 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLILAC: Language-Conditioned Object-Centric Optical Flow for Open-Loop Trajectory Generation
Mar 26, 2026We address language-conditioned robotic manipulation using flow-based trajectory generation, which enables training on human and web videos of object manipulation and requires only minimal embodiment-specific data. This task is challenging, as object trajectory generation from pre-manipulation images and natural language instructions requires appropriate instruction-flow alignment. To tackle this challenge, we propose the flow-based Language Instruction-guided open-Loop ACtion generator (LILAC). This flow-based Vision-Language-Action model (VLA) generates object-centric 2D optical flow from an RGB image and a natural language instruction, and converts the flow into a 6-DoF manipulator trajectory. LILAC incorporates two key components: Semantic Alignment Loss, which strengthens language conditioning to generate instruction-aligned optical flow, and Prompt-Conditioned Cross-Modal Adapter, which aligns learned visual prompts with image and text features to provide rich cues for flow generation. Experimentally, our method outperformed existing approaches in generated flow quality across multiple benchmarks. Furthermore, in physical object manipulation experiments using free-form instructions, LILAC demonstrated a superior task success rate compared to existing methods. The project page is available at https://lilac-75srg.kinsta.page/.
AnoleVLA: Lightweight Vision-Language-Action Model with Deep State Space Models for Mobile Manipulation
Mar 16, 2026In this study, we address the problem of language-guided robotic manipulation, where a robot is required to manipulate a wide range of objects based on visual observations and natural language instructions. This task is essential for service robots that operate in human environments, and requires safety, efficiency, and task-level generality. Although Vision-Language-Action models (VLAs) have demonstrated strong performance for this task, their deployment in resource-constrained environments remains challenging because of the computational cost of standard transformer backbones. To overcome this limitation, we propose AnoleVLA, a lightweight VLA that uses a deep state space model to process multimodal sequences efficiently. The model leverages its lightweight and fast sequential state modeling to process visual and textual inputs, which allows the robot to generate trajectories efficiently. We evaluated the proposed method in both simulation and physical experiments. Notably, in real-world evaluations, AnoleVLA outperformed a representative large-scale VLA by 21 points for the task success rate while achieving an inference speed approximately three times faster.
Pre-Manipulation Alignment Prediction with Parallel Deep State-Space and Transformer Models
Sep 17, 2025In this work, we address the problem of predicting the future success of open-vocabulary object manipulation tasks. Conventional approaches typically determine success or failure after the action has been carried out. However, they make it difficult to prevent potential hazards and rely on failures to trigger replanning, thereby reducing the efficiency of object manipulation sequences. To overcome these challenges, we propose a model, which predicts the alignment between a pre-manipulation egocentric image with the planned trajectory and a given natural language instruction. We introduce a Multi-Level Trajectory Fusion module, which employs a state-of-the-art deep state-space model and a transformer encoder in parallel to capture multi-level time-series self-correlation within the end effector trajectory. Our experimental results indicate that the proposed method outperformed existing methods, including foundation models.
Mobile Manipulation Instruction Generation from Multiple Images with Automatic Metric Enhancement
Jan 28, 2025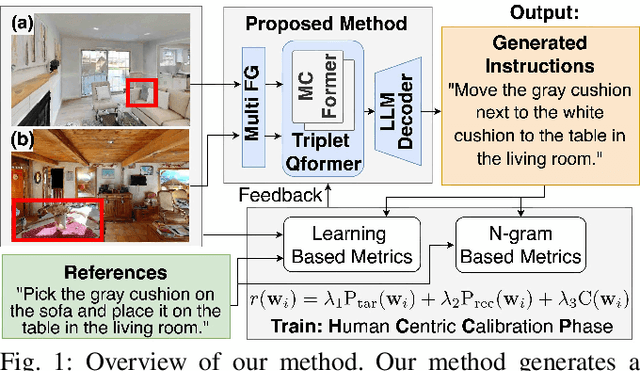
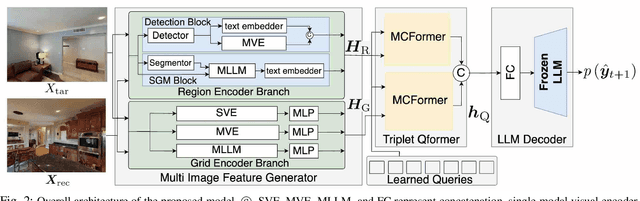
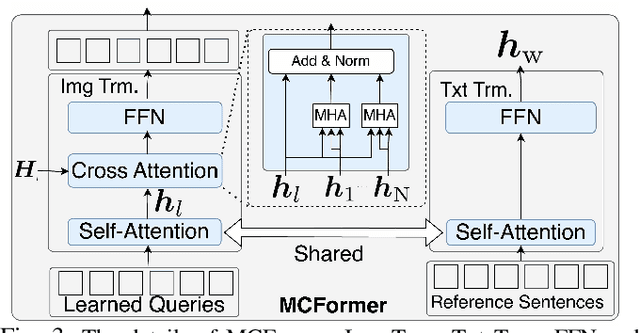

