 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Task and Behavior: A Two-Stage Reward Curriculum in Reinforcement Learning for Robotics
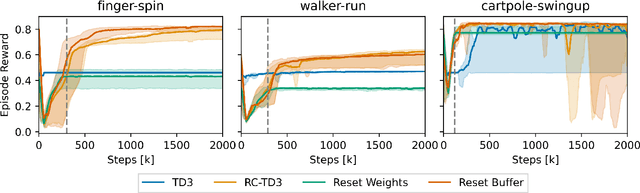
Mar 05, 2026Deep Reinforcement Learning is a promising tool for robotic control, yet practical application is often hindered by the difficulty of designing effective reward functions. Real-world tasks typically require optimizing multiple objectives simultaneously, necessitating precise tuning of their weights to learn a policy with the desired characteristics. To address this, we propose a two-stage reward curriculum where we decouple task-specific objectives from behavioral terms. In our method, we first train the agent on a simplified task-only reward function to ensure effective exploration before introducing the full reward that includes auxiliary behavior-related terms such as energy efficiency. Further, we analyze various transition strategies and demonstrate that reusing samples between phases is critical for training stability. We validate our approach on the DeepMind Control Suite, ManiSkill3, and a mobile robot environment, modified to include auxiliary behavioral objectives. Our method proves to be simple yet effective, substantially outperforming baselines trained directly on the full reward while exhibiting higher robustness to specific reward weightings.
Proactive Local-Minima-Free Robot Navigation: Blending Motion Prediction with Safe Control
Jan 15, 2026This work addresses the challenge of safe and efficient mobile robot navigation in complex dynamic environments with concave moving obstacles. Reactive safe controllers like Control Barrier Functions (CBFs) design obstacle avoidance strategies based only on the current states of the obstacles, risking future collisions. To alleviate this problem, we use Gaussian processes to learn barrier functions online from multimodal motion predictions of obstacles generated by neural networks trained with energy-based learning. The learned barrier functions are then fed into quadratic programs using modulated CBFs (MCBFs), a local-minimum-free version of CBFs, to achieve safe and efficient navigation. The proposed framework makes two key contributions. First, it develops a prediction-to-barrier function online learning pipeline. Second, it introduces an autonomous parameter tuning algorithm that adapts MCBFs to deforming, prediction-based barrier functions. The framework is evaluated in both simulations and real-world experiments, consistently outperforming baselines and demonstrating superior safety and efficiency in crowded dynamic environments.
Infrastructure-based Autonomous Mobile Robots for Internal Logistics -- Challenges and Future Perspectives
Dec 17, 2025



The adoption of Autonomous Mobile Robots (AMRs) for internal logistics is accelerating, with most solutions emphasizing decentralized, onboard intelligence. While AMRs in indoor environments like factories can be supported by infrastructure, involving external sensors and computational resources, such systems remain underexplored in the literature. This paper presents a comprehensive overview of infrastructure-based AMR systems, outlining key opportunities and challenges. To support this, we introduce a reference architecture combining infrastructure-based sensing, on-premise cloud computing, and onboard autonomy. Based on the architecture, we review core technologies for localization, perception, and planning. We demonstrate the approach in a real-world deployment in a heavy-vehicle manufacturing environment and summarize findings from a user experience (UX) evaluation. Our aim is to provide a holistic foundation for future development of scalable, robust, and human-compatible AMR systems in complex industrial environments.
Future-Oriented Navigation: Dynamic Obstacle Avoidance with One-Shot Energy-Based Multimodal Motion Prediction
May 01, 2025This paper proposes an integrated approach for the safe and efficient control of mobile robots in dynamic and uncertain environments. The approach consists of two key steps: one-shot multimodal motion prediction to anticipate motions of dynamic obstacles and model predictive control to incorporate these predictions into the motion planning process. Motion prediction is driven by an energy-based neural network that generates high-resolution, multi-step predictions in a single operation. The prediction outcomes are further utilized to create geometric shapes formulated as mathematical constraints. Instead of treating each dynamic obstacle individually, predicted obstacles are grouped by proximity in an unsupervised way to improve performance and efficiency. The overall collision-free navigation is handled by model predictive control with a specific design for proactive dynamic obstacle avoidance. The proposed approach allows mobile robots to navigate effectively in dynamic environments. Its performance is accessed across various scenarios that represent typical warehouse settings. The results demonstrate that the proposed approach outperforms other existing dynamic obstacle avoidance methods.
