 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Free Image Captioning Evaluation in Reference-Flexible Settings
Dec 25, 2025We focus on the automatic evaluation of image captions in both reference-based and reference-free settings. Existing metrics based on large language models (LLMs) favor their own generations; therefore, the neutrality is in question. Most LLM-free metrics do not suffer from such an issue, whereas they do not always demonstrate high performance. To address these issues, we propose Pearl, an LLM-free supervised metric for image captioning, which is applicable to both reference-based and reference-free settings. We introduce a novel mechanism that learns the representations of image--caption and caption--caption similarities. Furthermore, we construct a human-annotated dataset for image captioning metrics, that comprises approximately 333k human judgments collected from 2,360 annotators across over 75k images. Pearl outperformed other existing LLM-free metrics on the Composite, Flickr8K-Expert, Flickr8K-CF, Nebula, and FOIL datasets in both reference-based and reference-free settings. Our project page is available at https://pearl.kinsta.page/.
Attention Lattice Adapter: Visual Explanation Generation for Visual Foundation Model
Sep 18, 2025In this study, we consider the problem of generating visual explanations in visual foundation models. Numerous methods have been proposed for this purpose; however, they often cannot be applied to complex models due to their lack of adaptability. To overcome these limitations, we propose a novel explanation generation method in visual foundation models that is aimed at both generating explanations and partially updating model parameters to enhance interpretability. Our approach introduces two novel mechanisms: Attention Lattice Adapter (ALA) and Alternating Epoch Architect (AEA). ALA mechanism simplifies the process by eliminating the need for manual layer selection, thus enhancing the model's adaptability and interpretability. Moreover, the AEA mechanism, which updates ALA's parameters every other epoch, effectively addresses the common issue of overly small attention regions. We evaluated our method on two benchmark datasets, CUB-200-2011 and ImageNet-S. Our results showed that our method outperformed the baseline methods in terms of mean intersection over union (IoU), insertion score, deletion score, and insertion-deletion score on both the CUB-200-2011 and ImageNet-S datasets. Notably, our best model achieved a 53.2-point improvement in mean IoU on the CUB-200-2011 dataset compared with the baselines.
Capturing Fine-Grained Alignments Improves 3D Affordance Detection
Jun 24, 2025In this work, we address the challenge of affordance detection in 3D point clouds, a task that requires effectively capturing fine-grained alignments between point clouds and text. Existing methods often struggle to model such alignments, resulting in limited performance on standard benchmarks. A key limitation of these approaches is their reliance on simple cosine similarity between point cloud and text embeddings, which lacks the expressiveness needed for fine-grained reasoning. To address this limitation, we propose LM-AD, a novel method for affordance detection in 3D point clouds. Moreover, we introduce the Affordance Query Module (AQM), which efficiently captures fine-grained alignment between point clouds and text by leveraging a pretrained language model. We demonstrated that our method outperformed existing approaches in terms of accuracy and mean Intersection over Union on the 3D AffordanceNet dataset.
ZINA: Multimodal Fine-grained Hallucination Detection and Editing
Jun 16, 2025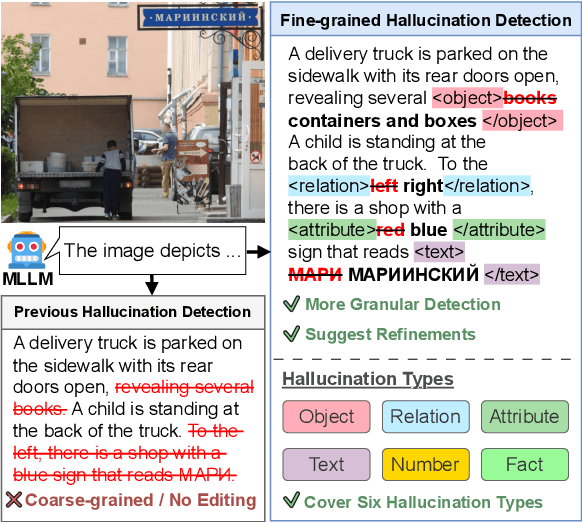