We consider the problem of generating free-form mobile manipulation instructions based on a target object image and receptacle image. Conventional image captioning models are not able to generate appropriate instructions because their architectures are typically optimized for single-image. In this study, we propose a model that handles both the target object and receptacle to generate free-form instruction sentences for mobile manipulation tasks. Moreover, we introduce a novel training method that effectively incorporates the scores from both learning-based and n-gram based automatic evaluation metrics as rewards. This method enables the model to learn the co-occurrence relationships between words and appropriate paraphrases. Results demonstrate that our proposed method outperforms baseline methods including representative multimodal large language models on standard automatic evaluation metrics. Moreover, physical experiments reveal that using our method to augment data on language instructions improves the performance of an existing multimodal language understanding model for mobile manipulation.
Future Success Prediction in Open-Vocabulary Object Manipulation Tasks Based on End-Effector Trajectories
Jan 08, 2025



This study addresses a task designed to predict the future success or failure of open-vocabulary object manipulation. In this task, the model is required to make predictions based on natural language instructions, egocentric view images before manipulation, and the given end-effector trajectories. Conventional methods typically perform success prediction only after the manipulation is executed, limiting their efficiency in executing the entire task sequence. We propose a novel approach that enables the prediction of success or failure by aligning the given trajectories and images with natural language instructions. We introduce Trajectory Encoder to apply learnable weighting to the input trajectories, allowing the model to consider temporal dynamics and interactions between objects and the end effector, improving the model's ability to predict manipulation outcomes accurately. We constructed a dataset based on the RT-1 dataset, a large-scale benchmark for open-vocabulary object manipulation tasks, to evaluate our method. The experimental results show that our method achieved a higher prediction accuracy than baseline approaches.
Task Success Prediction and Open-Vocabulary Object Manipulation
Dec 26, 2024This study addresses a task designed to predict the future success or failure of open-vocabulary object manipulation. In this task, the model is required to make predictions based on natural language instructions, egocentric view images before manipulation, and the given end-effector trajectories. Conventional methods typically perform success prediction only after the manipulation is executed, limiting their efficiency in executing the entire task sequence. We propose a novel approach that enables the prediction of success or failure by aligning the given trajectories and images with natural language instructions. We introduce Trajectory Encoder to apply learnable weighting to the input trajectories, allowing the model to consider temporal dynamics and interactions between objects and the end effector, improving the model's ability to predict manipulation outcomes accurately. We constructed a dataset based on the RT-1 dataset, a large-scale benchmark for open-vocabulary object manipulation tasks, to evaluate our method. The experimental results show that our method achieved a higher prediction accuracy than baseline approaches.
Task Success Prediction for Open-Vocabulary Manipulation Based on Multi-Level Aligned Representations
Oct 01, 2024



In this study, we consider the problem of predicting task success for open-vocabulary manipulation by a manipulator, based on instruction sentences and egocentric images before and after manipulation. Conventional approaches, including multimodal large language models (MLLMs), often fail to appropriately understand detailed characteristics of objects and/or subtle changes in the position of objects. We propose Contrastive $\lambda$-Repformer, which predicts task success for table-top manipulation tasks by aligning images with instruction sentences. Our method integrates the following three key types of features into a multi-level aligned representation: features that preserve local image information; features aligned with natural language; and features structured through natural language. This allows the model to focus on important changes by looking at the differences in the representation between two images. We evaluate Contrastive $\lambda$-Repformer on a dataset based on a large-scale standard dataset, the RT-1 dataset, and on a physical robot platform. The results show that our approach outperformed existing approaches including MLLMs. Our best model achieved an improvement of 8.66 points in accuracy compared to the representative MLLM-based model.
Nearest Neighbor Future Captioning: Generating Descriptions for Possible Collisions in Object Placement Tasks
Jul 18, 2024



