 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRL-Based Pose Control for Double-Ackermann Robots Under Actuation Uncertainties
May 29, 2026Robust deployment of deep reinforcement learning (DRL) policies on real robots remains challenging due to discrepancies between simulation and real-world dynamics. We address this issue in the context of maneuvering with double-Ackermann-steering mobile robots, which introduce additional constraints due to their non-holonomic nature. Building upon the DRL framework ManeuverNet, we extend its objective from position control to full pose control, resulting in a more challenging task. We further investigate the impact of actuation-related uncertainties on policy transfer. The use of simplified actuation models during training of the extended policy can lead to poor generalization, shown by a success rate drop from 100% in PyBullet to 25% in Gazebo under stricter evaluation conditions. To address this limitation, we adopt a sim-to-sim-to-real approach, where actuation effects observed in Gazebo are incorporated into the PyBullet training environment. Using multi-environment DRL with SAC and CrossQ, we learn policies that remain robust despite modeling inaccuracies. This approach can significantly reduce the performance gap across simulators, achieving up to 92% success rate in Gazebo and maintaining 69% under stricter thresholds, with successful transfer to a real robot without additional tuning.
PhyPush: One Push is All You Need for Sensorless Physical Property Estimation with Physics-Guided Transformers
May 25, 2026Accurately estimating object mass and friction is fundamental to achieving reliable and adaptive robotic manipulation. Although interactive perception provides a powerful mechanism for inferring such properties, most existing approaches depend on specialized hardware such as force/torque sensors, tactile arrays, or multi-camera motion-capture systems, limiting scalability and deployment. This paper presents PhyPush, a physics-guided Transformer framework that estimates an object's mass and friction coefficient using only kinematically derived end-effector velocity from a single push. This typically requires data available on standard robotic arms. The model incorporates constraints from Newton's second law and the Coulomb friction model through a physics-guided loss, improving physical consistency and generalization to unseen objects and surfaces. Across diverse simulation and real-world setups, PhyPush consistently achieves more accurate mass and friction estimation in challenging out-of-domain conditions. In simulation, it reduces error by over 10% compared with a baseline that has privileged access to full force information, while in real-world experiments, it outperforms a data-driven loss approach. Overall, the results demonstrate that physics-guided learning can enable low-cost, sensor-efficient estimation of physical properties, relying solely on a single push and readily available kinematic data.
ManeuverNet: A Soft Actor-Critic Framework for Precise Maneuvering of Double-Ackermann-Steering Robots with Optimized Reward Functions
Feb 16, 2026Autonomous control of double-Ackermann-steering robots is essential in agricultural applications, where robots must execute precise and complex maneuvers within a limited space. Classical methods, such as the Timed Elastic Band (TEB) planner, can address this problem, but they rely on parameter tuning, making them highly sensitive to changes in robot configuration or environment and impractical to deploy without constant recalibration. At the same time, end-to-end deep reinforcement learning (DRL) methods often fail due to unsuitable reward functions for non-holonomic constraints, resulting in sub-optimal policies and poor generalization. To address these challenges, this paper presents ManeuverNet, a DRL framework tailored for double-Ackermann systems, combining Soft Actor-Critic with CrossQ. Furthermore, ManeuverNet introduces four specifically designed reward functions to support maneuver learning. Unlike prior work, ManeuverNet does not depend on expert data or handcrafted guidance. We extensively evaluate ManeuverNet against both state-of-the-art DRL baselines and the TEB planner. Experimental results demonstrate that our framework substantially improves maneuverability and success rates, achieving more than a 40% gain over DRL baselines. Moreover, ManeuverNet effectively mitigates the strong parameter sensitivity observed in the TEB planner. In real-world trials, ManeuverNet achieved up to a 90% increase in maneuvering trajectory efficiency, highlighting its robustness and practical applicability.
