 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Free Image Captioning Evaluation in Reference-Flexible Settings
Dec 25, 2025We focus on the automatic evaluation of image captions in both reference-based and reference-free settings. Existing metrics based on large language models (LLMs) favor their own generations; therefore, the neutrality is in question. Most LLM-free metrics do not suffer from such an issue, whereas they do not always demonstrate high performance. To address these issues, we propose Pearl, an LLM-free supervised metric for image captioning, which is applicable to both reference-based and reference-free settings. We introduce a novel mechanism that learns the representations of image--caption and caption--caption similarities. Furthermore, we construct a human-annotated dataset for image captioning metrics, that comprises approximately 333k human judgments collected from 2,360 annotators across over 75k images. Pearl outperformed other existing LLM-free metrics on the Composite, Flickr8K-Expert, Flickr8K-CF, Nebula, and FOIL datasets in both reference-based and reference-free settings. Our project page is available at https://pearl.kinsta.page/.
Affordance RAG: Hierarchical Multimodal Retrieval with Affordance-Aware Embodied Memory for Mobile Manipulation
Dec 22, 2025In this study, we address the problem of open-vocabulary mobile manipulation, where a robot is required to carry a wide range of objects to receptacles based on free-form natural language instructions. This task is challenging, as it involves understanding visual semantics and the affordance of manipulation actions. To tackle these challenges, we propose Affordance RAG, a zero-shot hierarchical multimodal retrieval framework that constructs Affordance-Aware Embodied Memory from pre-explored images. The model retrieves candidate targets based on regional and visual semantics and reranks them with affordance scores, allowing the robot to identify manipulation options that are likely to be executable in real-world environments. Our method outperformed existing approaches in retrieval performance for mobile manipulation instruction in large-scale indoor environments. Furthermore, in real-world experiments where the robot performed mobile manipulation in indoor environments based on free-form instructions, the proposed method achieved a task success rate of 85%, outperforming existing methods in both retrieval performance and overall task success.
MEGState: Phoneme Decoding from Magnetoencephalography Signals
Dec 19, 2025

Decoding linguistically meaningful representations from non-invasive neural recordings remains a central challenge in neural speech decoding. Among available neuroimaging modalities, magnetoencephalography (MEG) provides a safe and repeatable means of mapping speech-related cortical dynamics, yet its low signal-to-noise ratio and high temporal dimensionality continue to hinder robust decoding. In this work, we introduce MEGState, a novel architecture for phoneme decoding from MEG signals that captures fine-grained cortical responses evoked by auditory stimuli. Extensive experiments on the LibriBrain dataset demonstrate that MEGState consistently surpasses baseline model across multiple evaluation metrics. These findings highlight the potential of MEG-based phoneme decoding as a scalable pathway toward non-invasive brain-computer interfaces for speech.
Attention Lattice Adapter: Visual Explanation Generation for Visual Foundation Model
Sep 18, 2025In this study, we consider the problem of generating visual explanations in visual foundation models. Numerous methods have been proposed for this purpose; however, they often cannot be applied to complex models due to their lack of adaptability. To overcome these limitations, we propose a novel explanation generation method in visual foundation models that is aimed at both generating explanations and partially updating model parameters to enhance interpretability. Our approach introduces two novel mechanisms: Attention Lattice Adapter (ALA) and Alternating Epoch Architect (AEA). ALA mechanism simplifies the process by eliminating the need for manual layer selection, thus enhancing the model's adaptability and interpretability. Moreover, the AEA mechanism, which updates ALA's parameters every other epoch, effectively addresses the common issue of overly small attention regions. We evaluated our method on two benchmark datasets, CUB-200-2011 and ImageNet-S. Our results showed that our method outperformed the baseline methods in terms of mean intersection over union (IoU), insertion score, deletion score, and insertion-deletion score on both the CUB-200-2011 and ImageNet-S datasets. Notably, our best model achieved a 53.2-point improvement in mean IoU on the CUB-200-2011 dataset compared with the baselines.
Pre-Manipulation Alignment Prediction with Parallel Deep State-Space and Transformer Models
Sep 17, 2025In this work, we address the problem of predicting the future success of open-vocabulary object manipulation tasks. Conventional approaches typically determine success or failure after the action has been carried out. However, they make it difficult to prevent potential hazards and rely on failures to trigger replanning, thereby reducing the efficiency of object manipulation sequences. To overcome these challenges, we propose a model, which predicts the alignment between a pre-manipulation egocentric image with the planned trajectory and a given natural language instruction. We introduce a Multi-Level Trajectory Fusion module, which employs a state-of-the-art deep state-space model and a transformer encoder in parallel to capture multi-level time-series self-correlation within the end effector trajectory. Our experimental results indicate that the proposed method outperformed existing methods, including foundation models.
Deep Space Weather Model: Long-Range Solar Flare Prediction from Multi-Wavelength Images
Aug 11, 2025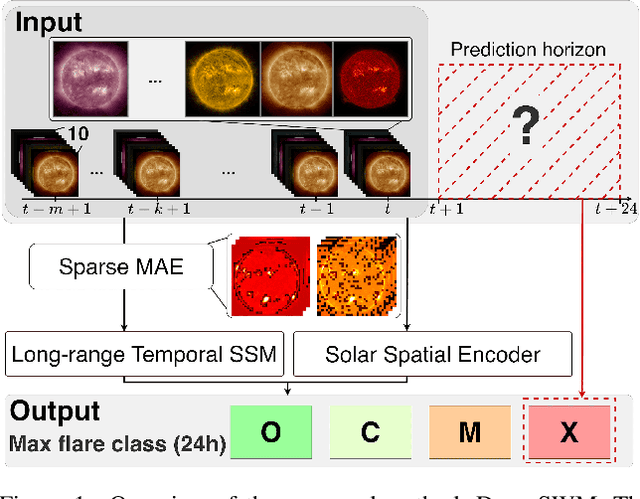



