 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Curriculum Reinforcement Learning for Complex Reward Functions
Oct 22, 2024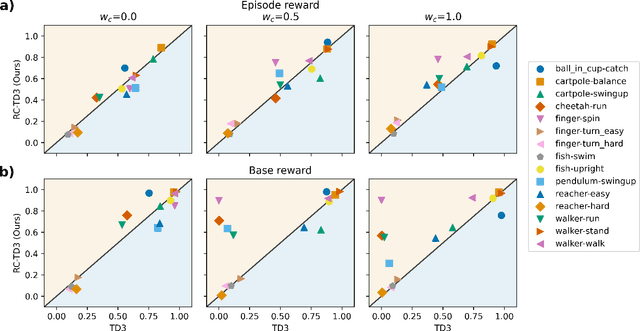
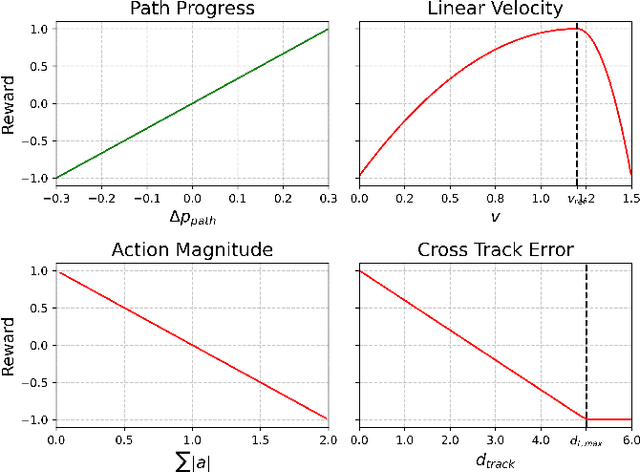
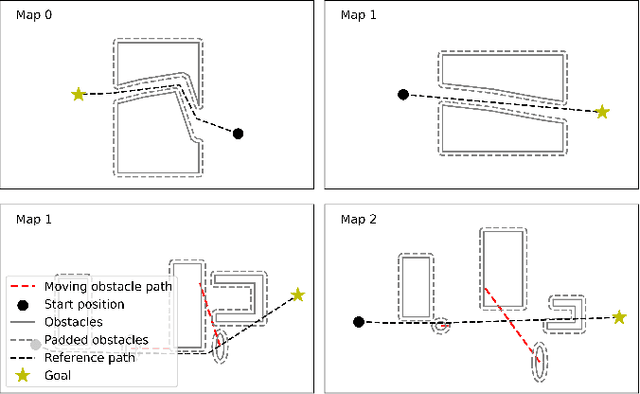
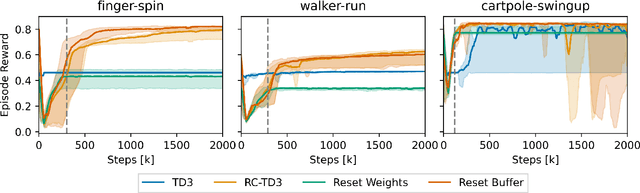
Reinforcement learning (RL) shows promise in control problems, but its practical application is often hindered by the complexity arising from intricate reward functions with constraints. While the reward hypothesis suggests these competing demands can be encapsulated in a single scalar reward function, designing such functions remains challenging. Building on existing work, we start by formulating preferences over trajectories to derive a realistic reward function that balances goal achievement with constraint satisfaction in the application of mobile robotics with dynamic obstacles. To mitigate reward exploitation in such complex settings, we propose a novel two-stage reward curriculum combined with a flexible replay buffer that adaptively samples experiences. Our approach first learns on a subset of rewards before transitioning to the full reward, allowing the agent to learn trade-offs between objectives and constraints. After transitioning to a new stage, our method continues to make use of past experiences by updating their rewards for sample-efficient learning. We investigate the efficacy of our approach in robot navigation tasks and demonstrate superior performance compared to baselines in terms of true reward achievement and task completion, underlining its effectiveness.