Beyond Detection -- Orchestrating Human-Robot-Robot Assistance via an Internet of Robotic Things Paradigm
Sep 26, 2025


Hospital patient falls remain a critical and costly challenge worldwide. While conventional fall prevention systems typically rely on post-fall detection or reactive alerts, they also often suffer from high false positive rates and fail to address the underlying patient needs that lead to bed-exit attempts. This paper presents a novel system architecture that leverages the Internet of Robotic Things (IoRT) to orchestrate human-robot-robot interaction for proactive and personalized patient assistance. The system integrates a privacy-preserving thermal sensing model capable of real-time bed-exit prediction, with two coordinated robotic agents that respond dynamically based on predicted intent and patient input. This orchestrated response could not only reduce fall risk but also attend to the patient's underlying motivations for movement, such as thirst, discomfort, or the need for assistance, before a hazardous situation arises. Our contributions with this pilot study are three-fold: (1) a modular IoRT-based framework enabling distributed sensing, prediction, and multi-robot coordination; (2) a demonstration of low-resolution thermal sensing for accurate, privacy-preserving preemptive bed-exit detection; and (3) results from a user study and systematic error analysis that inform the design of situationally aware, multi-agent interactions in hospital settings. The findings highlight how interactive and connected robotic systems can move beyond passive monitoring to deliver timely, meaningful assistance, empowering safer, more responsive care environments.
Multi Actor-Critic DDPG for Robot Action Space Decomposition: A Framework to Control Large 3D Deformation of Soft Linear Objects
Dec 08, 2023



Robotic manipulation of deformable linear objects (DLOs) has great potential for applications in diverse fields such as agriculture or industry. However, a major challenge lies in acquiring accurate deformation models that describe the relationship between robot motion and DLO deformations. Such models are difficult to calculate analytically and vary among DLOs. Consequently, manipulating DLOs poses significant challenges, particularly in achieving large deformations