 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-dependent UNITER: A Transformer-Based Multimodal Language Comprehension Model for Domestic Service Robots
Paper and Code
Jul 02, 2021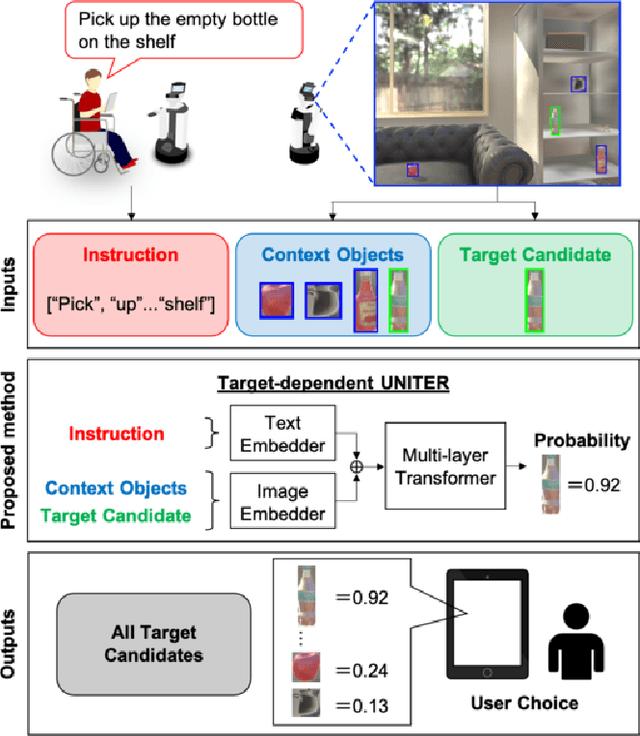

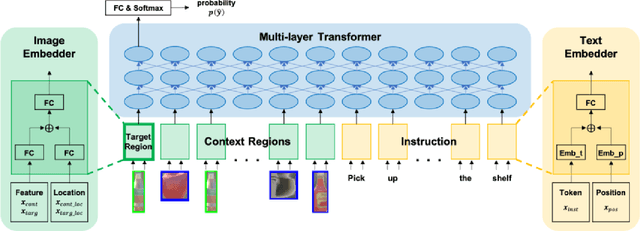
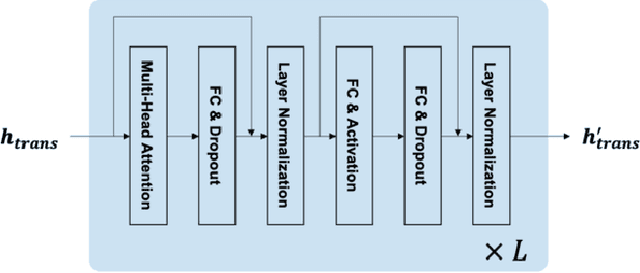
Currently, domestic service robots have an insufficient ability to interact naturally through language. This is because understanding human instructions is complicated by various ambiguities and missing information. In existing methods, the referring expressions that specify the relationships between objects are insufficiently modeled. In this paper, we propose Target-dependent UNITER, which learns the relationship between the target object and other objects directly by focusing on the relevant regions within an image, rather than the whole image. Our method is an extension of the UNITER-based Transformer that can be pretrained on general-purpose datasets. We extend the UNITER approach by introducing a new architecture for handling the target candidates. Our model is validated on two standard datasets, and the results show that Target-dependent UNITER outperforms the baseline method in terms of classification accuracy.