 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialMAT: Dialogue-Enabled Transformer with Moment-Based Adversarial Training
Nov 12, 2023This paper focuses on the DialFRED task, which is the task of embodied instruction following in a setting where an agent can actively ask questions about the task. To address this task, we propose DialMAT. DialMAT introduces Moment-based Adversarial Training, which incorporates adversarial perturbations into the latent space of language, image, and action. Additionally, it introduces a crossmodal parallel feature extraction mechanism that applies foundation models to both language and image. We evaluated our model using a dataset constructed from the DialFRED dataset and demonstrated superior performance compared to the baseline method in terms of success rate and path weighted success rate. The model secured the top position in the DialFRED Challenge, which took place at the CVPR 2023 Embodied AI workshop.
Multimodal Diffusion Segmentation Model for Object Segmentation from Manipulation Instructions
Jul 17, 2023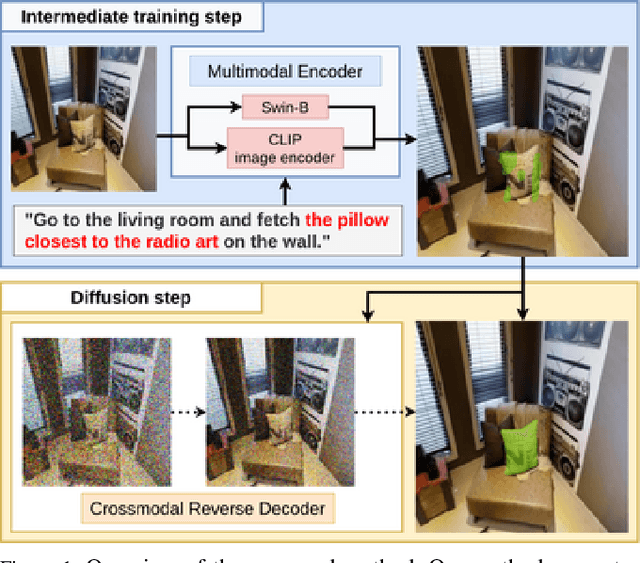

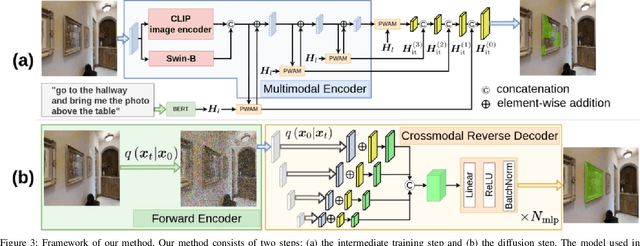

In this study, we aim to develop a model that comprehends a natural language instruction (e.g., "Go to the living room and get the nearest pillow to the radio art on the wall") and generates a segmentation mask for the target everyday object. The task is challenging because it requires (1) the understanding of the referring expressions for multiple objects in the instruction, (2) the prediction of the target phrase of the sentence among the multiple phrases, and (3) the generation of pixel-wise segmentation masks rather than bounding boxes. Studies have been conducted on languagebased segmentation methods; however, they sometimes mask irrelevant regions for complex sentences. In this paper, we propose the Multimodal Diffusion Segmentation Model (MDSM), which generates a mask in the first stage and refines it in the second stage. We introduce a crossmodal parallel feature extraction mechanism and extend diffusion probabilistic models to handle crossmodal features. To validate our model, we built a new dataset based on the well-known Matterport3D and REVERIE datasets. This dataset consists of instructions with complex referring expressions accompanied by real indoor environmental images that feature various target objects, in addition to pixel-wise segmentation masks. The performance of MDSM surpassed that of the baseline method by a large margin of +10.13 mean IoU.