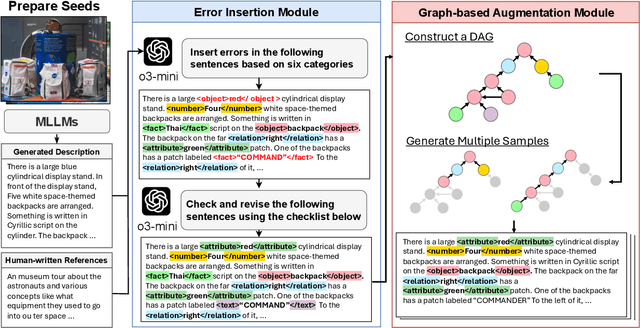
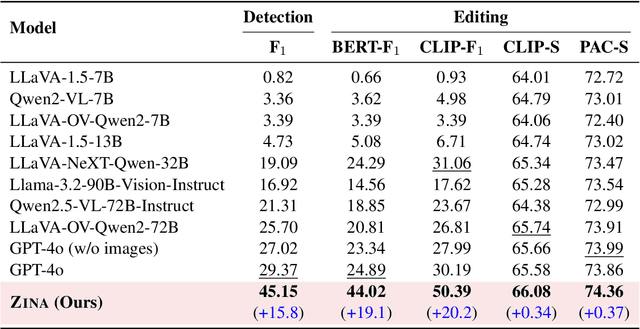
Multimodal Large Language Models (MLLMs) often generate hallucinations, where the output deviates from the visual content. Given that these hallucinations can take diverse forms, detecting hallucinations at a fine-grained level is essential for comprehensive evaluation and analysis. To this end, we propose a novel task of multimodal fine-grained hallucination detection and editing for MLLMs. Moreover, we propose ZINA, a novel method that identifies hallucinated spans at a fine-grained level, classifies their error types into six categories, and suggests appropriate refinements. To train and evaluate models for this task, we constructed VisionHall, a dataset comprising 6.9k outputs from twelve MLLMs manually annotated by 211 annotators, and 20k synthetic samples generated using a graph-based method that captures dependencies among error types. We demonstrated that ZINA outperformed existing methods, including GPT-4o and LLama-3.2, in both detection and editing tasks.
DENEB: A Hallucination-Robust Automatic Evaluation Metric for Image Captioning
Sep 28, 2024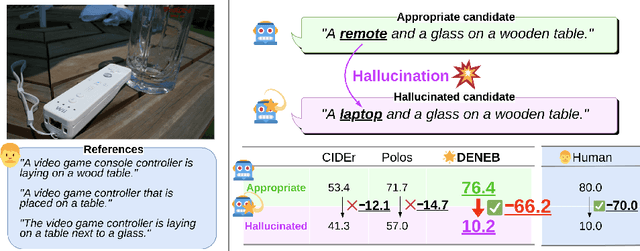



In this work, we address the challenge of developing automatic evaluation metrics for image captioning, with a particular focus on robustness against hallucinations. Existing metrics are often inadequate for handling hallucinations, primarily due to their limited ability to compare candidate captions with multifaceted reference captions. To address this shortcoming, we propose DENEB, a novel supervised automatic evaluation metric specifically robust against hallucinations. DENEB incorporates the Sim-Vec Transformer, a mechanism that processes multiple references simultaneously, thereby efficiently capturing the similarity between an image, a candidate caption, and reference captions. To train DENEB, we construct the diverse and balanced Nebula dataset comprising 32,978 images, paired with human judgments provided by 805 annotators. We demonstrated that DENEB achieves state-of-the-art performance among existing LLM-free metrics on the FOIL, Composite, Flickr8K-Expert, Flickr8K-CF, Nebula, and PASCAL-50S datasets, validating its effectiveness and robustness against hallucinations.
Polos: Multimodal Metric Learning from Human Feedback for Image Captioning
Feb 28, 2024



