 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Scale Cross-Attentional Transformer for Rearrangement Target Detection
Jul 06, 2024Rearranging objects (e.g. vase, door) back in their original positions is one of the most fundamental skills for domestic service robots (DSRs). In rearrangement tasks, it is crucial to detect the objects that need to be rearranged according to the goal and current states. In this study, we focus on Rearrangement Target Detection (RTD), where the model generates a change mask for objects that should be rearranged. Although many studies have been conducted in the field of Scene Change Detection (SCD), most SCD methods often fail to segment objects with complex shapes and fail to detect the change in the angle of objects that can be opened or closed. In this study, we propose a Co-Scale Cross-Attentional Transformer for RTD. We introduce the Serial Encoder which consists of a sequence of serial blocks and the Cross-Attentional Encoder which models the relationship between the goal and current states. We built a new dataset consisting of RGB images and change masks regarding the goal and current states. We validated our method on the dataset and the results demonstrated that our method outperformed baseline methods on $F_1$-score and mean IoU.
Switching Head-Tail Funnel UNITER for Dual Referring Expression Comprehension with Fetch-and-Carry Tasks
Jul 14, 2023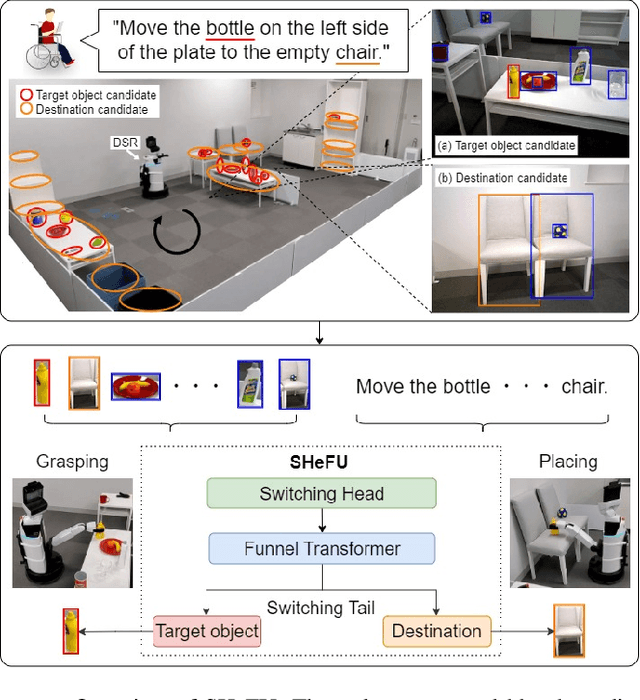
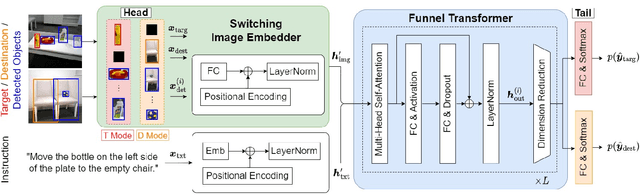

This paper describes a domestic service robot (DSR) that fetches everyday objects and carries them to specified destinations according to free-form natural language instructions. Given an instruction such as "Move the bottle on the left side of the plate to the empty chair," the DSR is expected to identify the bottle and the chair from multiple candidates in the environment and carry the target object to the destination. Most of the existing multimodal language understanding methods are impractical in terms of computational complexity because they require inferences for all combinations of target object candidates and destination candidates. We propose Switching Head-Tail Funnel UNITER, which solves the task by predicting the target object and the destination individually using a single model. Our method is validated on a newly-built dataset consisting of object manipulation instructions and semi photo-realistic images captured in a standard Embodied AI simulator. The results show that our method outperforms the baseline method in terms of language comprehension accuracy. Furthermore, we conduct physical experiments in which a DSR delivers standardized everyday objects in a standardized domestic environment as requested by instructions with referring expressions. The experimental results show that the object grasping and placing actions are achieved with success rates of more than 90%.
Prototypical Contrastive Transfer Learning for Multimodal Language Understanding
Jul 12, 2023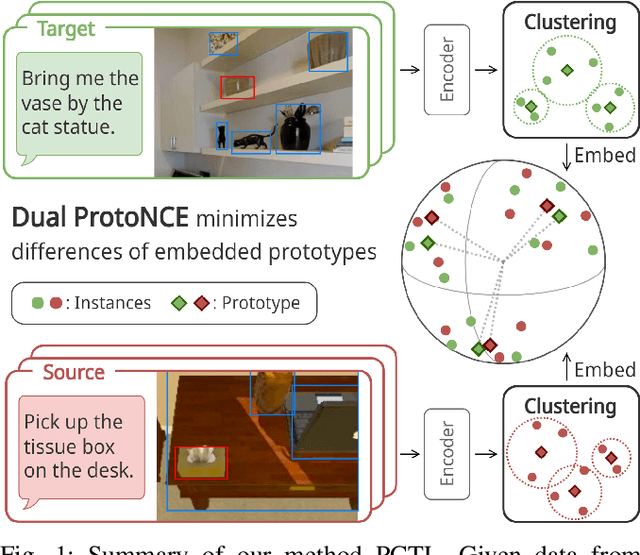

