 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Generalization from Motion Demonstrations to New Tasks
Mar 16, 2026Learning motion policies from expert demonstrations is an essential paradigm in modern robotics. While end-to-end models aim for broad generalization, they require large datasets and computationally heavy inference. Conversely, learning dynamical systems (DS) provides fast, reactive, and provably stable control from very few demonstrations. However, existing DS learning methods typically model isolated tasks and struggle to reuse demonstrations for novel behaviors. In this work, we formalize the problem of combining isolated demonstrations within a shared workspace to enable generalization to unseen tasks. The Gaussian Graph is introduced, which reinterprets spatial components of learned motion primitives as discrete vertices with connections to one another. This formulation allows us to bridge continuous control with discrete graph search. We propose two frameworks leveraging this graph: Stitching, for constructing time-invariant DSs, and Chaining, giving a sequence-based DS for complex motions while retaining convergence guarantees. Simulations and real-robot experiments show that these methods successfully generalize to new tasks where baseline methods fail.
Proactive Local-Minima-Free Robot Navigation: Blending Motion Prediction with Safe Control
Jan 15, 2026This work addresses the challenge of safe and efficient mobile robot navigation in complex dynamic environments with concave moving obstacles. Reactive safe controllers like Control Barrier Functions (CBFs) design obstacle avoidance strategies based only on the current states of the obstacles, risking future collisions. To alleviate this problem, we use Gaussian processes to learn barrier functions online from multimodal motion predictions of obstacles generated by neural networks trained with energy-based learning. The learned barrier functions are then fed into quadratic programs using modulated CBFs (MCBFs), a local-minimum-free version of CBFs, to achieve safe and efficient navigation. The proposed framework makes two key contributions. First, it develops a prediction-to-barrier function online learning pipeline. Second, it introduces an autonomous parameter tuning algorithm that adapts MCBFs to deforming, prediction-based barrier functions. The framework is evaluated in both simulations and real-world experiments, consistently outperforming baselines and demonstrating superior safety and efficiency in crowded dynamic environments.
Symskill: Symbol and Skill Co-Invention for Data-Efficient and Real-Time Long-Horizon Manipulation
Oct 02, 2025Multi-step manipulation in dynamic environments remains challenging. Two major families of methods fail in distinct ways: (i) imitation learning (IL) is reactive but lacks compositional generalization, as monolithic policies do not decide which skill to reuse when scenes change; (ii) classical task-and-motion planning (TAMP) offers compositionality but has prohibitive planning latency, preventing real-time failure recovery. We introduce SymSkill, a unified learning framework that combines the benefits of IL and TAMP, allowing compositional generalization and failure recovery in real-time. Offline, SymSkill jointly learns predicates, operators, and skills directly from unlabeled and unsegmented demonstrations. At execution time, upon specifying a conjunction of one or more learned predicates, SymSkill uses a symbolic planner to compose and reorder learned skills to achieve the symbolic goals, while performing recovery at both the motion and symbolic levels in real time. Coupled with a compliant controller, SymSkill enables safe and uninterrupted execution under human and environmental disturbances. In RoboCasa simulation, SymSkill can execute 12 single-step tasks with 85% success rate. Without additional data, it composes these skills into multi-step plans requiring up to 6 skill recompositions, recovering robustly from execution failures. On a real Franka robot, we demonstrate SymSkill, learning from 5 minutes of unsegmented and unlabeled play data, is capable of performing multiple tasks simply by goal specifications. The source code and additional analysis can be found on https://sites.google.com/view/symskill.
