 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStixelNExT++: Lightweight Monocular Scene Segmentation and Representation for Collective Perception
Jul 09, 2025This paper presents StixelNExT++, a novel approach to scene representation for monocular perception systems. Building on the established Stixel representation, our method infers 3D Stixels and enhances object segmentation by clustering smaller 3D Stixel units. The approach achieves high compression of scene information while remaining adaptable to point cloud and bird's-eye-view representations. Our lightweight neural network, trained on automatically generated LiDAR-based ground truth, achieves real-time performance with computation times as low as 10 ms per frame. Experimental results on the Waymo dataset demonstrate competitive performance within a 30-meter range, highlighting the potential of StixelNExT++ for collective perception in autonomous systems.
StixelNExT: Toward Monocular Low-Weight Perception for Object Segmentation and Free Space Detection
Jul 11, 2024



In this work, we present a novel approach for general object segmentation from a monocular image, eliminating the need for manually labeled training data and enabling rapid, straightforward training and adaptation with minimal data. Our model initially learns from LiDAR during the training process, which is subsequently removed from the system, allowing it to function solely on monocular imagery. This study leverages the concept of the Stixel-World to recognize a medium level representation of its surroundings. Our network directly predicts a 2D multi-layer Stixel-World and is capable of recognizing and locating multiple, superimposed objects within an image. Due to the scarcity of comparable works, we have divided the capabilities into modules and present a free space detection in our experiments section. Furthermore, we introduce an improved method for generating Stixels from LiDAR data, which we use as ground truth for our network.
The OPNV Data Collection: A Dataset for Infrastructure-Supported Perception Research with Focus on Public Transportation
Jul 11, 2024This paper we present our vision and ongoing work for a novel dataset designed to advance research into the interoperability of intelligent vehicles and infrastructure, specifically aimed at enhancing cooperative perception and interaction in the realm of public transportation. Unlike conventional datasets centered on ego-vehicle data, this approach encompasses both a stationary sensor tower and a moving vehicle, each equipped with cameras, LiDARs, and GNSS, while the vehicle additionally includes an inertial navigation system. Our setup features comprehensive calibration and time synchronization, ensuring seamless and accurate sensor data fusion crucial for studying complex, dynamic scenes. Emphasizing public transportation, the dataset targets to include scenes like bus station maneuvers and driving on dedicated bus lanes, reflecting the specifics of small public buses. We introduce the open-source ".4mse" file format for the new dataset, accompanied by a research kit. This kit provides tools such as ego-motion compensation or LiDAR-to-camera projection enabling advanced research on intelligent vehicle-infrastructure integration. Our approach does not include annotations; however, we plan to implement automatically generated labels sourced from state-of-the-art public repositories. Several aspects are still up for discussion, and timely feedback from the community would be greatly appreciated. A sneak preview on one data frame will be available at a Google Colab Notebook. Moreover, we will use the related GitHub Repository to collect remarks and suggestions.
Offline Goal-Conditioned Reinforcement Learning for Shape Control of Deformable Linear Objects
Mar 15, 2024Deformable objects present several challenges to the field of robotic manipulation. One of the tasks that best encapsulates the difficulties arising due to non-rigid behavior is shape control, which requires driving an object to a desired shape. While shape-servoing methods have been shown successful in contexts with approximately linear behavior, they can fail in tasks with more complex dynamics. We investigate an alternative approach, using offline RL to solve a planar shape control problem of a Deformable Linear Object (DLO). To evaluate the effect of material properties, two DLOs are tested namely a soft rope and an elastic cord. We frame this task as a goal-conditioned offline RL problem, and aim to learn to generalize to unseen goal shapes. Data collection and augmentation procedures are proposed to limit the amount of experimental data which needs to be collected with the real robot. We evaluate the amount of augmentation needed to achieve the best results, and test the effect of regularization through behavior cloning on the TD3+BC algorithm. Finally, we show that the proposed approach is able to outperform a shape-servoing baseline in a curvature inversion experiment.
Scale-free vision-based aerial control of a ground formation with hybrid topology
Jan 24, 2024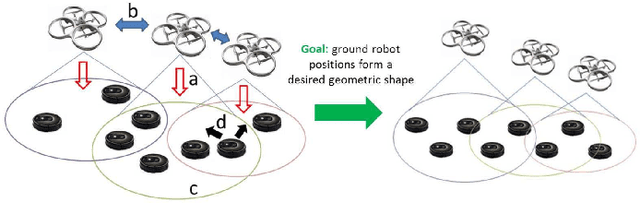



We present a novel vision-based control method to make a group of ground mobile robots achieve a specified formation shape with unspecified size. Our approach uses multiple aerial control units equipped with downward-facing cameras, each observing a partial subset of the multirobot team. The units compute the control commands from the ground robots' image projections, using neither calibration nor scene scale information, and transmit them to the robots. The control strategy relies on the calculation of image similarity transformations, and we show it to be asymptotically stable if the overlaps between the subsets of controlled robots satisfy certain conditions. The presence of the supervisory units, which coordinate their motions to guarantee a correct control performance, gives rise to a hybrid system topology. All in all, the proposed system provides relevant practical advantages in simplicity and flexibility. Within the problem of controlling a team shape, our contribution lies in addressing several simultaneous challenges: the controller needs only partial information of the robotic group, does not use distance measurements or global reference frames, is designed for unicycle agents, and can accommodate topology changes. We present illustrative simulation results.
* This is the accepted version an already published manuscript. See journal reference for details
Robotic Control of the Deformation of Soft Linear Objects Using Deep Reinforcement Learning
Dec 08, 2023