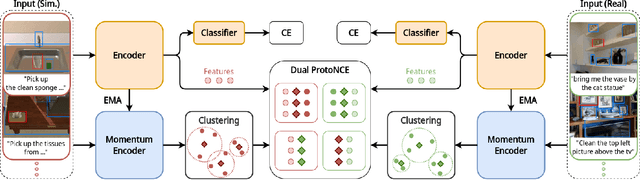

Although domestic service robots are expected to assist individuals who require support, they cannot currently interact smoothly with people through natural language. For example, given the instruction "Bring me a bottle from the kitchen," it is difficult for such robots to specify the bottle in an indoor environment. Most conventional models have been trained on real-world datasets that are labor-intensive to collect, and they have not fully leveraged simulation data through a transfer learning framework. In this study, we propose a novel transfer learning approach for multimodal language understanding called Prototypical Contrastive Transfer Learning (PCTL), which uses a new contrastive loss called Dual ProtoNCE. We introduce PCTL to the task of identifying target objects in domestic environments according to free-form natural language instructions. To validate PCTL, we built new real-world and simulation datasets. Our experiment demonstrated that PCTL outperformed existing methods. Specifically, PCTL achieved an accuracy of 78.1%, whereas simple fine-tuning achieved an accuracy of 73.4%.
Moment-based Adversarial Training for Embodied Language Comprehension
Apr 02, 2022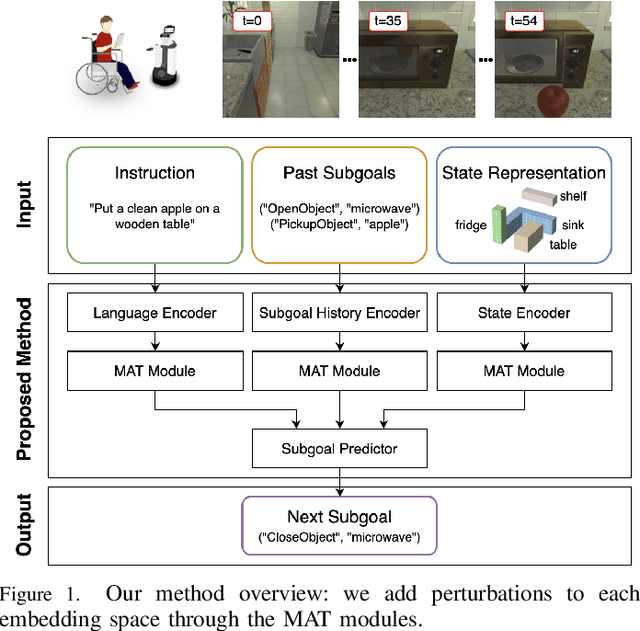