Occupancy-aware Trajectory Planning for Autonomous Valet Parking in Uncertain Dynamic Environments
Sep 11, 2025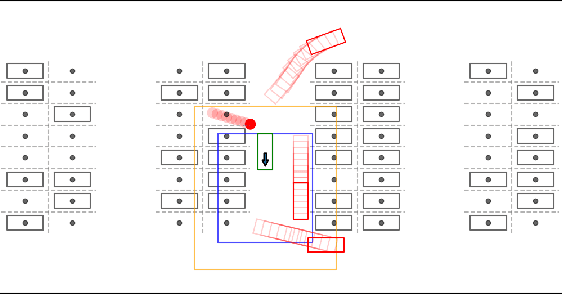
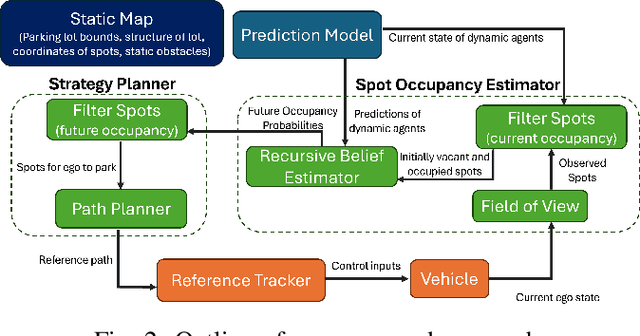
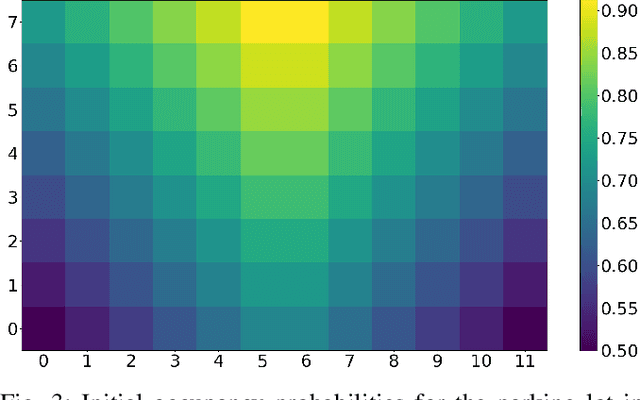
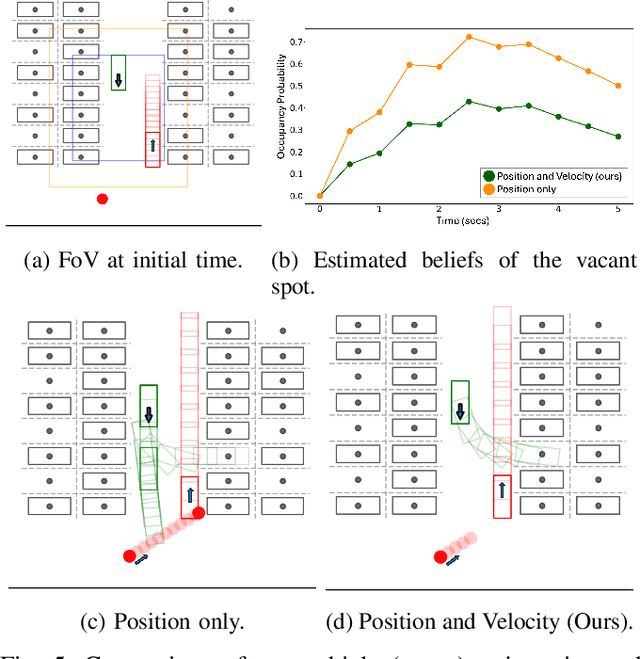
Accurately reasoning about future parking spot availability and integrated planning is critical for enabling safe and efficient autonomous valet parking in dynamic, uncertain environments. Unlike existing methods that rely solely on instantaneous observations or static assumptions, we present an approach that predicts future parking spot occupancy by explicitly distinguishing between initially vacant and occupied spots, and by leveraging the predicted motion of dynamic agents. We introduce a probabilistic spot occupancy estimator that incorporates partial and noisy observations within a limited Field-of-View (FoV) model and accounts for the evolving uncertainty of unobserved regions. Coupled with this, we design a strategy planner that adaptively balances goal-directed parking maneuvers with exploratory navigation based on information gain, and intelligently incorporates wait-and-go behaviors at promising spots. Through randomized simulations emulating large parking lots, we demonstrate that our framework significantly improves parking efficiency, safety margins, and trajectory smoothness compared to existing approaches.
