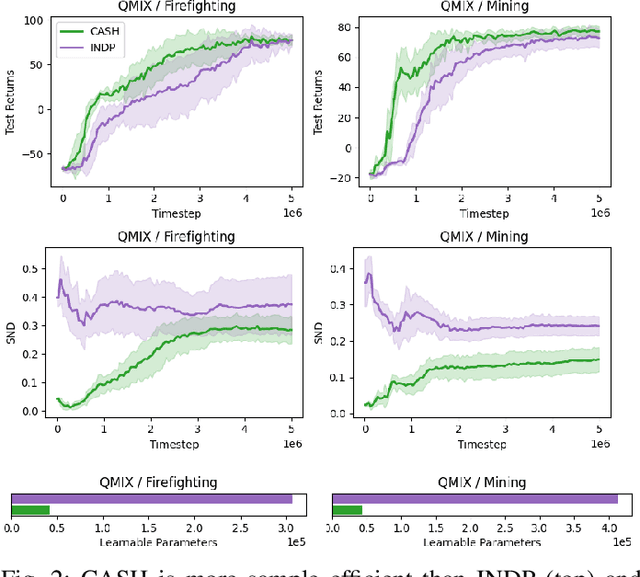
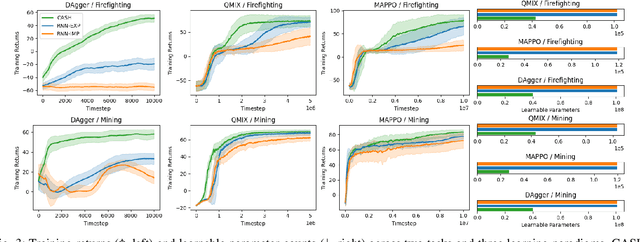
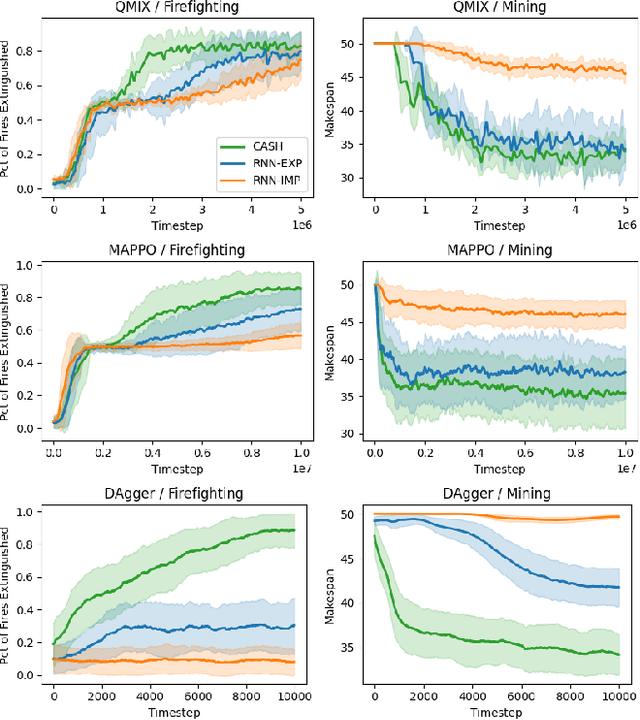
Cooperative heterogeneous multi-agent tasks require agents to effectively coordinate their behaviors while accounting for their relative capabilities. Learning-based solutions to this challenge span between two extremes: i) shared-parameter methods, which encode diverse behaviors within a single architecture by assigning an ID to each agent, and are sample-efficient but result in limited behavioral diversity; ii) independent methods, which learn a separate policy for each agent, and show greater behavioral diversity but lack sample-efficiency. Prior work has also explored selective parameter-sharing, allowing for a compromise between diversity and efficiency. None of these approaches, however, effectively generalize to unseen agents or teams. We present Capability-Aware Shared Hypernetworks (CASH), a novel architecture for heterogeneous multi-agent coordination that generates sufficient diversity while maintaining sample-efficiency via soft parameter-sharing hypernetworks. Intuitively, CASH allows the team to learn common strategies using a shared encoder, which are then adapted according to the team's individual and collective capabilities with a hypernetwork, allowing for zero-shot generalization to unseen teams and agents. We present experiments across two heterogeneous coordination tasks and three standard learning paradigms (imitation learning, on- and off-policy reinforcement learning). CASH is able to outperform baseline architectures in success rate and sample efficiency when evaluated on unseen teams and agents despite using less than half of the learnable parameters.