Offline Goal-Conditioned Reinforcement Learning for Shape Control of Deformable Linear Objects
Mar 15, 2024Deformable objects present several challenges to the field of robotic manipulation. One of the tasks that best encapsulates the difficulties arising due to non-rigid behavior is shape control, which requires driving an object to a desired shape. While shape-servoing methods have been shown successful in contexts with approximately linear behavior, they can fail in tasks with more complex dynamics. We investigate an alternative approach, using offline RL to solve a planar shape control problem of a Deformable Linear Object (DLO). To evaluate the effect of material properties, two DLOs are tested namely a soft rope and an elastic cord. We frame this task as a goal-conditioned offline RL problem, and aim to learn to generalize to unseen goal shapes. Data collection and augmentation procedures are proposed to limit the amount of experimental data which needs to be collected with the real robot. We evaluate the amount of augmentation needed to achieve the best results, and test the effect of regularization through behavior cloning on the TD3+BC algorithm. Finally, we show that the proposed approach is able to outperform a shape-servoing baseline in a curvature inversion experiment.
Feel the Tension: Manipulation of Deformable Linear Objects in Environments with Fixtures using Force Information
Oct 10, 2023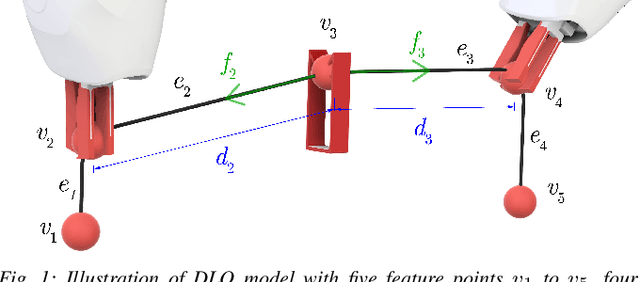
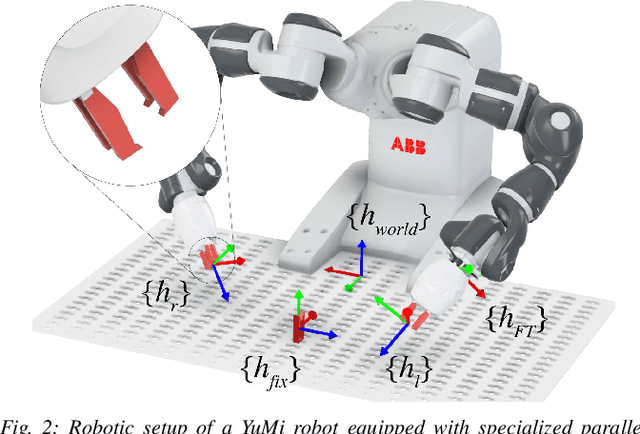
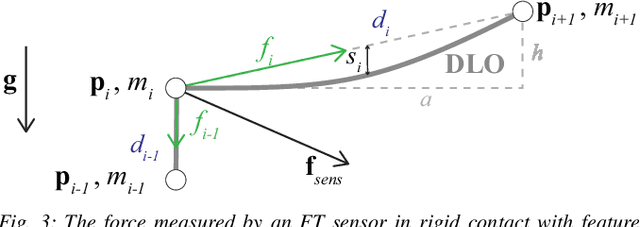
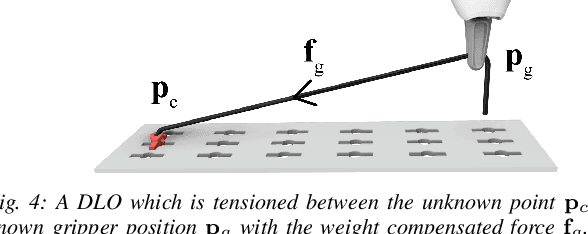
Humans are able to manipulate Deformable Linear Objects (DLOs) such as cables and wires, with little or no visual information, relying mostly on force sensing. In this work, we propose a reduced DLO model which enables such blind manipulation by keeping the object under tension. Further, an online model estimation procedure is also proposed. A set of elementary sliding and clipping manipulation primitives are defined based on our model. The combination of these primitives allows for more complex motions such as winding of a DLO. The model estimation and manipulation primitives are tested individually but also together in a real-world cable harness production task, using a dual-arm YuMi, thus demonstrating that force-based perception can be sufficient even for such a complex scenario.
