 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuad-LCD: Layered Control Decomposition Enables Actuator-Feasible Quadrotor Trajectory Planning
May 15, 2025In this work, we specialize contributions from prior work on data-driven trajectory generation for a quadrotor system with motor saturation constraints. When motors saturate in quadrotor systems, there is an ``uncontrolled drift" of the vehicle that results in a crash. To tackle saturation, we apply a control decomposition and learn a tracking penalty from simulation data consisting of low, medium and high-cost reference trajectories. Our approach reduces crash rates by around $49\%$ compared to baselines on aggressive maneuvers in simulation. On the Crazyflie hardware platform, we demonstrate feasibility through experiments that lead to successful flights. Motivated by the growing interest in data-driven methods to quadrotor planning, we provide open-source lightweight code with an easy-to-use abstraction of hardware platforms.
* 4 pages, 4 figures
ADMM-MCBF-LCA: A Layered Control Architecture for Safe Real-Time Navigation
Mar 04, 2025
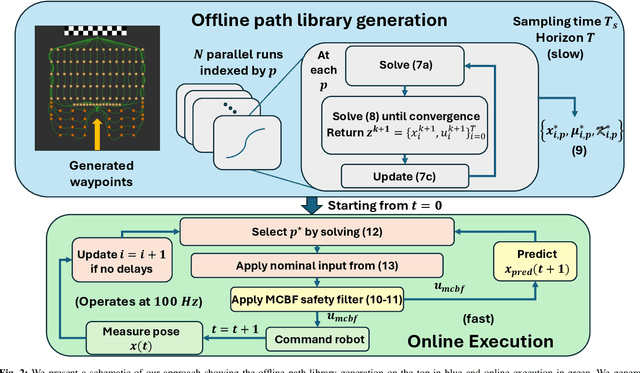
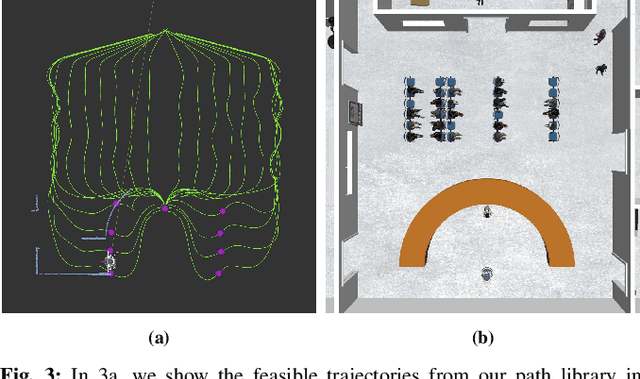
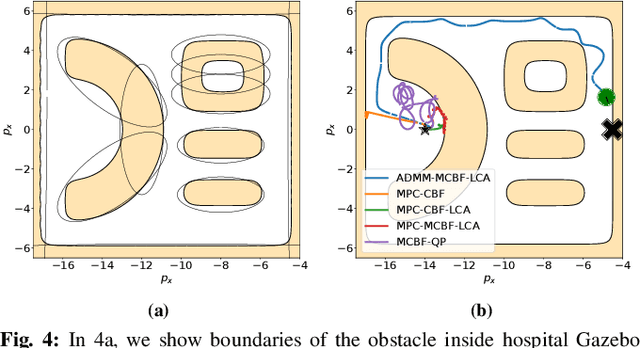
We consider the problem of safe real-time navigation of a robot in a dynamic environment with moving obstacles of arbitrary smooth geometries and input saturation constraints. We assume that the robot detects and models nearby obstacle boundaries with a short-range sensor and that this detection is error-free. This problem presents three main challenges: i) input constraints, ii) safety, and iii) real-time computation. To tackle all three challenges, we present a layered control architecture (LCA) consisting of an offline path library generation layer, and an online path selection and safety layer. To overcome the limitations of reactive methods, our offline path library consists of feasible controllers, feedback gains, and reference trajectories. To handle computational burden and safety, we solve online path selection and generate safe inputs that run at 100 Hz. Through simulations on Gazebo and Fetch hardware in an indoor environment, we evaluate our approach against baselines that are layered, end-to-end, or reactive. Our experiments demonstrate that among all algorithms, only our proposed LCA is able to complete tasks such as reaching a goal, safely. When comparing metrics such as safety, input error, and success rate, we show that our approach generates safe and feasible inputs throughout the robot execution.
Why Change Your Controller When You Can Change Your Planner: Drag-Aware Trajectory Generation for Quadrotor Systems
Jan 10, 2024Motivated by the increasing use of quadrotors for payload delivery, we consider a joint trajectory generation and feedback control design problem for a quadrotor experiencing aerodynamic wrenches. Unmodeled aerodynamic drag forces from carried payloads can lead to catastrophic outcomes. Prior work model aerodynamic effects as residual dynamics or external disturbances in the control problem leading to a reactive policy that could be catastrophic. Moreover, redesigning controllers and tuning control gains on hardware platforms is a laborious effort. In this paper, we argue that adapting the trajectory generation component keeping the controller fixed can improve trajectory tracking for quadrotor systems experiencing drag forces. To achieve this, we formulate a drag-aware planning problem by applying a suitable relaxation to an optimal quadrotor control problem, introducing a tracking cost function which measures the ability of a controller to follow a reference trajectory. This tracking cost function acts as a regularizer in trajectory generation and is learned from data obtained from simulation. Our experiments in both simulation and on the Crazyflie hardware platform show that changing the planner reduces tracking error by as much as 83%. Evaluation on hardware demonstrates that our planned path, as opposed to a baseline, avoids controller saturation and catastrophic outcomes during aggressive maneuvers.