Accurate, reliable solar flare prediction is crucial for mitigating potential disruptions to critical infrastructure, while predicting solar flares remains a significant challenge. Existing methods based on heuristic physical features often lack representation learning from solar images. On the other hand, end-to-end learning approaches struggle to model long-range temporal dependencies in solar images. In this study, we propose Deep Space Weather Model (Deep SWM), which is based on multiple deep state space models for handling both ten-channel solar images and long-range spatio-temporal dependencies. Deep SWM also features a sparse masked autoencoder, a novel pretraining strategy that employs a two-phase masking approach to preserve crucial regions such as sunspots while compressing spatial information. Furthermore, we built FlareBench, a new public benchmark for solar flare prediction covering a full 11-year solar activity cycle, to validate our method. Our method outperformed baseline methods and even human expert performance on standard metrics in terms of performance and reliability. The project page can be found at https://keio-smilab25.github.io/DeepSWM.
ZINA: Multimodal Fine-grained Hallucination Detection and Editing
Jun 16, 2025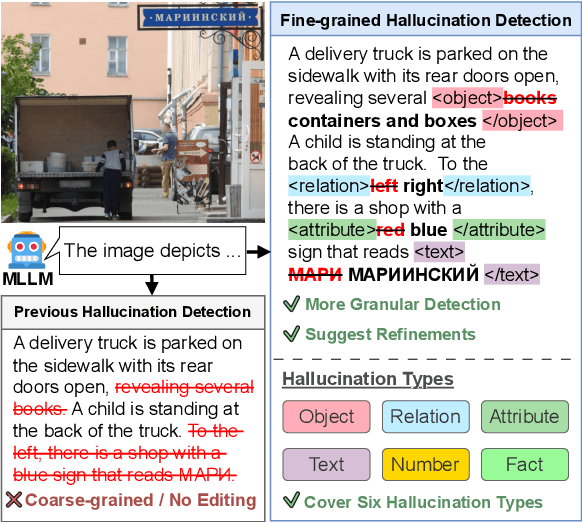