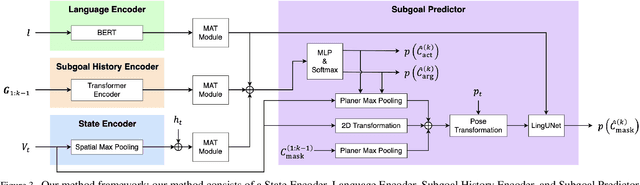

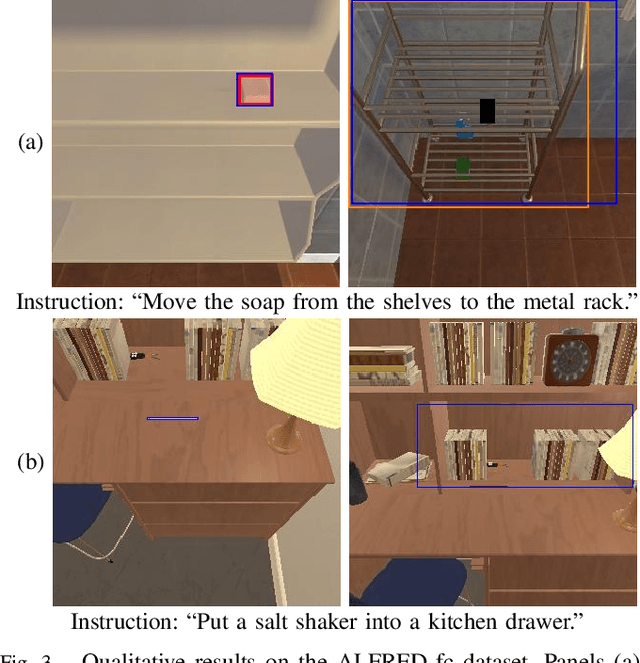
In this paper, we focus on a vision-and-language task in which a robot is instructed to execute household tasks. Given an instruction such as "Rinse off a mug and place it in the coffee maker," the robot is required to locate the mug, wash it, and put it in the coffee maker. This is challenging because the robot needs to break down the instruction sentences into subgoals and execute them in the correct order. On the ALFRED benchmark, the performance of state-of-the-art methods is still far lower than that of humans. This is partially because existing methods sometimes fail to infer subgoals that are not explicitly specified in the instruction sentences. We propose Moment-based Adversarial Training (MAT), which uses two types of moments for perturbation updates in adversarial training. We introduce MAT to the embedding spaces of the instruction, subgoals, and state representations to handle their varieties. We validated our method on the ALFRED benchmark, and the results demonstrated that our method outperformed the baseline method for all the metrics on the benchmark.
Target-dependent UNITER: A Transformer-Based Multimodal Language Comprehension Model for Domestic Service Robots
Jul 02, 2021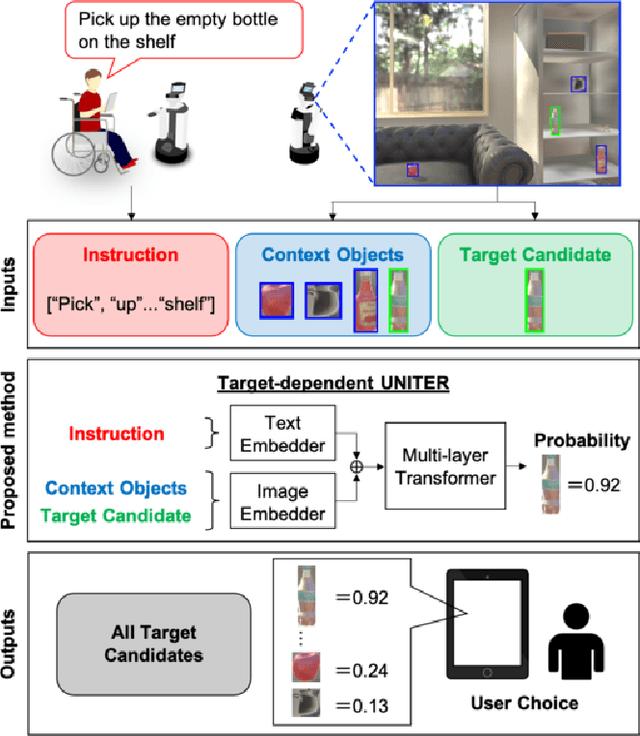

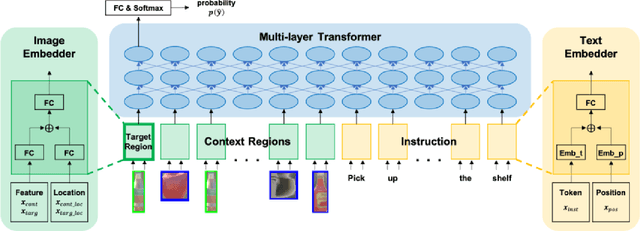
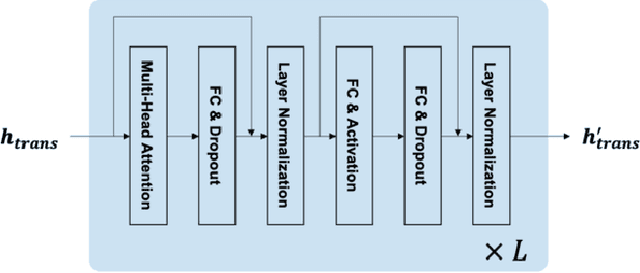
Currently, domestic service robots have an insufficient ability to interact naturally through language. This is because understanding human instructions is complicated by various ambiguities and missing information. In existing methods, the referring expressions that specify the relationships between objects are insufficiently modeled. In this paper, we propose Target-dependent UNITER, which learns the relationship between the target object and other objects directly by focusing on the relevant regions within an image, rather than the whole image. Our method is an extension of the UNITER-based Transformer that can be pretrained on general-purpose datasets. We extend the UNITER approach by introducing a new architecture for handling the target candidates. Our model is validated on two standard datasets, and the results show that Target-dependent UNITER outperforms the baseline method in terms of classification accuracy.