Domestic service robots (DSRs) that support people in everyday environments have been widely investigated. However, their ability to predict and describe future risks resulting from their own actions remains insufficient. In this study, we focus on the linguistic explainability of DSRs. Most existing methods do not explicitly model the region of possible collisions; thus, they do not properly generate descriptions of these regions. In this paper, we propose the Nearest Neighbor Future Captioning Model that introduces the Nearest Neighbor Language Model for future captioning of possible collisions, which enhances the model output with a nearest neighbors retrieval mechanism. Furthermore, we introduce the Collision Attention Module that attends regions of possible collisions, which enables our model to generate descriptions that adequately reflect the objects associated with possible collisions. To validate our method, we constructed a new dataset containing samples of collisions that can occur when a DSR places an object in a simulation environment. The experimental results demonstrated that our method outperformed baseline methods, based on the standard metrics. In particular, on CIDEr-D, the baseline method obtained 25.09 points, whereas our method obtained 33.08 points.
Object Segmentation from Open-Vocabulary Manipulation Instructions Based on Optimal Transport Polygon Matching with Multimodal Foundation Models
Jul 01, 2024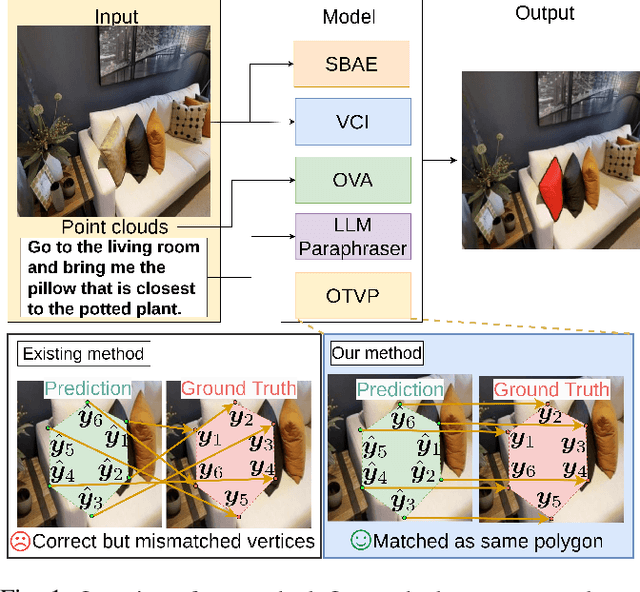
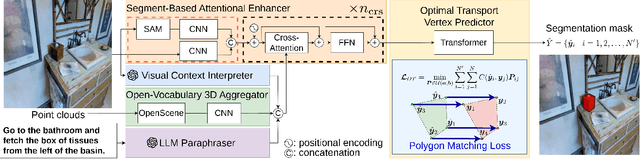
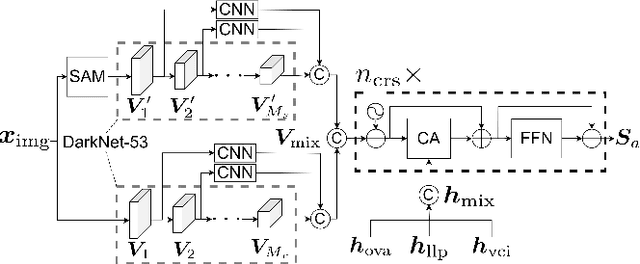

We consider the task of generating segmentation masks for the target object from an object manipulation instruction, which allows users to give open vocabulary instructions to domestic service robots. Conventional segmentation generation approaches often fail to account for objects outside the camera's field of view and cases in which the order of vertices differs but still represents the same polygon, which leads to erroneous mask generation. In this study, we propose a novel method that generates segmentation masks from open vocabulary instructions. We implement a novel loss function using optimal transport to prevent significant loss where the order of vertices differs but still represents the same polygon. To evaluate our approach, we constructed a new dataset based on the REVERIE dataset and Matterport3D dataset. The results demonstrated the effectiveness of the proposed method compared with existing mask generation methods. Remarkably, our best model achieved a +16.32% improvement on the dataset compared with a representative polygon-based method.
Learning-To-Rank Approach for Identifying Everyday Objects Using a Physical-World Search Engine
Dec 26, 2023Domestic service robots offer a solution to the increasing demand for daily care and support. A human-in-the-loop approach that combines automation and operator intervention is considered to be a realistic approach to their use in society. Therefore, we focus on the task of retrieving target objects from open-vocabulary user instructions in a human-in-the-loop setting, which we define as the learning-to-rank physical objects (LTRPO) task. For example, given the instruction "Please go to the dining room which has a round table. Pick up the bottle on it," the model is required to output a ranked list of target objects that the operator/user can select. In this paper, we propose MultiRankIt, which is a novel approach for the LTRPO task. MultiRankIt introduces the Crossmodal Noun Phrase Encoder to model the relationship between phrases that contain referring expressions and the target bounding box, and the Crossmodal Region Feature Encoder to model the relationship between the target object and multiple images of its surrounding contextual environment. Additionally, we built a new dataset for the LTRPO task that consists of instructions with complex referring expressions accompanied by real indoor environmental images that feature various target objects. We validated our model on the dataset and it outperformed the baseline method in terms of the mean reciprocal rank and recall@k. Furthermore, we conducted physical experiments in a setting where a domestic service robot retrieved everyday objects in a standardized domestic environment, based on users' instruction in a human--in--the--loop setting. The experimental results demonstrate that the success rate for object retrieval achieved 80%. Our code is available at https://github.com/keio-smilab23/MultiRankIt.