Learning Shape Control of Elastoplastic Deformable Linear Objects
Aug 03, 2022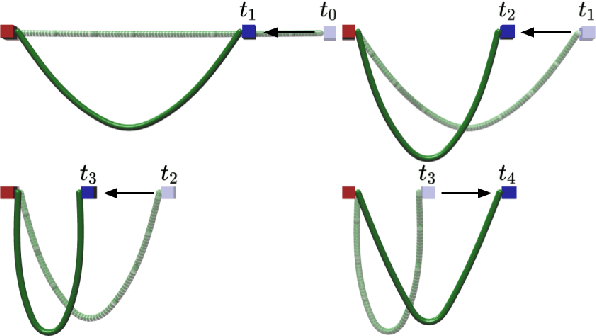
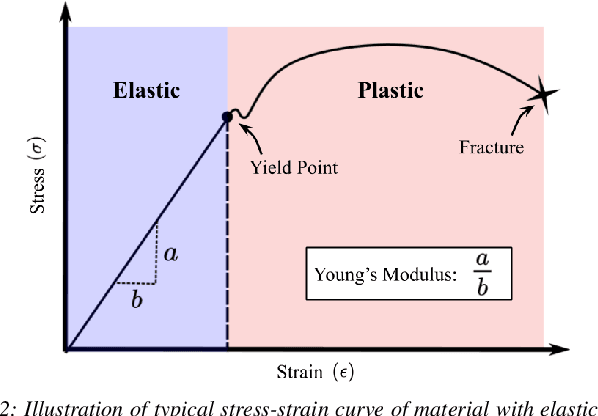
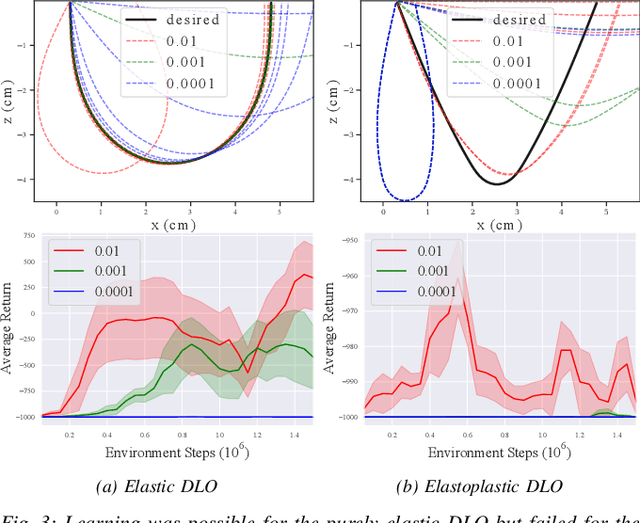
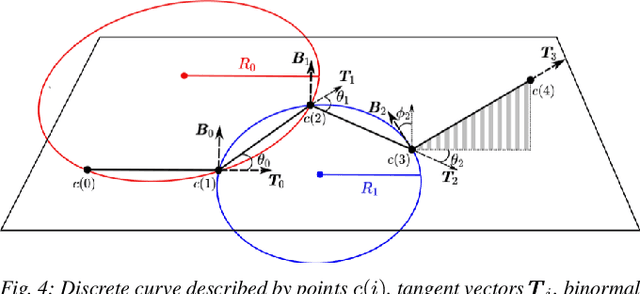
Deformable object manipulation tasks have long been regarded as challenging robotic problems. However, until recently very little work has been done on the subject, with most robotic manipulation methods being developed for rigid objects. Deformable objects are more difficult to model and simulate, which has limited the use of model-free Reinforcement Learning (RL) strategies, due to their need for large amounts of data that can only be satisfied in simulation. This paper proposes a new shape control task for Deformable Linear Objects (DLOs). More notably, we present the first study on the effects of elastoplastic properties on this type of problem. Objects with elastoplasticity such as metal wires, are found in various applications and are challenging to manipulate due to their nonlinear behavior. We first highlight the challenges of solving such a manipulation task from an RL perspective, particularly in defining the reward. Then, based on concepts from differential geometry, we propose an intrinsic shape representation using discrete curvature and torsion. Finally, we show through an empirical study that in order to successfully solve the proposed task using Deep Deterministic Policy Gradient (DDPG), the reward needs to include intrinsic information about the shape of the DLO.