 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Diffusion Segmentation Model for Object Segmentation from Manipulation Instructions
Jul 17, 2023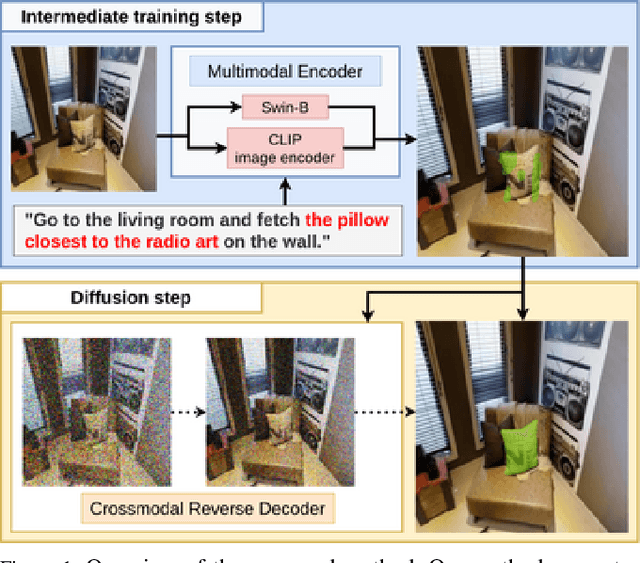

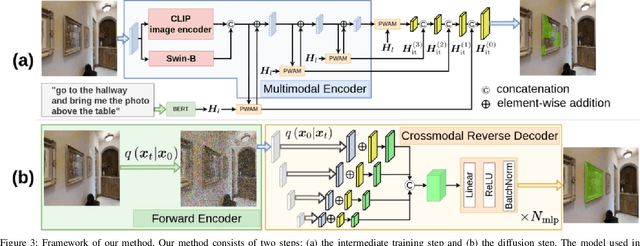

In this study, we aim to develop a model that comprehends a natural language instruction (e.g., "Go to the living room and get the nearest pillow to the radio art on the wall") and generates a segmentation mask for the target everyday object. The task is challenging because it requires (1) the understanding of the referring expressions for multiple objects in the instruction, (2) the prediction of the target phrase of the sentence among the multiple phrases, and (3) the generation of pixel-wise segmentation masks rather than bounding boxes. Studies have been conducted on languagebased segmentation methods; however, they sometimes mask irrelevant regions for complex sentences. In this paper, we propose the Multimodal Diffusion Segmentation Model (MDSM), which generates a mask in the first stage and refines it in the second stage. We introduce a crossmodal parallel feature extraction mechanism and extend diffusion probabilistic models to handle crossmodal features. To validate our model, we built a new dataset based on the well-known Matterport3D and REVERIE datasets. This dataset consists of instructions with complex referring expressions accompanied by real indoor environmental images that feature various target objects, in addition to pixel-wise segmentation masks. The performance of MDSM surpassed that of the baseline method by a large margin of +10.13 mean IoU.
Switching Head-Tail Funnel UNITER for Dual Referring Expression Comprehension with Fetch-and-Carry Tasks
Jul 14, 2023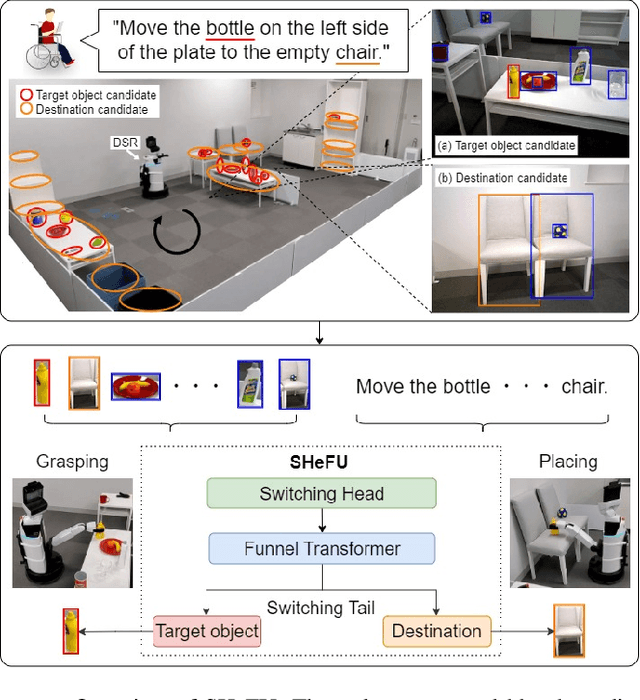
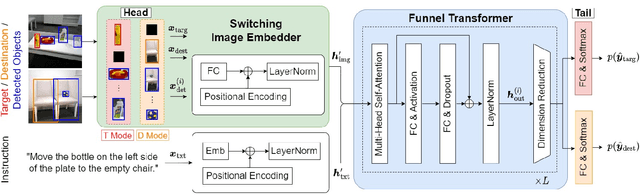
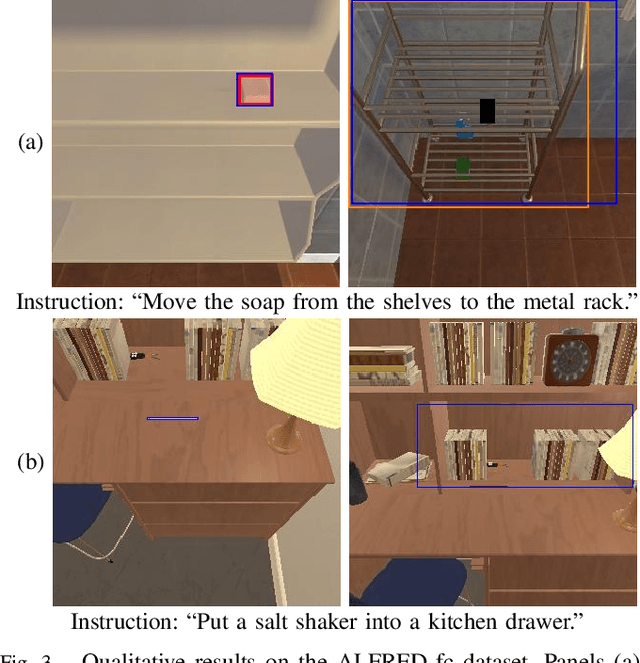

This paper describes a domestic service robot (DSR) that fetches everyday objects and carries them to specified destinations according to free-form natural language instructions. Given an instruction such as "Move the bottle on the left side of the plate to the empty chair," the DSR is expected to identify the bottle and the chair from multiple candidates in the environment and carry the target object to the destination. Most of the existing multimodal language understanding methods are impractical in terms of computational complexity because they require inferences for all combinations of target object candidates and destination candidates. We propose Switching Head-Tail Funnel UNITER, which solves the task by predicting the target object and the destination individually using a single model. Our method is validated on a newly-built dataset consisting of object manipulation instructions and semi photo-realistic images captured in a standard Embodied AI simulator. The results show that our method outperforms the baseline method in terms of language comprehension accuracy. Furthermore, we conduct physical experiments in which a DSR delivers standardized everyday objects in a standardized domestic environment as requested by instructions with referring expressions. The experimental results show that the object grasping and placing actions are achieved with success rates of more than 90%.