COMETH: Convex Optimization for Multiview Estimation and Tracking of Humans
Aug 28, 2025In the era of Industry 5.0, monitoring human activity is essential for ensuring both ergonomic safety and overall well-being. While multi-camera centralized setups improve pose estimation accuracy, they often suffer from high computational costs and bandwidth requirements, limiting scalability and real-time applicability. Distributing processing across edge devices can reduce network bandwidth and computational load. On the other hand, the constrained resources of edge devices lead to accuracy degradation, and the distribution of computation leads to temporal and spatial inconsistencies. We address this challenge by proposing COMETH (Convex Optimization for Multiview Estimation and Tracking of Humans), a lightweight algorithm for real-time multi-view human pose fusion that relies on three concepts: it integrates kinematic and biomechanical constraints to increase the joint positioning accuracy; it employs convex optimization-based inverse kinematics for spatial fusion; and it implements a state observer to improve temporal consistency. We evaluate COMETH on both public and industrial datasets, where it outperforms state-of-the-art methods in localization, detection, and tracking accuracy. The proposed fusion pipeline enables accurate and scalable human motion tracking, making it well-suited for industrial and safety-critical applications. The code is publicly available at https://github.com/PARCO-LAB/COMETH.
Rapid Mismatch Estimation via Neural Network Informed Variational Inference
Aug 28, 2025With robots increasingly operating in human-centric environments, ensuring soft and safe physical interactions, whether with humans, surroundings, or other machines, is essential. While compliant hardware can facilitate such interactions, this work focuses on impedance controllers that allow torque-controlled robots to safely and passively respond to contact while accurately executing tasks. From inverse dynamics to quadratic programming-based controllers, the effectiveness of these methods relies on accurate dynamics models of the robot and the object it manipulates. Any model mismatch results in task failures and unsafe behaviors. Thus, we introduce Rapid Mismatch Estimation (RME), an adaptive, controller-agnostic, probabilistic framework that estimates end-effector dynamics mismatches online, without relying on external force-torque sensors. From the robot's proprioceptive feedback, a Neural Network Model Mismatch Estimator generates a prior for a Variational Inference solver, which rapidly converges to the unknown parameters while quantifying uncertainty. With a real 7-DoF manipulator driven by a state-of-the-art passive impedance controller, RME adapts to sudden changes in mass and center of mass at the end-effector in $\sim400$ ms, in static and dynamic settings. We demonstrate RME in a collaborative scenario where a human attaches an unknown basket to the robot's end-effector and dynamically adds/removes heavy items, showcasing fast and safe adaptation to changing dynamics during physical interaction without any external sensory system.