that require highly accurate global models. To address these challenges, this paper presents MultiAC6: a new multi Actor-Critic framework for robot action space decomposition to control large 3D deformations of DLOs. In our approach, two deep reinforcement learning (DRL) agents orient and position a robot gripper to deform a DLO into the desired shape. Unlike previous DRL-based studies, MultiAC6 is able to solve the sim-to-real gap, achieving large 3D deformations up to 40 cm in real-world settings. Experimental results also show that MultiAC6 has a 66\% higher success rate than a single-agent approach. Further experimental studies demonstrate that MultiAC6 generalizes well, without retraining, to DLOs with different lengths or materials.
CrossMap Transformer: A Crossmodal Masked Path Transformer Using Double Back-Translation for Vision-and-Language Navigation
Mar 01, 2021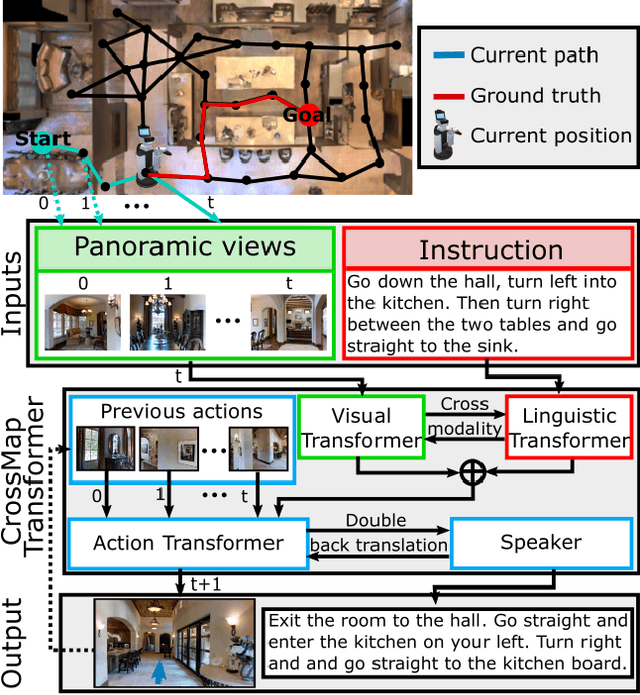
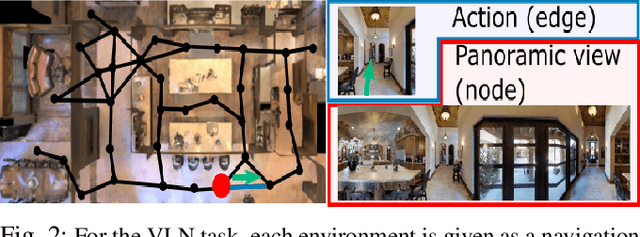
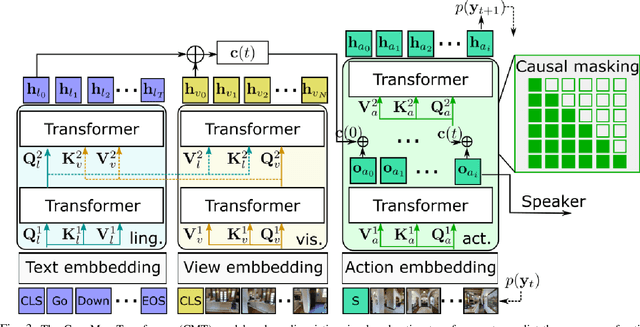
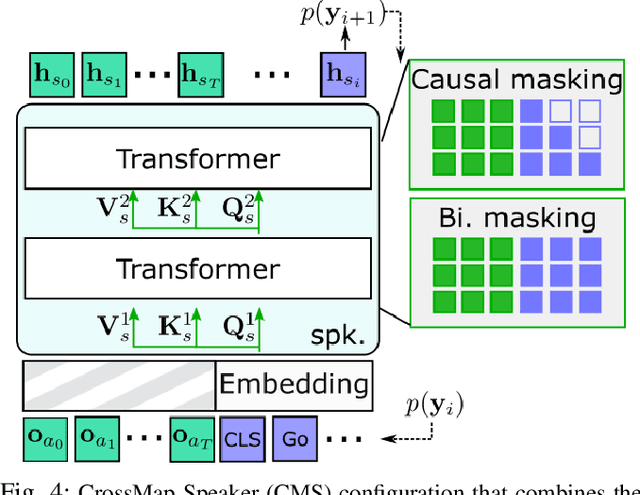
Navigation guided by natural language instructions is particularly suitable for Domestic Service Robots that interacts naturally with users. This task involves the prediction of a sequence of actions that leads to a specified destination given a natural language navigation instruction. The task thus requires the understanding of instructions, such as ``Walk out of the bathroom and wait on the stairs that are on the right''. The Visual and Language Navigation remains challenging, notably because it requires the exploration of the environment and at the accurate following of a path specified by the instructions to model the relationship between language and vision. To address this, we propose the CrossMap Transformer network, which encodes the linguistic and visual features to sequentially generate a path. The CrossMap transformer is tied to a Transformer-based speaker that generates navigation instructions. The two networks share common latent features, for mutual enhancement through a double back translation model: Generated paths are translated into instructions while generated instructions are translated into path The experimental results show the benefits of our approach in terms of instruction understanding and instruction generation.
