 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Driven Design for Multi-Step Dexterous Manipulation: Insights from Neuroscience
Dec 15, 2024Multi-step dexterous manipulation is a fundamental skill in household scenarios, yet remains an underexplored area in robotics. This paper proposes a modular approach, where each step of the manipulation process is addressed with dedicated policies based on effective modality input, rather than relying on a single end-to-end model. To demonstrate this, a dexterous robotic hand performs a manipulation task involving picking up and rotating a box. Guided by insights from neuroscience, the task is decomposed into three sub-skills, 1)reaching, 2)grasping and lifting, and 3)in-hand rotation, based on the dominant sensory modalities employed in the human brain. Each sub-skill is addressed using distinct methods from a practical perspective: a classical controller, a Vision-Language-Action model, and a reinforcement learning policy with force feedback, respectively. We tested the pipeline on a real robot to demonstrate the feasibility of our approach. The key contribution of this study lies in presenting a neuroscience-inspired, modality-driven methodology for multi-step dexterous manipulation.
Task Success Prediction for Open-Vocabulary Manipulation Based on Multi-Level Aligned Representations
Oct 01, 2024



In this study, we consider the problem of predicting task success for open-vocabulary manipulation by a manipulator, based on instruction sentences and egocentric images before and after manipulation. Conventional approaches, including multimodal large language models (MLLMs), often fail to appropriately understand detailed characteristics of objects and/or subtle changes in the position of objects. We propose Contrastive $\lambda$-Repformer, which predicts task success for table-top manipulation tasks by aligning images with instruction sentences. Our method integrates the following three key types of features into a multi-level aligned representation: features that preserve local image information; features aligned with natural language; and features structured through natural language. This allows the model to focus on important changes by looking at the differences in the representation between two images. We evaluate Contrastive $\lambda$-Repformer on a dataset based on a large-scale standard dataset, the RT-1 dataset, and on a physical robot platform. The results show that our approach outperformed existing approaches including MLLMs. Our best model achieved an improvement of 8.66 points in accuracy compared to the representative MLLM-based model.
APriCoT: Action Primitives based on Contact-state Transition for In-Hand Tool Manipulation
Jul 16, 2024In-hand tool manipulation is an operation that not only manipulates a tool within the hand (i.e., in-hand manipulation) but also achieves a grasp suitable for a task after the manipulation. This study aims to achieve an in-hand tool manipulation skill through deep reinforcement learning. The difficulty of learning the skill arises because this manipulation requires (A) exploring long-term contact-state changes to achieve the desired grasp and (B) highly-varied motions depending on the contact-state transition. (A) leads to a sparsity of a reward on a successful grasp, and (B) requires an RL agent to explore widely within the state-action space to learn highly-varied actions, leading to sample inefficiency. To address these issues, this study proposes Action Primitives based on Contact-state Transition (APriCoT). APriCoT decomposes the manipulation into short-term action primitives by describing the operation as a contact-state transition based on three action representations (detach, crossover, attach). In each action primitive, fingers are required to perform short-term and similar actions. By training a policy for each primitive, we can mitigate the issues from (A) and (B). This study focuses on a fundamental operation as an example of in-hand tool manipulation: rotating an elongated object grasped with a precision grasp by half a turn to achieve the initial grasp. Experimental results demonstrated that ours succeeded in both the rotation and the achievement of the desired grasp, unlike existing studies. Additionally, it was found that the policy was robust to changes in object shape.
Designing Library of Skill-Agents for Hardware-Level Reusability
Mar 04, 2024



To use new robot hardware in a new environment, it is necessary to develop a control program tailored to that specific robot in that environment. Considering the reusability of software among robots is crucial to minimize the effort involved in this process and maximize software reuse across different robots in different environments. This paper proposes a method to remedy this process by considering hardware-level reusability, using Learning-from-observation (LfO) paradigm with a pre-designed skill-agent library. The LfO framework represents the required actions in hardware-independent representations, referred to as task models, from observing human demonstrations, capturing the necessary parameters for the interaction between the environment and the robot. When executing the desired actions from the task models, a set of skill agents is employed to convert the representations into robot commands. This paper focuses on the latter part of the LfO framework, utilizing the set to generate robot actions from the task models, and explores a hardware-independent design approach for these skill agents. These skill agents are described in a hardware-independent manner, considering the relative relationship between the robot's hand position and the environment. As a result, it is possible to execute these actions on robots with different hardware configurations by simply swapping the inverse kinematics solver. This paper, first, defines a necessary and sufficient skill-agent set corresponding to cover all possible actions, and considers the design principles for these skill agents in the library. We provide concrete examples of such skill agents and demonstrate the practicality of using these skill agents by showing that the same representations can be executed on two different robots, Nextage and Fetch, using the proposed skill-agents set.
Polos: Multimodal Metric Learning from Human Feedback for Image Captioning
Feb 28, 2024