A Data-Driven Approach to Synthesizing Dynamics-Aware Trajectories for Underactuated Robotic Systems
Jul 25, 2023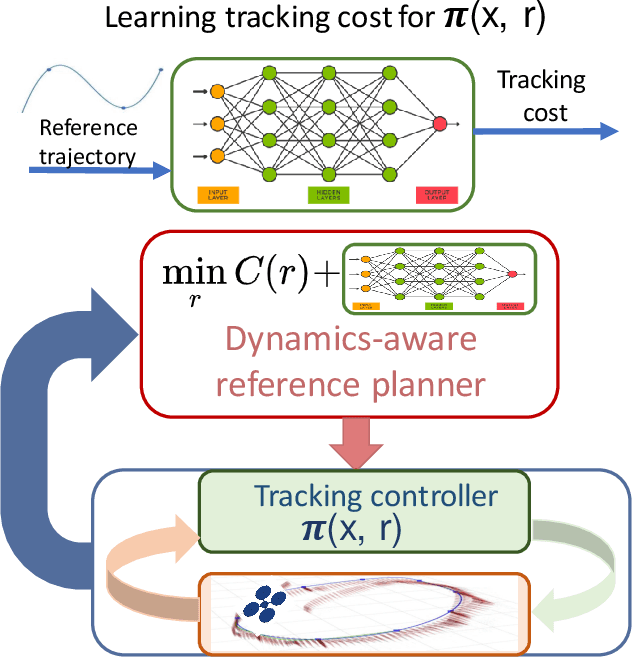
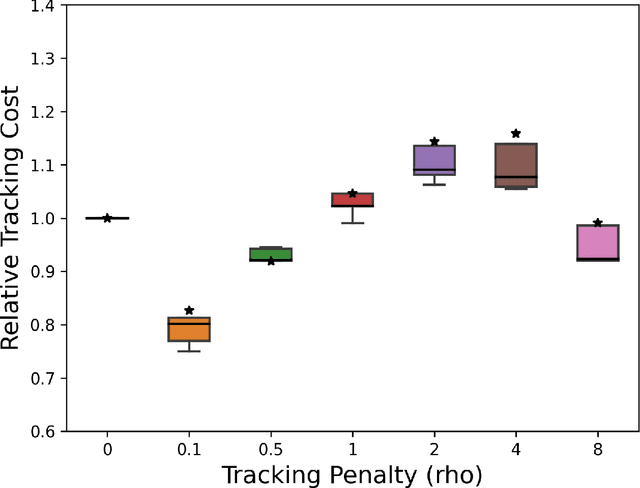
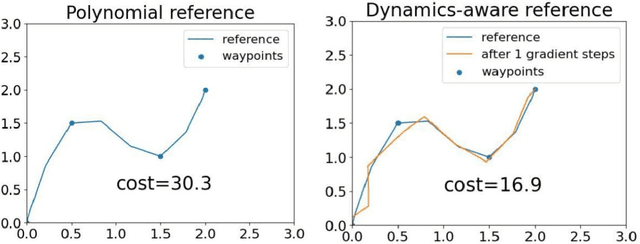
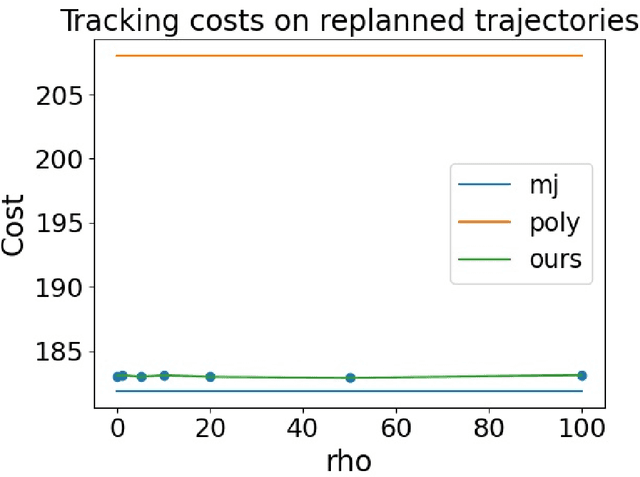
We consider joint trajectory generation and tracking control for under-actuated robotic systems. A common solution is to use a layered control architecture, where the top layer uses a simplified model of system dynamics for trajectory generation, and the low layer ensures approximate tracking of this trajectory via feedback control. While such layered control architectures are standard and work well in practice, selecting the simplified model used for trajectory generation typically relies on engineering intuition and experience. In this paper, we propose an alternative data-driven approach to dynamics-aware trajectory generation. We show that a suitable augmented Lagrangian reformulation of a global nonlinear optimal control problem results in a layered decomposition of the overall problem into trajectory planning and feedback control layers. Crucially, the resulting trajectory optimization is dynamics-aware, in that, it is modified with a tracking penalty regularizer encoding the dynamic feasibility of the generated trajectory. We show that this tracking penalty regularizer can be learned from system rollouts for independently-designed low layer feedback control policies, and instantiate our framework in the context of a unicycle and a quadrotor control problem in simulation. Further, we show that our approach handles the sim-to-real gap through experiments on the quadrotor hardware platform without any additional training. For both the synthetic unicycle example and the quadrotor system, our framework shows significant improvements in both computation time and dynamic feasibility in simulation and hardware experiments.