Gradient Field-Based Dynamic Window Approach for Collision Avoidance in Complex Environments
Apr 04, 2025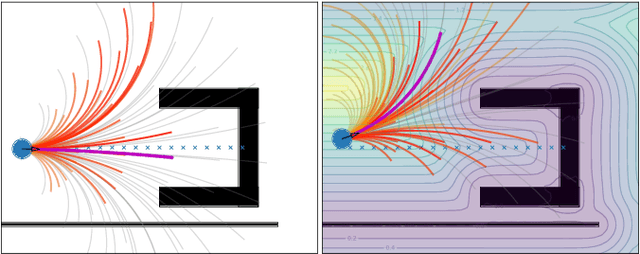
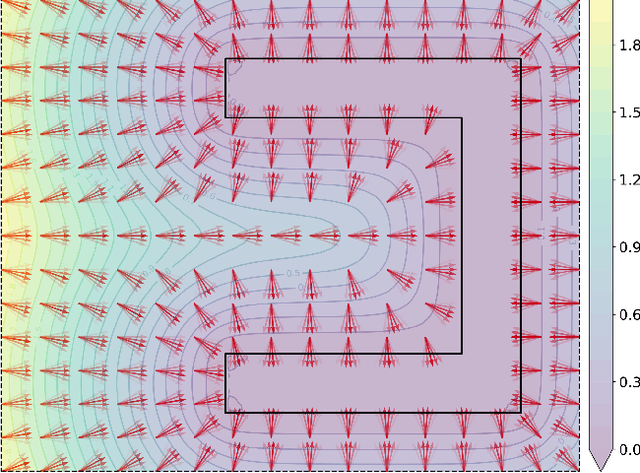
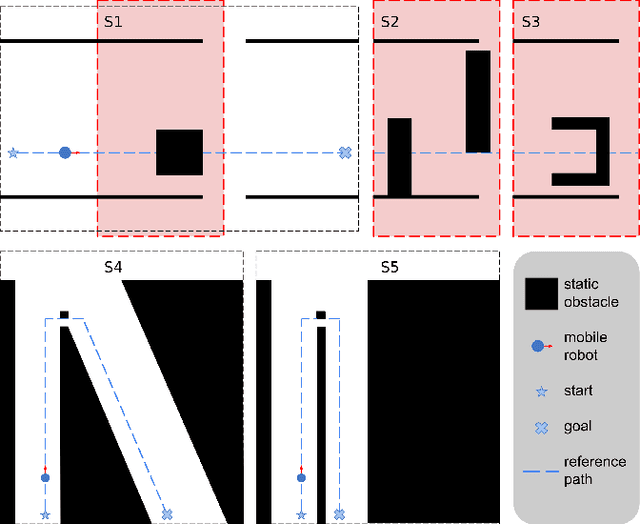
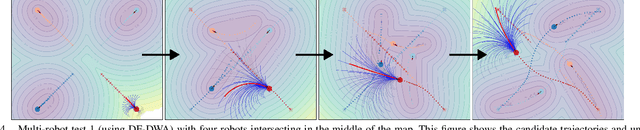
For safe and flexible navigation in multi-robot systems, this paper presents an enhanced and predictive sampling-based trajectory planning approach in complex environments, the Gradient Field-based Dynamic Window Approach (GF-DWA). Building upon the dynamic window approach, the proposed method utilizes gradient information of obstacle distances as a new cost term to anticipate potential collisions. This enhancement enables the robot to improve awareness of obstacles, including those with non-convex shapes. The gradient field is derived from the Gaussian process distance field, which generates both the distance field and gradient field by leveraging Gaussian process regression to model the spatial structure of the environment. Through several obstacle avoidance and fleet collision avoidance scenarios, the proposed GF-DWA is shown to outperform other popular trajectory planning and control methods in terms of safety and flexibility, especially in complex environments with non-convex obstacles.