RNBF: Real-Time RGB-D Based Neural Barrier Functions for Safe Robotic Navigation
May 04, 2025
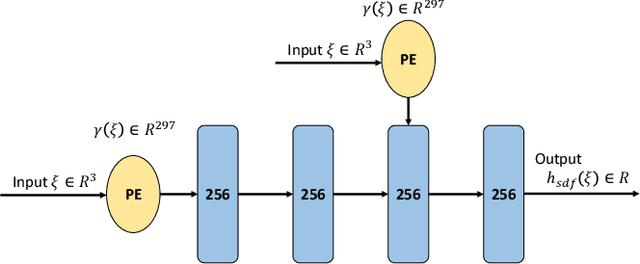
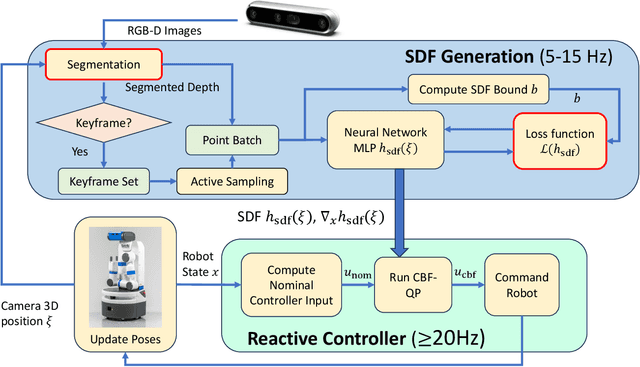
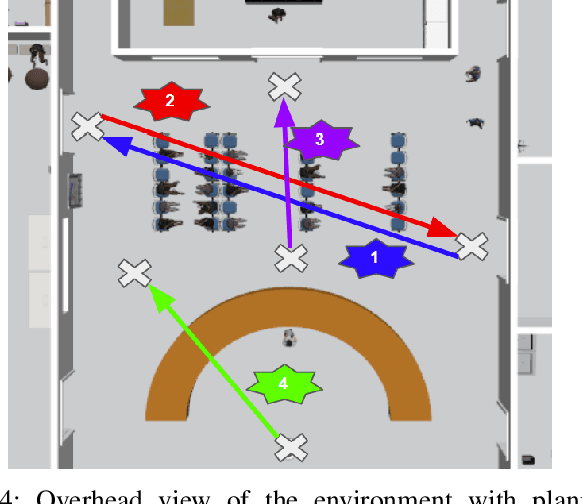
Autonomous safe navigation in unstructured and novel environments poses significant challenges, especially when environment information can only be provided through low-cost vision sensors. Although safe reactive approaches have been proposed to ensure robot safety in complex environments, many base their theory off the assumption that the robot has prior knowledge on obstacle locations and geometries. In this paper, we present a real-time, vision-based framework that constructs continuous, first-order differentiable Signed Distance Fields (SDFs) of unknown environments without any pre-training. Our proposed method ensures full compatibility with established SDF-based reactive controllers. To achieve robust performance under practical sensing conditions, our approach explicitly accounts for noise in affordable RGB-D cameras, refining the neural SDF representation online for smoother geometry and stable gradient estimates. We validate the proposed method in simulation and real-world experiments using a Fetch robot.
Graph-based Path Planning with Dynamic Obstacle Avoidance for Autonomous Parking
Apr 17, 2025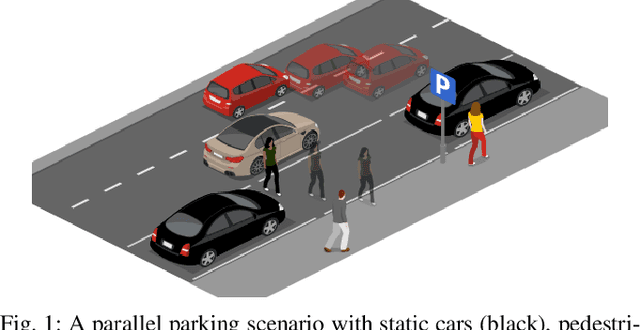
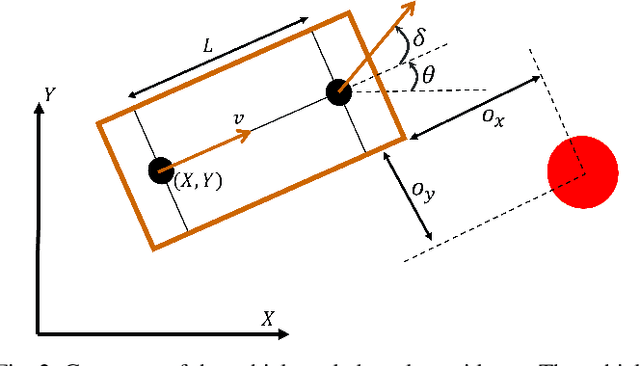
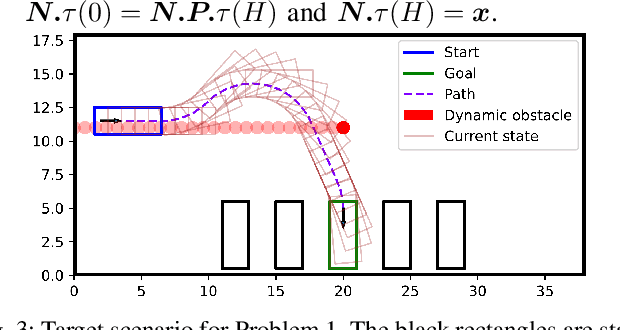
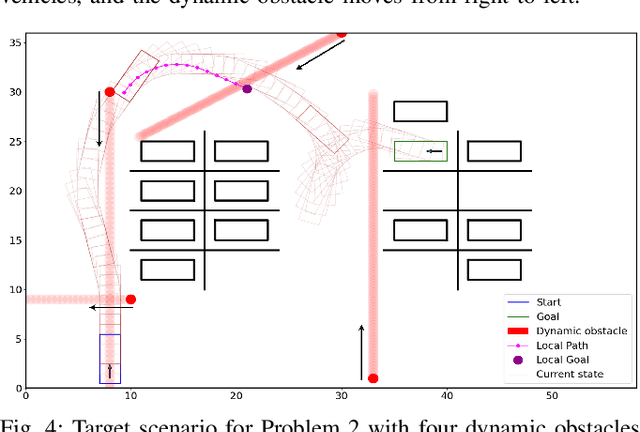
Safe and efficient path planning in parking scenarios presents a significant challenge due to the presence of cluttered environments filled with static and dynamic obstacles. To address this, we propose a novel and computationally efficient planning strategy that seamlessly integrates the predictions of dynamic obstacles into the planning