Predicting and Attending to Damaging Collisions for Placing Everyday Objects in Photo-Realistic Simulations
Feb 12, 2021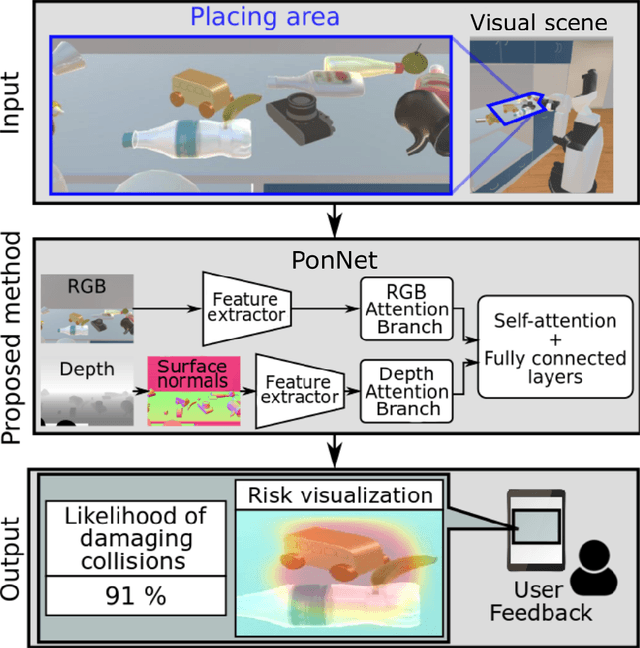


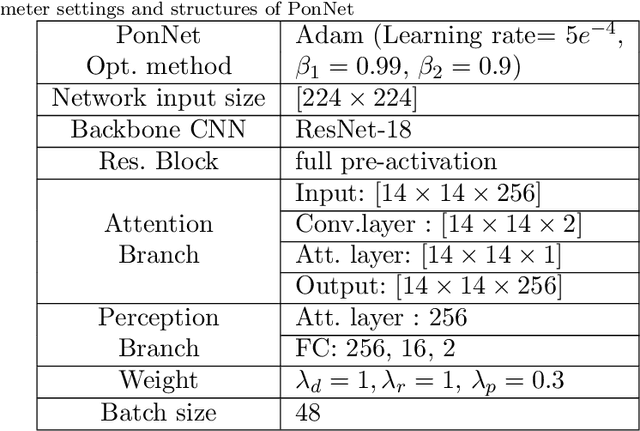
Placing objects is a fundamental task for domestic service robots (DSRs). Thus, inferring the collision-risk before a placing motion is crucial for achieving the requested task. This problem is particularly challenging because it is necessary to predict what happens if an object is placed in a cluttered designated area. We show that a rule-based approach that uses plane detection, to detect free areas, performs poorly. To address this, we develop PonNet, which has multimodal attention branches and a self-attention mechanism to predict damaging collisions, based on RGBD images. Our method can visualize the risk of damaging collisions, which is convenient because it enables the user to understand the risk. For this purpose, we build and publish an original dataset that contains 12,000 photo-realistic images of specific placing areas, with daily life objects, in home environments. The experimental results show that our approach improves accuracy compared with the baseline methods.
Alleviating the Burden of Labeling: Sentence Generation by Attention Branch Encoder-Decoder Network
Jul 09, 2020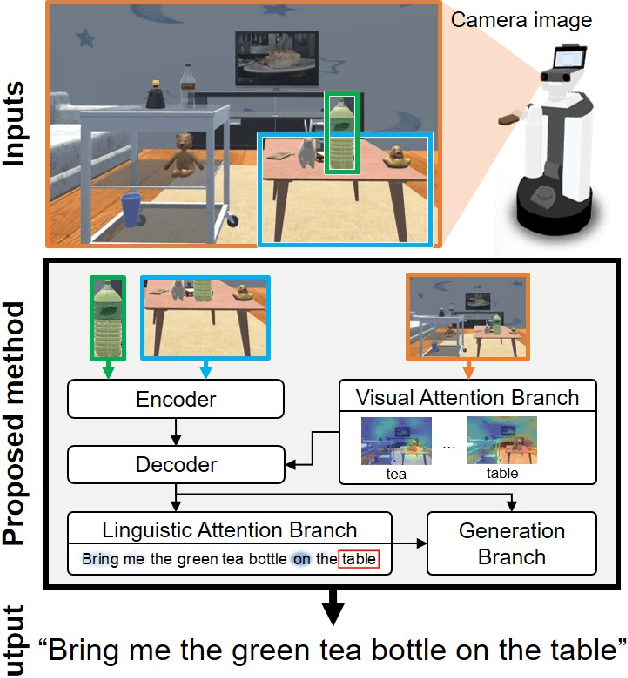

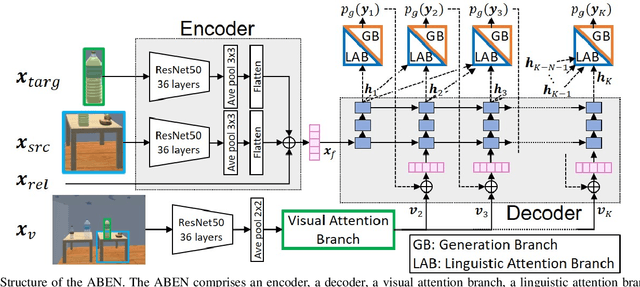
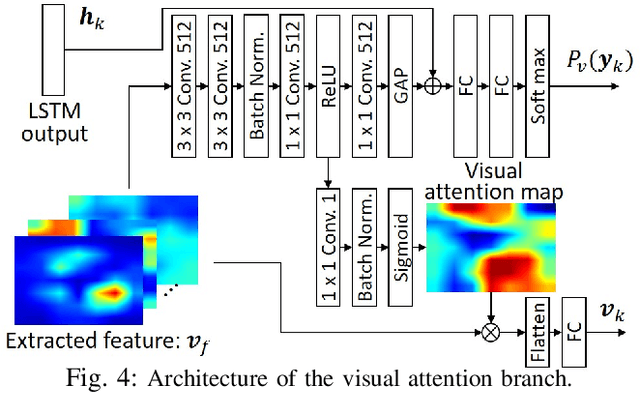