This paper proposes a new control framework for manipulating soft objects. A Deep Reinforcement Learning (DRL) approach is used to make the shape of a deformable object reach a set of desired points by controlling a robotic arm which manipulates it. Our framework is more easily generalizable than existing ones: it can work directly with different initial and desired final shapes without need for relearning. We achieve this by using learning parallelization, i.e., executing multiple agents in parallel on various environment instances. We focus our study on deformable linear objects. These objects are interesting in industrial and agricultural domains, yet their manipulation with robots, especially in 3D workspaces, remains challenging. We simulate the entire environment, i.e., the soft object and the robot, for the training and the testing using PyBullet and OpenAI Gym. We use a combination of state-of-the-art DRL techniques, the main ingredient being a training approach for the learning agent (i.e., the robot) based on Deep Deterministic Policy Gradient (DDPG). Our simulation results support the usefulness and enhanced generality of the proposed approach.
Multi Actor-Critic DDPG for Robot Action Space Decomposition: A Framework to Control Large 3D Deformation of Soft Linear Objects
Dec 08, 2023



Robotic manipulation of deformable linear objects (DLOs) has great potential for applications in diverse fields such as agriculture or industry. However, a major challenge lies in acquiring accurate deformation models that describe the relationship between robot motion and DLO deformations. Such models are difficult to calculate analytically and vary among DLOs. Consequently, manipulating DLOs poses significant challenges, particularly in achieving large deformations that require highly accurate global models. To address these challenges, this paper presents MultiAC6: a new multi Actor-Critic framework for robot action space decomposition to control large 3D deformations of DLOs. In our approach, two deep reinforcement learning (DRL) agents orient and position a robot gripper to deform a DLO into the desired shape. Unlike previous DRL-based studies, MultiAC6 is able to solve the sim-to-real gap, achieving large 3D deformations up to 40 cm in real-world settings. Experimental results also show that MultiAC6 has a 66\% higher success rate than a single-agent approach. Further experimental studies demonstrate that MultiAC6 generalizes well, without retraining, to DLOs with different lengths or materials.
ROBUSfT: Robust Real-Time Shape-from-Template, a C++ Library
Jan 10, 2023



Tracking the 3D shape of a deforming object using only monocular 2D vision is a challenging problem. This is because one should (i) infer the 3D shape from a 2D image, which is a severely underconstrained problem, and (ii) implement the whole solution pipeline in real-time. The pipeline typically requires feature detection and matching, mismatch filtering, 3D shape inference and feature tracking algorithms. We propose ROBUSfT, a conventional pipeline based on a template containing the object's rest shape, texturemap and deformation law. ROBUSfT is ready-to-use, wide-baseline, capable of handling large deformations, fast up to 30 fps, free of training, and robust against partial occlusions and discontinuity in video frames. It outperforms the state-of-the-art methods in challenging datasets. ROBUSfT is implemented as a publicly available C++ library and we provide a tutorial on how to use it in https://github.com/mrshetab/ROBUSfT
Lattice-based shape tracking and servoing of elastic objects
Sep 07, 2022

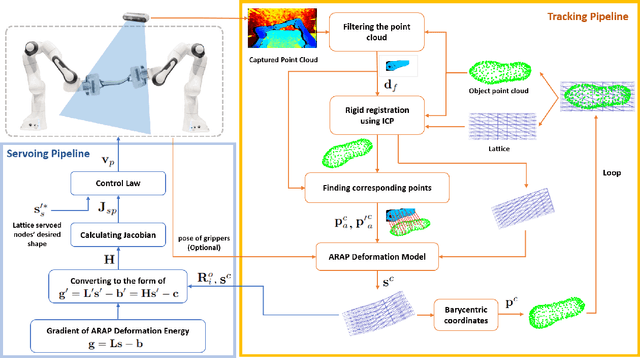

In this paper, we propose a general unified tracking-servoing approach for controlling the shape of elastic deformable objects using robotic arms. Our approach works by forming a lattice around the object, binding the object to the lattice, and tracking and servoing the lattice instead of the object. This makes our approach have full 3D control over deformable objects of any general form (linear, thin-shell, volumetric). Furthermore, it decouples the runtime complexity of the approach from the objects' geometric complexity. Our approach is based on the As-Rigid-As-Possible (ARAP) deformation model. It requires no mechanical parameter of the object to be known and can drive the object toward desired shapes through large deformations. The inputs to our approach are the point cloud of the object's surface in its rest shape and the point cloud captured by a 3D camera in each frame. Overall, our approach is more broadly applicable than existing approaches. We validate the efficiency of our approach through numerous experiments with deformable objects of various shapes and materials (paper, rubber, plastic, foam). Experiment videos are available on the project website: https://sites.google.com/view/tracking-servoing-approach.