process, ensuring the generation of collision-free paths. Our approach builds upon the conventional Hybrid A star algorithm by introducing a time-indexed variant that explicitly accounts for the predictions of dynamic obstacles during node exploration in the graph, thus enabling dynamic obstacle avoidance. We integrate the time-indexed Hybrid A star algorithm within an online planning framework to compute local paths at each planning step, guided by an adaptively chosen intermediate goal. The proposed method is validated in diverse parking scenarios, including perpendicular, angled, and parallel parking. Through simulations, we showcase our approach's potential in greatly improving the efficiency and safety when compared to the state of the art spline-based planning method for parking situations.
Gradient Field-Based Dynamic Window Approach for Collision Avoidance in Complex Environments
Apr 04, 2025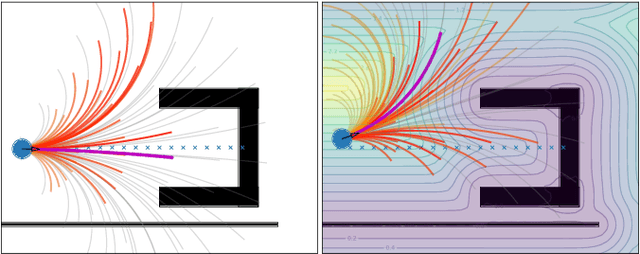
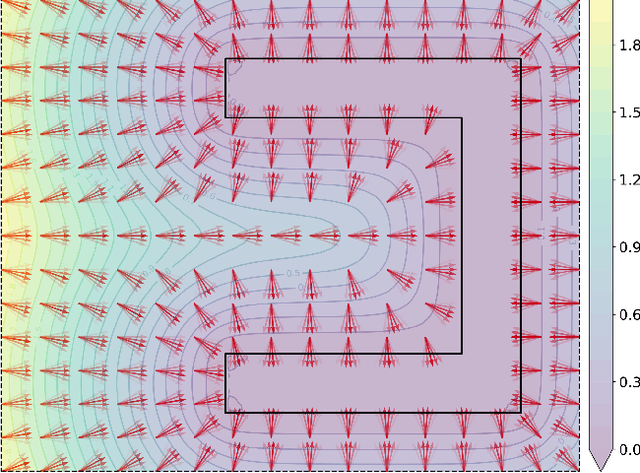
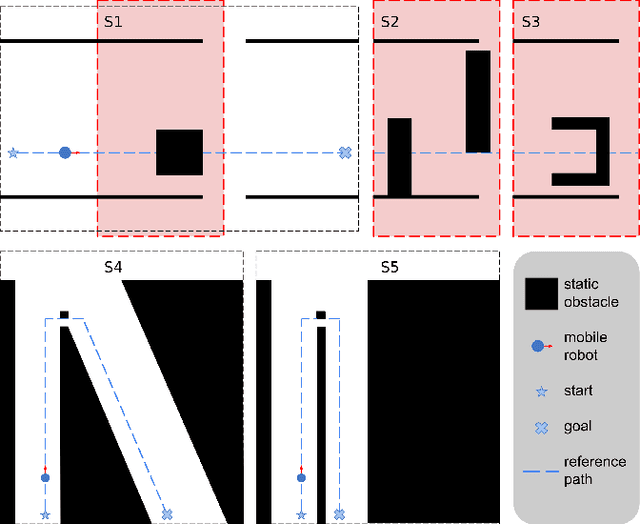
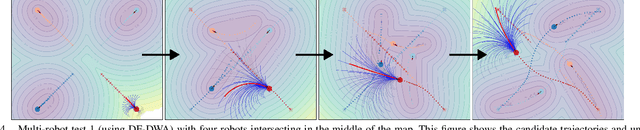
For safe and flexible navigation in multi-robot systems, this paper presents an enhanced and predictive sampling-based trajectory planning approach in complex environments, the Gradient Field-based Dynamic Window Approach (GF-DWA). Building upon the dynamic window approach, the proposed method utilizes gradient information of obstacle distances as a new cost term to anticipate potential collisions. This enhancement enables the robot to improve awareness of obstacles, including those with non-convex shapes. The gradient field is derived from the Gaussian process distance field, which generates both the distance field and gradient field by leveraging Gaussian process regression to model the spatial structure of the environment. Through several obstacle avoidance and fleet collision avoidance scenarios, the proposed GF-DWA is shown to outperform other popular trajectory planning and control methods in terms of safety and flexibility, especially in complex environments with non-convex obstacles.