Establishing an automatic evaluation metric that closely aligns with human judgments is essential for effectively developing image captioning models. Recent data-driven metrics have demonstrated a stronger correlation with human judgments than classic metrics such as CIDEr; however they lack sufficient capabilities to handle hallucinations and generalize across diverse images and texts partially because they compute scalar similarities merely using embeddings learned from tasks unrelated to image captioning evaluation. In this study, we propose Polos, a supervised automatic evaluation metric for image captioning models. Polos computes scores from multimodal inputs, using a parallel feature extraction mechanism that leverages embeddings trained through large-scale contrastive learning. To train Polos, we introduce Multimodal Metric Learning from Human Feedback (M$^2$LHF), a framework for developing metrics based on human feedback. We constructed the Polaris dataset, which comprises 131K human judgments from 550 evaluators, which is approximately ten times larger than standard datasets. Our approach achieved state-of-the-art performance on Composite, Flickr8K-Expert, Flickr8K-CF, PASCAL-50S, FOIL, and the Polaris dataset, thereby demonstrating its effectiveness and robustness.
DialMAT: Dialogue-Enabled Transformer with Moment-Based Adversarial Training
Nov 12, 2023This paper focuses on the DialFRED task, which is the task of embodied instruction following in a setting where an agent can actively ask questions about the task. To address this task, we propose DialMAT. DialMAT introduces Moment-based Adversarial Training, which incorporates adversarial perturbations into the latent space of language, image, and action. Additionally, it introduces a crossmodal parallel feature extraction mechanism that applies foundation models to both language and image. We evaluated our model using a dataset constructed from the DialFRED dataset and demonstrated superior performance compared to the baseline method in terms of success rate and path weighted success rate. The model secured the top position in the DialFRED Challenge, which took place at the CVPR 2023 Embodied AI workshop.
JaSPICE: Automatic Evaluation Metric Using Predicate-Argument Structures for Image Captioning Models
Nov 07, 2023Image captioning studies heavily rely on automatic evaluation metrics such as BLEU and METEOR. However, such n-gram-based metrics have been shown to correlate poorly with human evaluation, leading to the proposal of alternative metrics such as SPICE for English; however, no equivalent metrics have been established for other languages. Therefore, in this study, we propose an automatic evaluation metric called JaSPICE, which evaluates Japanese captions based on scene graphs. The proposed method generates a scene graph from dependencies and the predicate-argument structure, and extends the graph using synonyms. We conducted experiments employing 10 image captioning models trained on STAIR Captions and PFN-PIC and constructed the Shichimi dataset, which contains 103,170 human evaluations. The results showed that our metric outperformed the baseline metrics for the correlation coefficient with the human evaluation.
Multimodal Diffusion Segmentation Model for Object Segmentation from Manipulation Instructions
Jul 17, 2023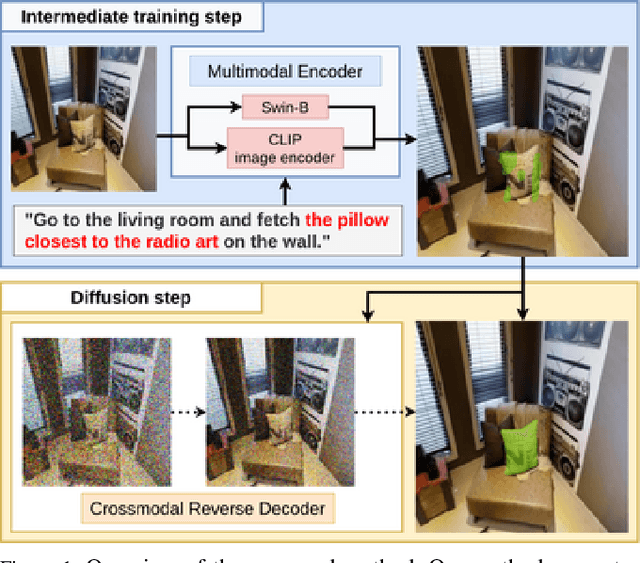

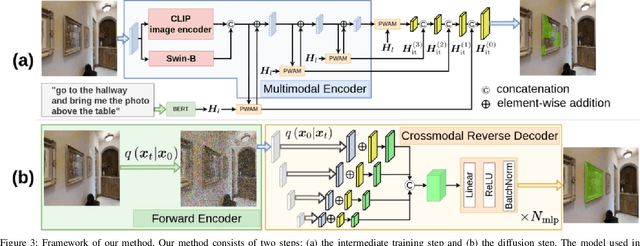

In this study, we aim to develop a model that comprehends a natural language instruction (e.g., "Go to the living room and get the nearest pillow to the radio art on the wall") and generates a segmentation mask for the target everyday object. The task is challenging because it requires (1) the understanding of the referring expressions for multiple objects in the instruction, (2) the prediction of the target phrase of the sentence among the multiple phrases, and (3) the generation of pixel-wise segmentation masks rather than bounding boxes. Studies have been conducted on languagebased segmentation methods; however, they sometimes mask irrelevant regions for complex sentences. In this paper, we propose the Multimodal Diffusion Segmentation Model (MDSM), which generates a mask in the first stage and refines it in the second stage. We introduce a crossmodal parallel feature extraction mechanism and extend diffusion probabilistic models to handle crossmodal features. To validate our model, we built a new dataset based on the well-known Matterport3D and REVERIE datasets. This dataset consists of instructions with complex referring expressions accompanied by real indoor environmental images that feature various target objects, in addition to pixel-wise segmentation masks. The performance of MDSM surpassed that of the baseline method by a large margin of +10.13 mean IoU.