Establishing an automatic evaluation metric that closely aligns with human judgments is essential for effectively developing image captioning models. Recent data-driven metrics have demonstrated a stronger correlation with human judgments than classic metrics such as CIDEr; however they lack sufficient capabilities to handle hallucinations and generalize across diverse images and texts partially because they compute scalar similarities merely using embeddings learned from tasks unrelated to image captioning evaluation. In this study, we propose Polos, a supervised automatic evaluation metric for image captioning models. Polos computes scores from multimodal inputs, using a parallel feature extraction mechanism that leverages embeddings trained through large-scale contrastive learning. To train Polos, we introduce Multimodal Metric Learning from Human Feedback (M$^2$LHF), a framework for developing metrics based on human feedback. We constructed the Polaris dataset, which comprises 131K human judgments from 550 evaluators, which is approximately ten times larger than standard datasets. Our approach achieved state-of-the-art performance on Composite, Flickr8K-Expert, Flickr8K-CF, PASCAL-50S, FOIL, and the Polaris dataset, thereby demonstrating its effectiveness and robustness.
Constraint-aware Policy for Compliant Manipulation
Nov 18, 2023Robot manipulation in a physically-constrained environment requires compliant manipulation. Compliant manipulation is a manipulation skill to adjust hand motion based on the force imposed by the environment. Recently, reinforcement learning (RL) has been applied to solve household operations involving compliant manipulation. However, previous RL methods have primarily focused on designing a policy for a specific operation that limits their applicability and requires separate training for every new operation. We propose a constraint-aware policy that is applicable to various unseen manipulations by grouping several manipulations together based on the type of physical constraint involved. The type of physical constraint determines the characteristic of the imposed force direction; thus, a generalized policy is trained in the environment and reward designed on the basis of this characteristic. This paper focuses on two types of physical constraints: prismatic and revolute joints. Experiments demonstrated that the same policy could successfully execute various compliant-manipulation operations, both in the simulation and reality. We believe this study is the first step toward realizing a generalized household-robot.
Tracker: Model-based Reinforcement Learning for Tracking Control of Human Finger Attached with Thin McKibben Muscles
Apr 01, 2023To adopt the soft hand exoskeleton to support activities of daily livings, it is necessary to control finger joints precisely with the exoskeleton. The problem of controlling joints to follow a given trajectory is called the tracking control problem. In this study, we focus on the tracking control problem of a human finger attached with thin McKibben muscles. To achieve precise control with thin McKibben muscles, there are two problems: one is the complex characteristics of the muscles, for example, non-linearity, hysteresis, uncertainties in the real world, and the other is the difficulty in accessing a precise model of the muscles and human fingers. To solve these problems, we adopted DreamerV2, which is a model-based reinforcement learning method, but the target trajectory cannot be generated by the learned model. Therefore, we propose Tracker, which is an extension of DreamerV2 for the tracking control problem. In the experiment, we showed that Tracker can achieve an approximately 81% smaller error than PID for the control of a two-link manipulator that imitates a part of human index finger from the metacarpal bone to the proximal bone. Tracker achieved the control of the third joint of the human index finger with a small error by being trained for approximately 60 minutes. In addition, it took approximately 15 minutes, which is less than the time required for the first training, to achieve almost the same accuracy by fine-tuning the policy pre-trained by the user's finger after taking off and attaching thin McKibben muscles again as the accuracy before taking off.
Task-sequencing Simulator: Integrated Machine Learning to Execution Simulation for Robot Manipulation
Jan 03, 2023



A task-sequencing simulator in robotics manipulation to integrate simulation-for-learning and simulation-for-execution is introduced. Unlike existing machine-learning simulation where a non-decomposed simulation is used to simulate a training scenario, the task-sequencing simulator runs a composed simulation using building blocks. This way, the simulation-for-learning is structured similarly to a multi-step simulation-for-execution. To compose both learning and execution scenarios, a unified trainable-and-composable description of blocks called a concept model is proposed and used. Using the simulator design and concept models, a reusable simulator for learning different tasks, a common-ground system for learning-to-execution, simulation-to-real is achieved and shown.
Task-grasping from human demonstration
Mar 01, 2022