Elastic Motion Policy: An Adaptive Dynamical System for Robust and Efficient One-Shot Imitation Learning
Mar 11, 2025Behavior cloning (BC) has become a staple imitation learning paradigm in robotics due to its ease of teaching robots complex skills directly from expert demonstrations. However, BC suffers from an inherent generalization issue. To solve this, the status quo solution is to gather more data. Yet, regardless of how much training data is available, out-of-distribution performance is still sub-par, lacks any formal guarantee of convergence and success, and is incapable of allowing and recovering from physical interactions with humans. These are critical flaws when robots are deployed in ever-changing human-centric environments. Thus, we propose Elastic Motion Policy (EMP), a one-shot imitation learning framework that allows robots to adjust their behavior based on the scene change while respecting the task specification. Trained from a single demonstration, EMP follows the dynamical systems paradigm where motion planning and control are governed by first-order differential equations with convergence guarantees. We leverage Laplacian editing in full end-effector space, $\mathbb{R}^3\times SO(3)$, and online convex learning of Lyapunov functions, to adapt EMP online to new contexts, avoiding the need to collect new demonstrations. We extensively validate our framework in real robot experiments, demonstrating its robust and efficient performance in dynamic environments, with obstacle avoidance and multi-step task capabilities. Project Website: https://elastic-motion-policy.github.io/EMP/