Concurrent Constrained Optimization of Unknown Rewards for Multi-Robot Task Allocation
May 24, 2023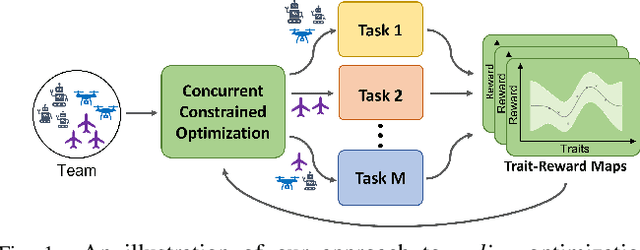
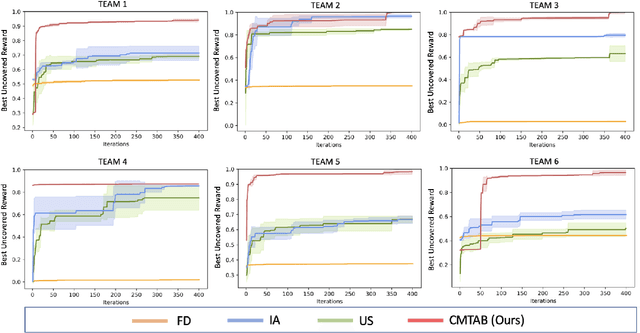
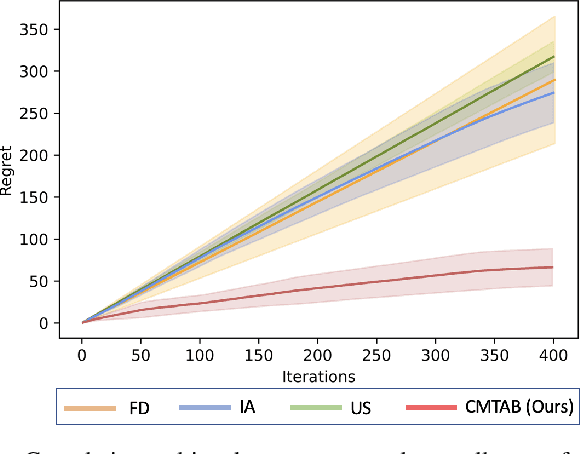
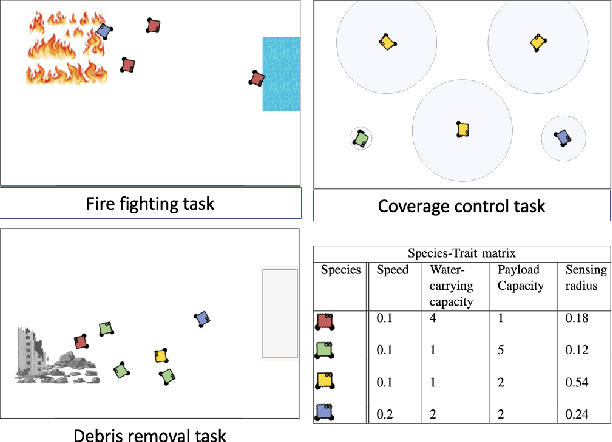
Task allocation can enable effective coordination of multi-robot teams to accomplish tasks that are intractable for individual robots. However, existing approaches to task allocation often assume that task requirements or reward functions are known and explicitly specified by the user. In this work, we consider the challenge of forming effective coalitions for a given heterogeneous multi-robot team when task reward functions are unknown. To this end, we first formulate a new class of problems, dubbed COncurrent Constrained Online optimization of Allocation (COCOA). The COCOA problem requires online optimization of coalitions such that the unknown rewards of all the tasks are simultaneously maximized using a given multi-robot team with constrained resources. To address the COCOA problem, we introduce an online optimization algorithm, named Concurrent Multi-Task Adaptive Bandits (CMTAB), that leverages and builds upon continuum-armed bandit algorithms. Experiments involving detailed numerical simulations and a simulated emergency response task reveal that CMTAB can effectively trade-off exploration and exploitation to simultaneously and efficiently optimize the unknown task rewards while respecting the team's resource constraints.