Domestic service robots (DSRs) are a promising solution to the shortage of home care workers. However, one of the main limitations of DSRs is their inability to interact naturally through language. Recently, data-driven approaches have been shown to be effective for tackling this limitation; however, they often require large-scale datasets, which is costly. Based on this background, we aim to perform automatic sentence generation of fetching instructions: for example, "Bring me a green tea bottle on the table." This is particularly challenging because appropriate expressions depend on the target object, as well as its surroundings. In this paper, we propose the attention branch encoder--decoder network (ABEN), to generate sentences from visual inputs. Unlike other approaches, the ABEN has multimodal attention branches that use subword-level attention and generate sentences based on subword embeddings. In experiments, we compared the ABEN with a baseline method using four standard metrics in image captioning. Results show that the ABEN outperformed the baseline in terms of these metrics.
A Multimodal Target-Source Classifier with Attention Branches to Understand Ambiguous Instructions for Fetching Daily Objects
Dec 25, 2019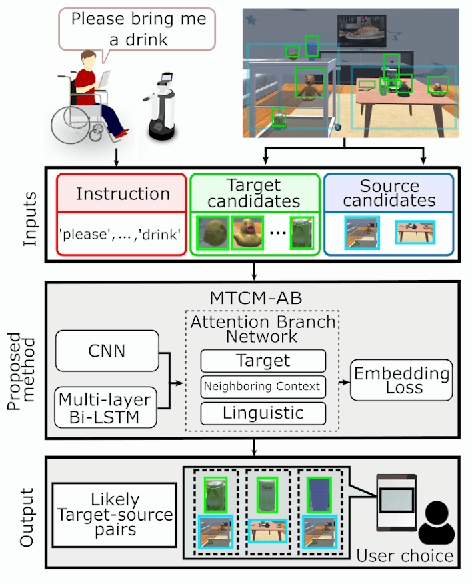
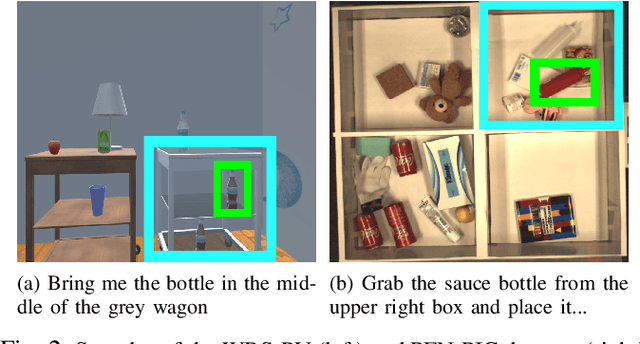
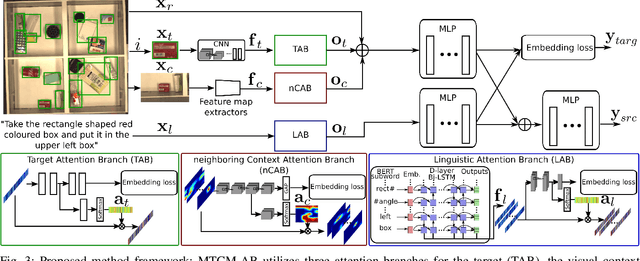

In this study, we focus on multimodal language understanding for fetching instructions in the domestic service robots context. This task consists of predicting a target object, as instructed by the user, given an image and an unstructured sentence, such as "Bring me the yellow box (from the wooden cabinet)." This is challenging because of the ambiguity of natural language, i.e., the relevant information may be missing or there might be several candidates. To solve such a