MVUDA: Unsupervised Domain Adaptation for Multi-view Pedestrian Detection
Dec 05, 2024



We address multi-view pedestrian detection in a setting where labeled data is collected using a multi-camera setup different from the one used for testing. While recent multi-view pedestrian detectors perform well on the camera rig used for training, their performance declines when applied to a different setup. To facilitate seamless deployment across varied camera rigs, we propose an unsupervised domain adaptation (UDA) method that adapts the model to new rigs without requiring additional labeled data. Specifically, we leverage the mean teacher self-training framework with a novel pseudo-labeling technique tailored to multi-view pedestrian detection. This method achieves state-of-the-art performance on multiple benchmarks, including MultiviewX$\rightarrow$Wildtrack. Unlike previous methods, our approach eliminates the need for external labeled monocular datasets, thereby reducing reliance on labeled data. Extensive evaluations demonstrate the effectiveness of our method and validate key design choices. By enabling robust adaptation across camera setups, our work enhances the practicality of multi-view pedestrian detectors and establishes a strong UDA baseline for future research.
Sample-Efficient Curriculum Reinforcement Learning for Complex Reward Functions
Oct 22, 2024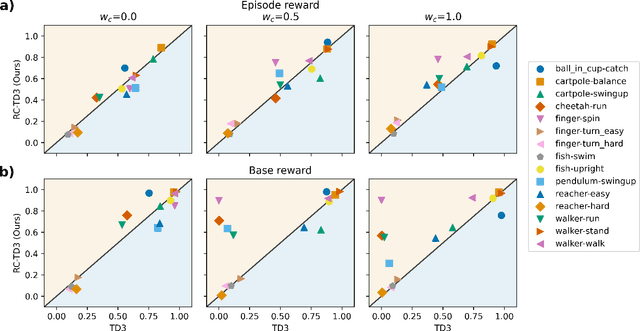
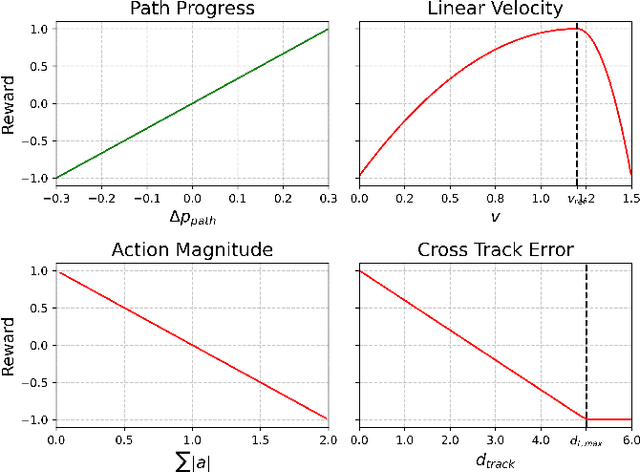
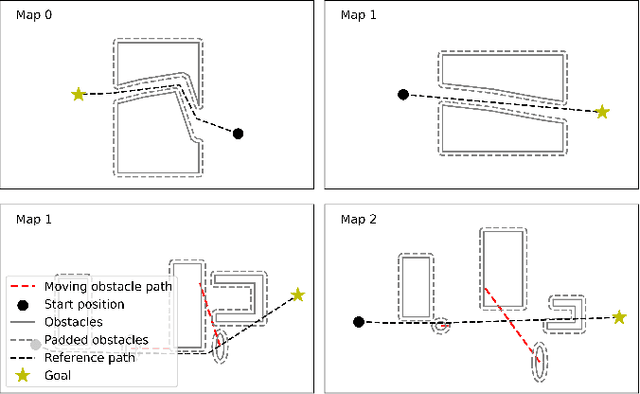
Reinforcement learning (RL) shows promise in control problems, but its practical application is often hindered by the complexity arising from intricate reward functions with constraints. While the reward hypothesis suggests these competing demands can be encapsulated in a single scalar reward function, designing such functions remains challenging. Building on existing work, we start by formulating preferences over trajectories to derive a realistic reward function that balances goal achievement with constraint satisfaction in the application of mobile robotics with dynamic obstacles. To mitigate reward exploitation in such complex settings, we propose a novel two-stage reward curriculum combined with a flexible replay buffer that adaptively samples experiences. Our approach first learns on a subset of rewards before transitioning to the full reward, allowing the agent to learn trade-offs between objectives and constraints. After transitioning to a new stage, our method continues to make use of past experiences by updating their rewards for sample-efficient learning. We investigate the efficacy of our approach in robot navigation tasks and demonstrate superior performance compared to baselines in terms of true reward achievement and task completion, underlining its effectiveness.
