 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Curriculum Reinforcement Learning for Complex Reward Functions
Paper and Code
Oct 22, 2024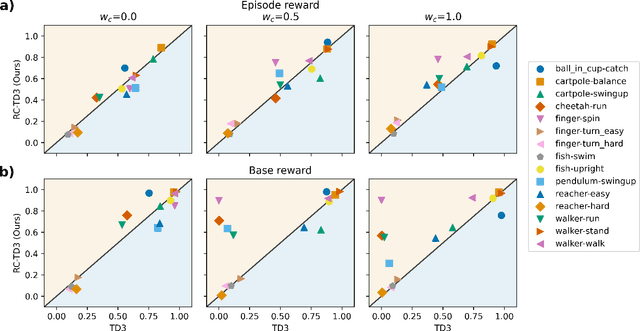
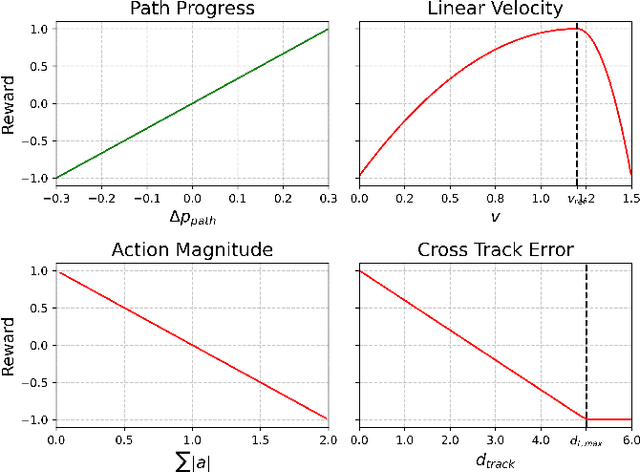
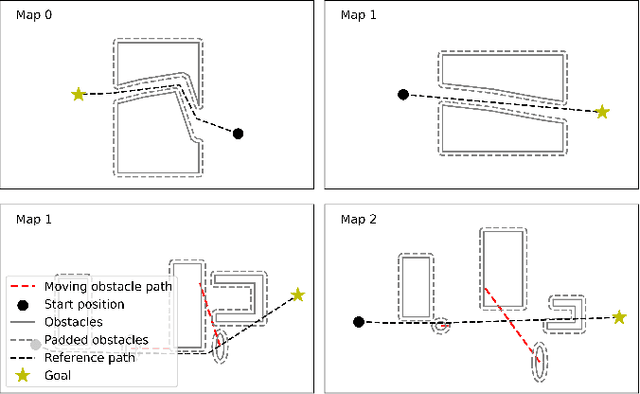
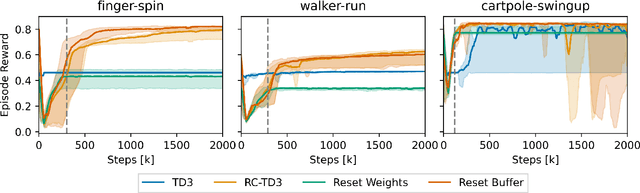
Reinforcement learning (RL) shows promise in control problems, but its practical application is often hindered by the complexity arising from intricate reward functions with constraints. While the reward hypothesis suggests these competing demands can be encapsulated in a single scalar reward function, designing such functions remains challenging. Building on existing work, we start by formulating preferences over trajectories to derive a realistic reward function that balances goal achievement with constraint satisfaction in the application of mobile robotics with dynamic obstacles. To mitigate reward exploitation in such complex settings, we propose a novel two-stage reward curriculum combined with a flexible replay buffer that adaptively samples experiences. Our approach first learns on a subset of rewards before transitioning to the full reward, allowing the agent to learn trade-offs between objectives and constraints. After transitioning to a new stage, our method continues to make use of past experiences by updating their rewards for sample-efficient learning. We investigate the efficacy of our approach in robot navigation tasks and demonstrate superior performance compared to baselines in terms of true reward achievement and task completion, underlining its effectiveness.