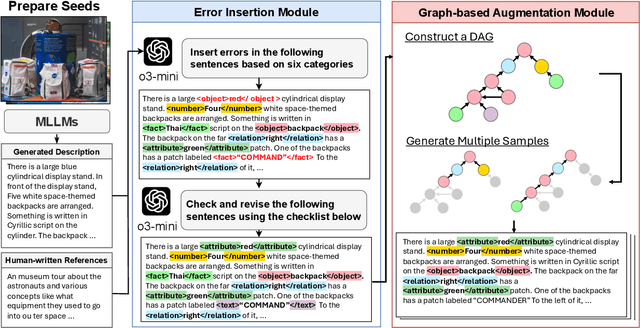
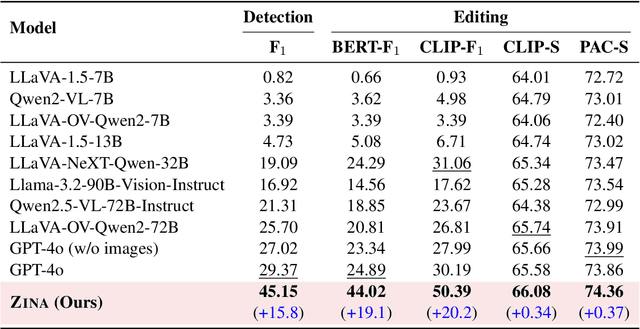
Multimodal Large Language Models (MLLMs) often generate hallucinations, where the output deviates from the visual content. Given that these hallucinations can take diverse forms, detecting hallucinations at a fine-grained level is essential for comprehensive evaluation and analysis. To this end, we propose a novel task of multimodal fine-grained hallucination detection and editing for MLLMs. Moreover, we propose ZINA, a novel method that identifies hallucinated spans at a fine-grained level, classifies their error types into six categories, and suggests appropriate refinements. To train and evaluate models for this task, we constructed VisionHall, a dataset comprising 6.9k outputs from twelve MLLMs manually annotated by 211 annotators, and 20k synthetic samples generated using a graph-based method that captures dependencies among error types. We demonstrated that ZINA outperformed existing methods, including GPT-4o and LLama-3.2, in both detection and editing tasks.
Mobile Manipulation Instruction Generation from Multiple Images with Automatic Metric Enhancement
Jan 28, 2025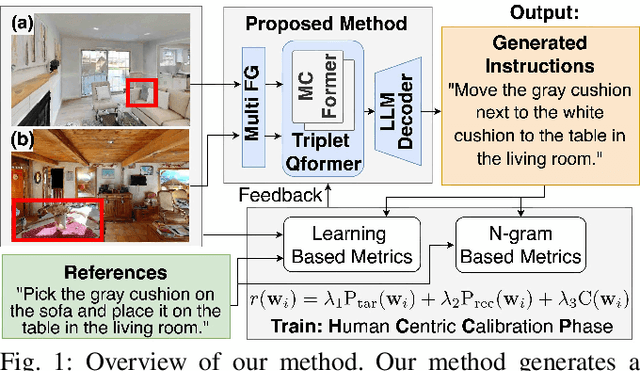
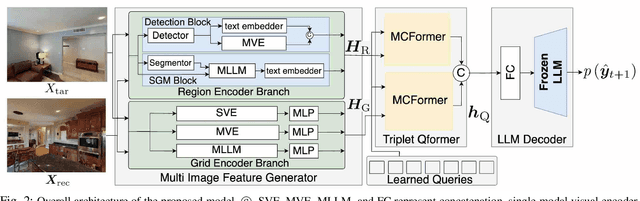
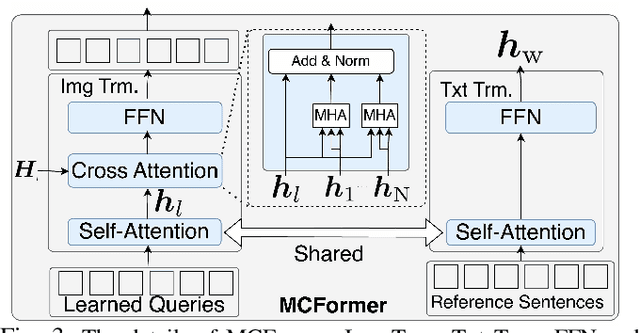

We consider the problem of generating free-form mobile manipulation instructions based on a target object image and receptacle image. Conventional image captioning models are not able to generate appropriate instructions because their architectures are typically optimized for single-image. In this study, we propose a model that handles both the target object and receptacle to generate free-form instruction sentences for mobile manipulation tasks. Moreover, we introduce a novel training method that effectively incorporates the scores from both learning-based and n-gram based automatic evaluation metrics as rewards. This method enables the model to learn the co-occurrence relationships between words and appropriate paraphrases. Results demonstrate that our proposed method outperforms baseline methods including representative multimodal large language models on standard automatic evaluation metrics. Moreover, physical experiments reveal that using our method to augment data on language instructions improves the performance of an existing multimodal language understanding model for mobile manipulation.
Future Success Prediction in Open-Vocabulary Object Manipulation Tasks Based on End-Effector Trajectories
Jan 08, 2025



This study addresses a task designed to predict the future success or failure of open-vocabulary object manipulation. In this task, the model is required to make predictions based on natural language instructions, egocentric view images before manipulation, and the given end-effector trajectories. Conventional methods typically perform success prediction only after the manipulation is executed, limiting their efficiency in executing the entire task sequence. We propose a novel approach that enables the prediction of success or failure by aligning the given trajectories and images with natural language instructions. We introduce Trajectory Encoder to apply learnable weighting to the input trajectories, allowing the model to consider temporal dynamics and interactions between objects and the end effector, improving the model's ability to predict manipulation outcomes accurately. We constructed a dataset based on the RT-1 dataset, a large-scale benchmark for open-vocabulary object manipulation tasks, to evaluate our method. The experimental results show that our method achieved a higher prediction accuracy than baseline approaches.
Task Success Prediction and Open-Vocabulary Object Manipulation
Dec 26, 2024This study addresses a task designed to predict the future success or failure of open-vocabulary object manipulation. In this task, the model is required to make predictions based on natural language instructions, egocentric view images before manipulation, and the given end-effector trajectories. Conventional methods typically perform success prediction only after the manipulation is executed, limiting their efficiency in executing the entire task sequence. We propose a novel approach that enables the prediction of success or failure by aligning the given trajectories and images with natural language instructions. We introduce Trajectory Encoder to apply learnable weighting to the input trajectories, allowing the model to consider temporal dynamics and interactions between objects and the end effector, improving the model's ability to predict manipulation outcomes accurately. We constructed a dataset based on the RT-1 dataset, a large-scale benchmark for open-vocabulary object manipulation tasks, to evaluate our method. The experimental results show that our method achieved a higher prediction accuracy than baseline approaches.