ECAP: Extensive Cut-and-Paste Augmentation for Unsupervised Domain Adaptive Semantic Segmentation
Mar 06, 2024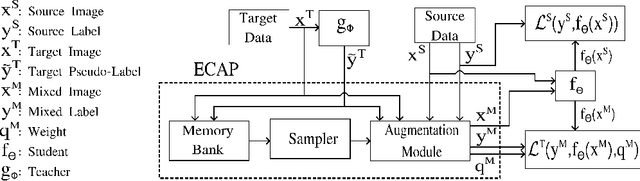
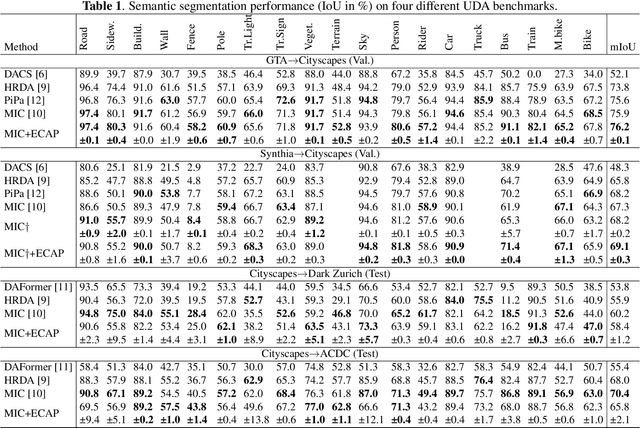
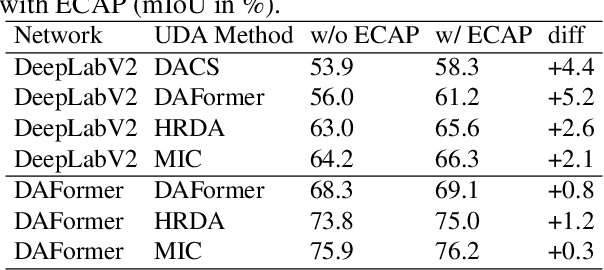

We consider unsupervised domain adaptation (UDA) for semantic segmentation in which the model is trained on a labeled source dataset and adapted to an unlabeled target dataset. Unfortunately, current self-training methods are susceptible to misclassified pseudo-labels resulting from erroneous predictions. Since certain classes are typically associated with less reliable predictions in UDA, reducing the impact of such pseudo-labels without skewing the training towards some classes is notoriously difficult. To this end, we propose an extensive cut-and-paste strategy (ECAP) to leverage reliable pseudo-labels through data augmentation. Specifically, ECAP maintains a memory bank of pseudo-labeled target samples throughout training and cut-and-pastes the most confident ones onto the current training batch. We implement ECAP on top of the recent method MIC and boost its performance on two synthetic-to-real domain adaptation benchmarks. Notably, MIC+ECAP reaches an unprecedented performance of 69.1 mIoU on the Synthia->Cityscapes benchmark. Our code is available at https://github.com/ErikBrorsson/ECAP.