On the Surprising Effectiveness of Spectrum Clipping in Learning Stable Linear Dynamics
Dec 03, 2024



When learning stable linear dynamical systems from data, three important properties are desirable: i) predictive accuracy, ii) provable stability, and iii) computational efficiency. Unconstrained minimization of reconstruction errors leads to high accuracy and efficiency but cannot guarantee stability. Existing methods to remedy this focus on enforcing stability while also ensuring accuracy, but do so only at the cost of increased computation. In this work, we investigate if a straightforward approach can simultaneously offer all three desiderata of learning stable linear systems. Specifically, we consider a post-hoc approach that manipulates the spectrum of the learned system matrix after it is learned in an unconstrained fashion. We call this approach spectrum clipping (SC) as it involves eigen decomposition and subsequent reconstruction of the system matrix after clipping all of its eigenvalues that are larger than one to one (without altering the eigenvectors). Through detailed experiments involving two different applications and publicly available benchmark datasets, we demonstrate that this simple technique can simultaneously learn highly accurate linear systems that are provably stable. Notably, we demonstrate that SC can achieve similar or better performance than strong baselines while being orders-of-magnitude faster. We also show that SC can be readily combined with Koopman operators to learn stable nonlinear dynamics, such as those underlying complex dexterous manipulation skills involving multi-fingered robotic hands. Our codes and dataset can be found at https://github.com/GT-STAR-Lab/spec_clip.
AsymDex: Leveraging Asymmetry and Relative Motion in Learning Bimanual Dexterity
Nov 20, 2024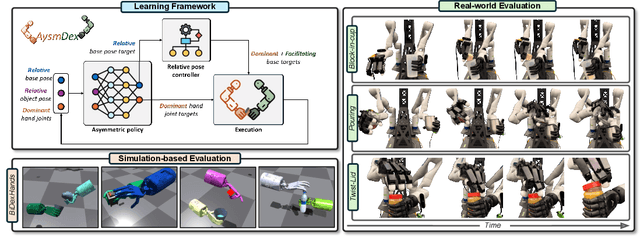


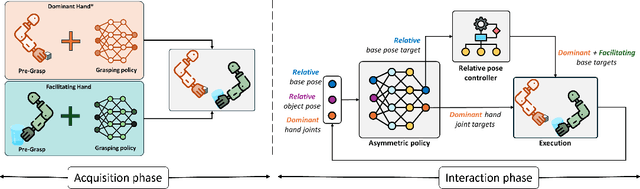
We present Asymmetric Dexterity (AsymDex), a novel reinforcement learning (RL) framework that can efficiently learn asymmetric bimanual skills for multi-fingered hands without relying on demonstrations, which can be cumbersome to collect. Two crucial ingredients enable AsymDex to reduce the observation and action space dimensions and improve sample efficiency. First, AsymDex leverages the natural asymmetry found in human bimanual manipulation and assigns specific and interdependent roles to each hand: a facilitating hand that moves and reorients the object, and a dominant hand that performs complex manipulations on said object. Second, AsymDex defines and operates over relative observation and action spaces, facilitating responsive coordination between the two hands. Further, AsymDex can be easily integrated with recent advances in grasp learning to handle both the object acquisition phase and the interaction phase of bimanual dexterity. Unlike existing RL-based methods for bimanual dexterity, which are tailored to a specific task, AsymDex can be used to learn a wide variety of bimanual tasks that exhibit asymmetry. Detailed experiments on four simulated asymmetric bimanual dexterous manipulation tasks reveal that AsymDex consistently outperforms strong baselines that challenge its design choices, in terms of success rate and sample efficiency. The project website is at https://sites.google.com/view/asymdex-2024/.
KOROL: Learning Visualizable Object Feature with Koopman Operator Rollout for Manipulation
Jun 29, 2024Learning dexterous manipulation skills presents significant challenges due to complex nonlinear dynamics that underlie the interactions between objects and multi-fingered hands. Koopman operators have emerged as a robust method for modeling such nonlinear dynamics within a linear framework. However, current methods rely on runtime access to ground-truth (GT) object states, making them unsuitable for vision-based practical applications. Unlike image-to-action policies that implicitly learn visual features for control, we use a dynamics model, specifically the Koopman operator, to learn visually interpretable object features critical for robotic manipulation within a scene. We construct a Koopman operator using object features predicted by a feature extractor and utilize it to auto-regressively advance system states. We train the feature extractor to embed scene information into object features, thereby enabling the accurate propagation of robot trajectories. We evaluate our approach on simulated and real-world robot tasks, with results showing that it outperformed the model-based imitation learning NDP by 1.08$\times$ and the image-to-action Diffusion Policy by 1.16$\times$. The results suggest that our method maintains task success rates with learned features and extends applicability to real-world manipulation without GT object states.
