 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Free Image Captioning Evaluation in Reference-Flexible Settings
Dec 25, 2025We focus on the automatic evaluation of image captions in both reference-based and reference-free settings. Existing metrics based on large language models (LLMs) favor their own generations; therefore, the neutrality is in question. Most LLM-free metrics do not suffer from such an issue, whereas they do not always demonstrate high performance. To address these issues, we propose Pearl, an LLM-free supervised metric for image captioning, which is applicable to both reference-based and reference-free settings. We introduce a novel mechanism that learns the representations of image--caption and caption--caption similarities. Furthermore, we construct a human-annotated dataset for image captioning metrics, that comprises approximately 333k human judgments collected from 2,360 annotators across over 75k images. Pearl outperformed other existing LLM-free metrics on the Composite, Flickr8K-Expert, Flickr8K-CF, Nebula, and FOIL datasets in both reference-based and reference-free settings. Our project page is available at https://pearl.kinsta.page/.
Task Success Prediction for Open-Vocabulary Manipulation Based on Multi-Level Aligned Representations
Oct 01, 2024



In this study, we consider the problem of predicting task success for open-vocabulary manipulation by a manipulator, based on instruction sentences and egocentric images before and after manipulation. Conventional approaches, including multimodal large language models (MLLMs), often fail to appropriately understand detailed characteristics of objects and/or subtle changes in the position of objects. We propose Contrastive $\lambda$-Repformer, which predicts task success for table-top manipulation tasks by aligning images with instruction sentences. Our method integrates the following three key types of features into a multi-level aligned representation: features that preserve local image information; features aligned with natural language; and features structured through natural language. This allows the model to focus on important changes by looking at the differences in the representation between two images. We evaluate Contrastive $\lambda$-Repformer on a dataset based on a large-scale standard dataset, the RT-1 dataset, and on a physical robot platform. The results show that our approach outperformed existing approaches including MLLMs. Our best model achieved an improvement of 8.66 points in accuracy compared to the representative MLLM-based model.
Layer-Wise Relevance Propagation with Conservation Property for ResNet
Jul 12, 2024



The transparent formulation of explanation methods is essential for elucidating the predictions of neural networks, which are typically black-box models. Layer-wise Relevance Propagation (LRP) is a well-established method that transparently traces the flow of a model's prediction backward through its architecture by backpropagating relevance scores. However, the conventional LRP does not fully consider the existence of skip connections, and thus its application to the widely used ResNet architecture has not been thoroughly explored. In this study, we extend LRP to ResNet models by introducing Relevance Splitting at points where the output from a skip connection converges with that from a residual block. Our formulation guarantees the conservation property throughout the process, thereby preserving the integrity of the generated explanations. To evaluate the effectiveness of our approach, we conduct experiments on ImageNet and the Caltech-UCSD Birds-200-2011 dataset. Our method achieves superior performance to that of baseline methods on standard evaluation metrics such as the Insertion-Deletion score while maintaining its conservation property. We will release our code for further research at https://5ei74r0.github.io/lrp-for-resnet.page/
Prototypical Contrastive Transfer Learning for Multimodal Language Understanding
Jul 12, 2023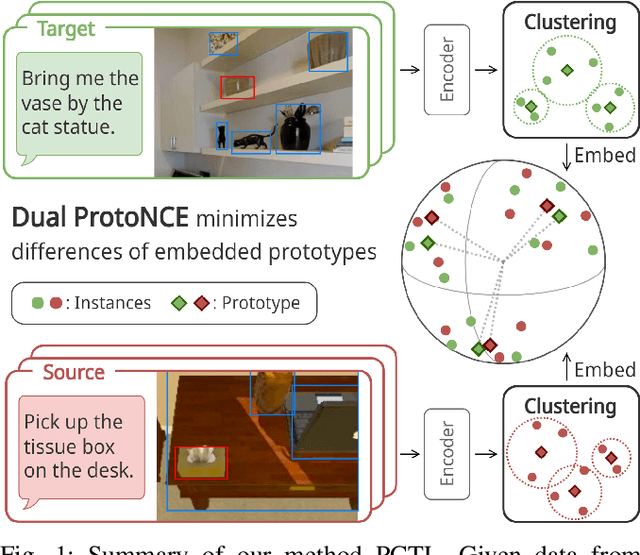

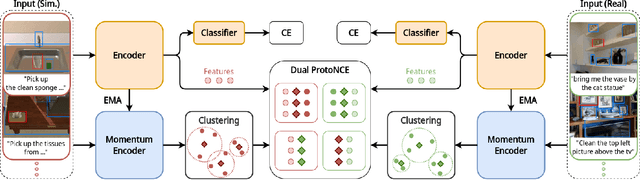

Although domestic service robots are expected to assist individuals who require support, they cannot currently interact smoothly with people through natural language. For example, given the instruction "Bring me a bottle from the kitchen," it is difficult for such robots to specify the bottle in an indoor environment. Most conventional models have been trained on real-world datasets that are labor-intensive to collect, and they have not fully leveraged simulation data through a transfer learning framework. In this study, we propose a novel transfer learning approach for multimodal language understanding called Prototypical Contrastive Transfer Learning (PCTL), which uses a new contrastive loss called Dual ProtoNCE. We introduce PCTL to the task of identifying target objects in domestic environments according to free-form natural language instructions. To validate PCTL, we built new real-world and simulation datasets. Our experiment demonstrated that PCTL outperformed existing methods. Specifically, PCTL achieved an accuracy of 78.1%, whereas simple fine-tuning achieved an accuracy of 73.4%.