Falsification of Cyber-Physical Systems using Bayesian Optimization
Sep 14, 2022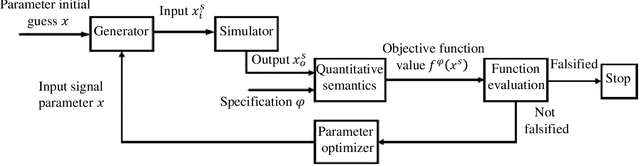
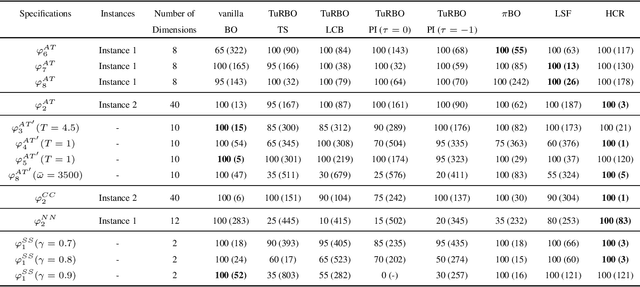
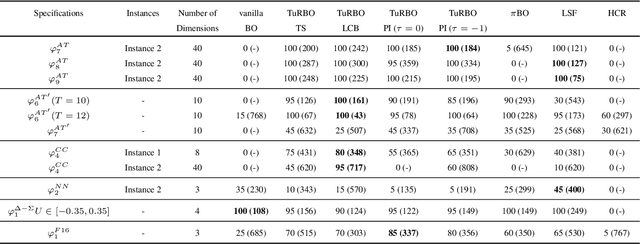
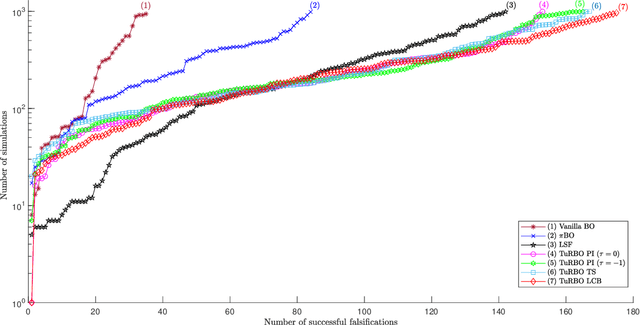
Cyber-physical systems (CPSs) are usually complex and safety-critical; hence, it is difficult and important to guarantee that the system's requirements, i.e., specifications, are fulfilled. Simulation-based falsification of CPSs is a practical testing method that can be used to raise confidence in the correctness of the system by only requiring that the system under test can be simulated. As each simulation is typically computationally intensive, an important step is to reduce the number of simulations needed to falsify a specification. We study Bayesian optimization (BO), a sample-efficient method that learns a surrogate model that describes the relationship between the parametrization of possible input signals and the evaluation of the specification. In this paper, we improve the falsification using BO by; first adopting two prominent BO methods, one fits local surrogate models, and the other exploits the user's prior knowledge. Secondly, the formulation of acquisition functions for falsification is addressed in this paper. Benchmark evaluation shows significant improvements in using local surrogate models of BO for falsifying benchmark examples that were previously hard to falsify. Using prior knowledge in the falsification process is shown to be particularly important when the simulation budget is limited. For some of the benchmark problems, the choice of acquisition function clearly affects the number of simulations needed for successful falsification.