task, we propose the multimodal target-source classifier model with attention branches (MTCM-AB), which is an extension of the MTCM. Our methodology uses the attention branch network (ABN) to develop a multimodal attention mechanism based on linguistic and visual inputs. Experimental validation using a standard dataset showed that the MTCM-AB outperformed both state-of-the-art methods and the MTCM. In particular the MTCM-AB accuracy on average was 90.1% while human performance was 90.3% on the PFN-PIC dataset.
Multimodal Attention Branch Network for Perspective-Free Sentence Generation
Sep 10, 2019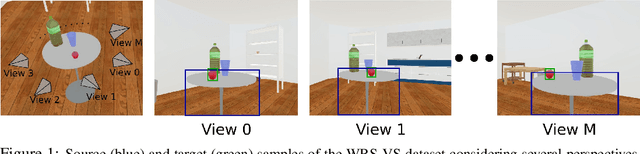
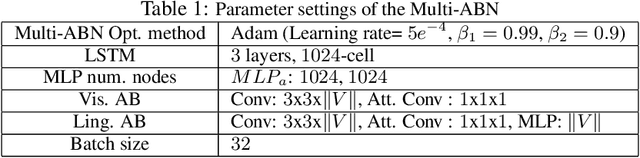
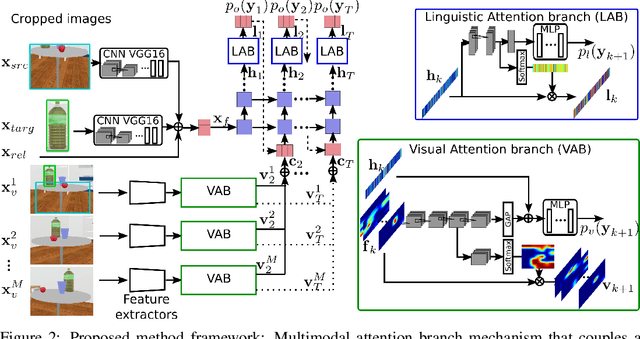
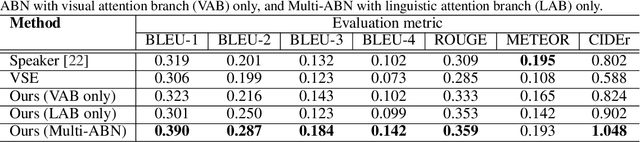
In this paper, we address the automatic sentence generation of fetching instructions for domestic service robots. Typical fetching commands such as "bring me the yellow toy from the upper part of the white shelf" includes referring expressions, i.e., "from the white upper part of the white shelf". To solve this task, we propose a multimodal attention branch network (Multi-ABN) which generates natural sentences in an end-to-end manner. Multi-ABN uses multiple images of the same fixed scene to generate sentences that are not tied to a particular viewpoint. This approach combines a linguistic attention branch mechanism with several attention branch mechanisms. We evaluated our approach, which outperforms the state-of-the-art method on a standard metrics. Our method also allows us to visualize the alignment between the linguistic input and the visual features.