Learning Prehensile Dexterity by Imitating and Emulating State-only Observations
Apr 12, 2024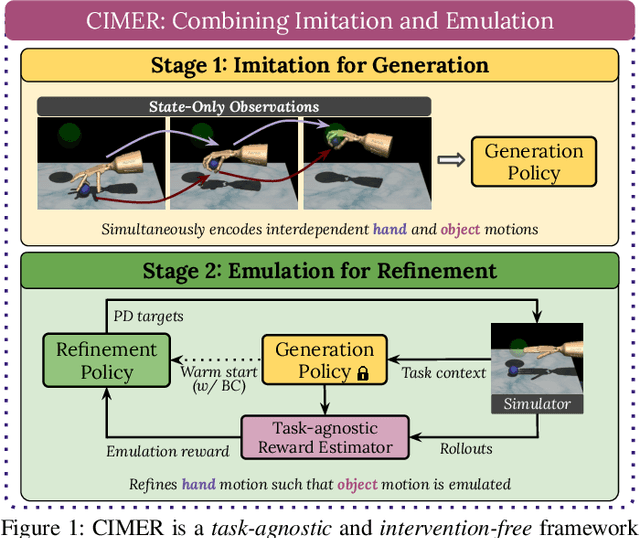
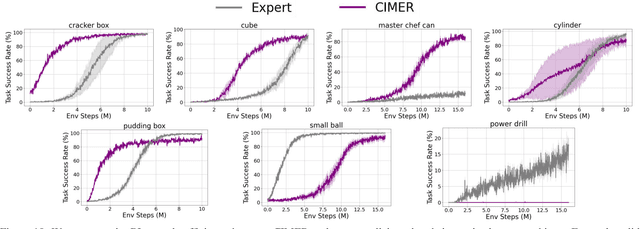
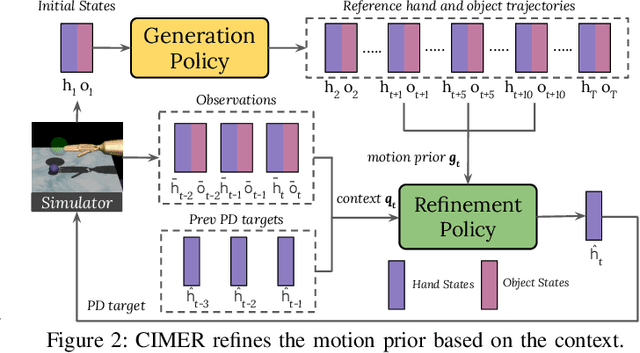
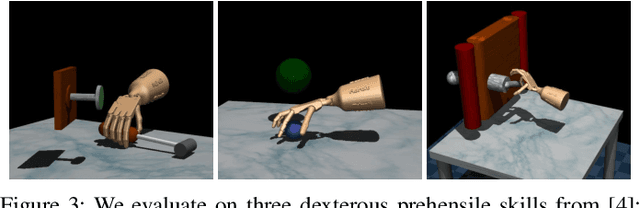
When human acquire physical skills (e.g., tennis) from experts, we tend to first learn from merely observing the expert. But this is often insufficient. We then engage in practice, where we try to emulate the expert and ensure that our actions produce similar effects on our environment. Inspired by this observation, we introduce Combining IMitation and Emulation for Motion Refinement (CIMER) -- a two-stage framework to learn dexterous prehensile manipulation skills from state-only observations. CIMER's first stage involves imitation: simultaneously encode the complex interdependent motions of the robot hand and the object in a structured dynamical system. This results in a reactive motion generation policy that provides a reasonable motion prior, but lacks the ability to reason about contact effects due to the lack of action labels. The second stage involves emulation: learn a motion refinement policy via reinforcement that adjusts the robot hand's motion prior such that the desired object motion is reenacted. CIMER is both task-agnostic (no task-specific reward design or shaping) and intervention-free (no additional teleoperated or labeled demonstrations). Detailed experiments with prehensile dexterity reveal that i) imitation alone is insufficient, but adding emulation drastically improves performance, ii) CIMER outperforms existing methods in terms of sample efficiency and the ability to generate realistic and stable motions, iii) CIMER can either zero-shot generalize or learn to adapt to novel objects from the YCB dataset, even outperforming expert policies trained with action labels in most cases. Source code and videos are available at https://sites.google.com/view/cimer-2024/.
Generalization of Heterogeneous Multi-Robot Policies via Awareness and Communication of Capabilities
Jan 23, 2024Recent advances in multi-agent reinforcement learning (MARL) are enabling impressive coordination in heterogeneous multi-robot teams. However, existing approaches often overlook the challenge of generalizing learned policies to teams of new compositions, sizes, and robots. While such generalization might not be important in teams of virtual agents that can retrain policies on-demand, it is pivotal in multi-robot systems that are deployed in the real-world and must readily adapt to inevitable changes. As such, multi-robot policies must remain robust to team changes -- an ability we call adaptive teaming. In this work, we investigate if awareness and communication of robot capabilities can provide such generalization by conducting detailed experiments involving an established multi-robot test bed. We demonstrate that shared decentralized policies, that enable robots to be both aware of and communicate their capabilities, can achieve adaptive teaming by implicitly capturing the fundamental relationship between collective capabilities and effective coordination. Videos of trained policies can be viewed at: https://sites.google.com/view/cap-comm