A challenge in robot grasping is to achieve task-grasping which is to select a grasp that is advantageous to the success of tasks before and after grasps. One of the frameworks to address this difficulty is Learning-from-Observation (LfO), which obtains various hints from human demonstrations. This paper solves three issues in the grasping skills in the LfO framework: 1) how to functionally mimic human-demonstrated grasps to robots with limited grasp capability, 2) how to coordinate grasp skills with reaching body mimicking, 3) how to robustly perform grasps under object pose and shape uncertainty. A deep reinforcement learning using contact-web based rewards and domain randomization of approach directions is proposed to achieve such robust mimicked grasping skills. Experiment results show that the trained grasping skills can be applied in an LfO system and executed on a real robot. In addition, it is shown that the trained skill is robust to errors in the object pose and to the uncertainty of the object shape and can be combined with various reach-coordination.
Object affordance as a guide for grasp-type recognition
Feb 27, 2021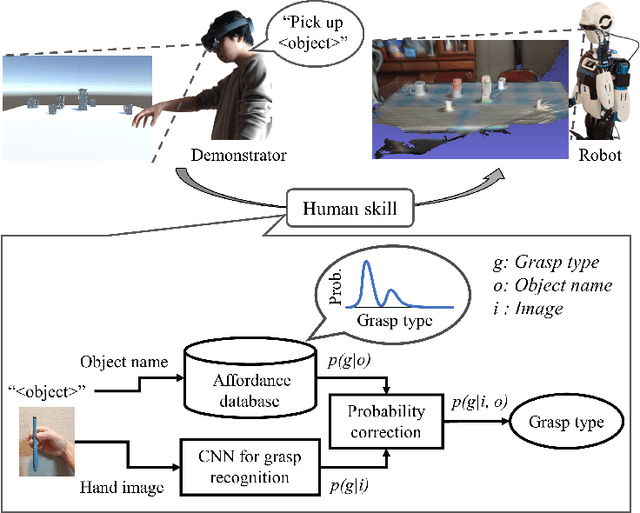
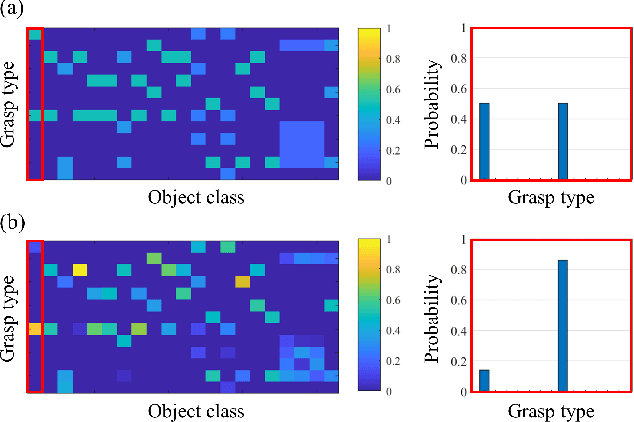

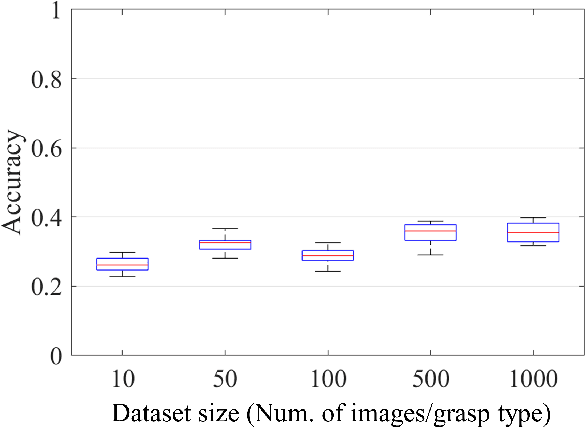
Recognizing human grasping strategies is an important factor in robot teaching as these strategies contain the implicit knowledge necessary to perform a series of manipulations smoothly. This study analyzed the effects of object affordance-a prior distribution of grasp types for each object-on convolutional neural network (CNN)-based grasp-type recognition. To this end, we created datasets of first-person grasping-hand images labeled with grasp types and object names, and tested a recognition pipeline leveraging object affordance. We evaluated scenarios with real and illusory objects to be grasped, to consider a teaching condition in mixed reality where the lack of visual object information can make the CNN recognition challenging. The results show that object affordance guided the CNN in both scenarios, increasing the accuracy by 1) excluding unlikely grasp types from the candidates and 2) enhancing likely grasp types. In addition, the "enhancing effect" was more pronounced with high degrees of grasp-type heterogeneity. These results indicate the effectiveness of object affordance for guiding grasp-type recognition in robot teaching applications.