An SMT Based Compositional Algorithm to Solve a Conflict-Free Electric Vehicle Routing Problem
Jun 30, 2021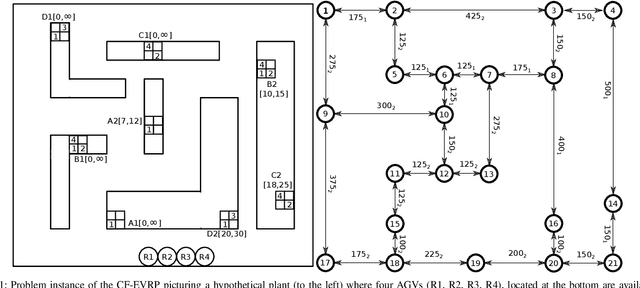
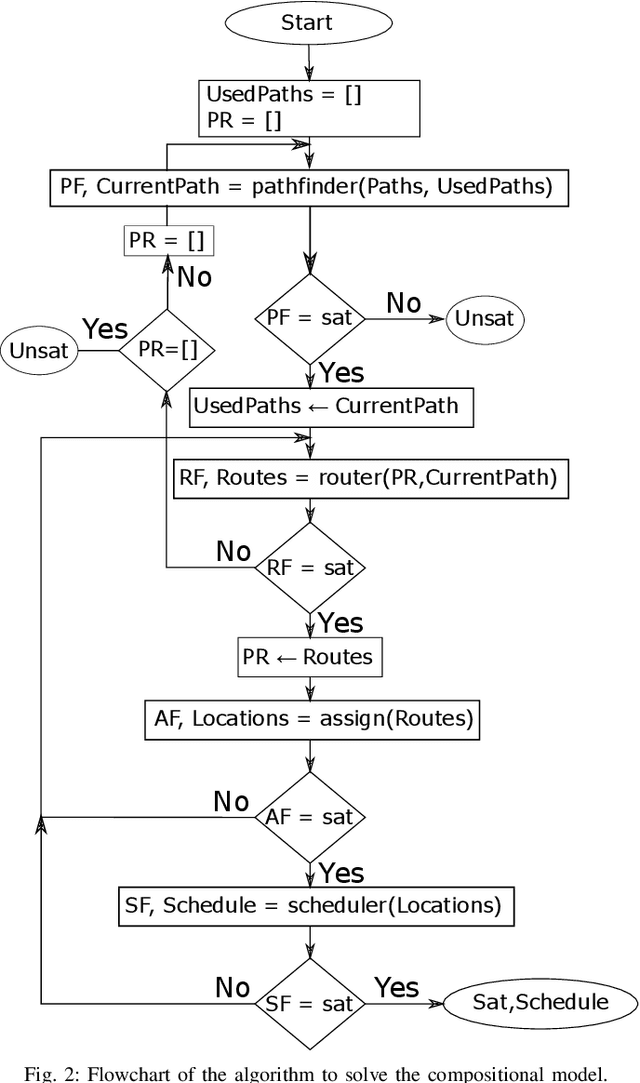
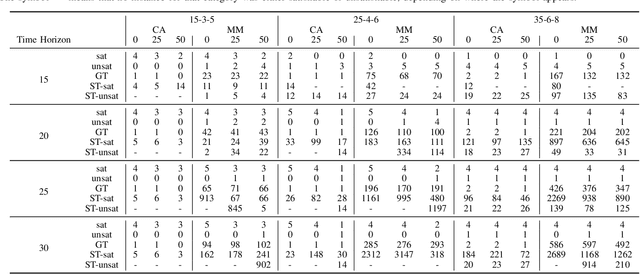
The Vehicle Routing Problem (VRP) is the combinatorial optimization problem of designing routes for vehicles to visit customers in such a fashion that a cost function, typically the number of vehicles, or the total travelled distance is minimized. The problem finds applications in industrial scenarios, for example where Automated Guided Vehicles run through the plant to deliver components from the warehouse. This specific problem, henceforth called the Electric Conflict-Free Vehicle Routing Problem (CF-EVRP), involves constraints such as limited operating range of the vehicles, time windows on the delivery to the customers, and limited capacity on the number of vehicles the road segments can accommodate at the same time. Such a complex system results in a large model that cannot easily be solved to optimality in reasonable time. We therefore developed a compositional model that breaks down the problem into smaller and simpler sub-problems and provides sub-optimal, feasible solutions to the original problem. The algorithm exploits the strengths of SMT solvers, which proved in our previous work to be an efficient approach to deal with scheduling problems. Compared to a monolithic model for the CF-EVRP, written in the SMT standard language and solved using a state-of-the-art SMT solver the compositional model was found to be significantly faster.