 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPG: Sparse-Projected Guides with Sparse Autoencoders for Zero-Shot Anomaly Detection
Apr 03, 2026We study zero-shot anomaly detection and segmentation using frozen foundation model features, where all learnable parameters are trained only on a labeled auxiliary dataset and deployed to unseen target categories without any target-domain adaptation. Existing prompt-based approaches use handcrafted or learned prompt embeddings as reference vectors for normal/anomalous states. We propose Sparse-Projected Guides (SPG), a prompt-free framework that learns sparse guide coefficients in the Sparse Autoencoder (SAE) latent space, which generate normal/anomaly guide vectors via the SAE dictionary. SPG employs a two stage learning strategy on the labeled auxiliary dataset: (i) train an SAE on patch-token features, and (ii) optimize only guide coefficients using auxiliary pixel-level masks while freezing the backbone and SAE. On MVTec AD and VisA under cross-dataset zero-shot settings, SPG achieves competitive image-level detection and strong pixel-level segmentation; with DINOv3, SPG attains the highest pixellevel AUROC among the compared methods. We also report SPG instantiated with OpenCLIP (ViT-L/14@336px) to align the backbone with CLIP-based baselines. Moreover, the learned guide coefficients trace decisions back to a small set of dictionary atoms, revealing category-general and category-specific factors.
SunnyParking: Multi-Shot Trajectory Generation and Motion State Awareness for Human-like Parking
Feb 25, 2026Autonomous parking fundamentally differs from on-road driving due to its frequent direction changes and complex maneuvering requirements. However, existing End-to-End (E2E) planning methods often simplify the parking task into a geometric path regression problem, neglecting explicit modeling of the vehicle's kinematic state. This "dimensionality deficiency" easily leads to physically infeasible trajectories and deviates from real human driving behavior, particularly at critical gear-shift points in multi-shot parking scenarios. In this paper, we propose SunnyParking, a novel dual-branch E2E architecture that achieves motion state awareness by jointly predicting spatial trajectories and discrete motion state sequences (e.g., forward/reverse). Additionally, we introduce a Fourier feature-based representation of target parking slots to overcome the resolution limitations of traditional bird's-eye view (BEV) approaches, enabling high-precision target interactions. Experimental results demonstrate that our framework generates more robust and human-like trajectories in complex multi-shot parking scenarios, while significantly improving gear-shift point localization accuracy compared to state-of-the-art methods. We open-source a new parking dataset of the CARLA simulator, specifically designed to evaluate full prediction capabilities under complex maneuvers.
Single-Agent vs. Multi-Agent LLM Strategies for Automated Student Reflection Assessment
Apr 08, 2025We explore the use of Large Language Models (LLMs) for automated assessment of open-text student reflections and prediction of academic performance. Traditional methods for evaluating reflections are time-consuming and may not scale effectively in educational settings. In this work, we employ LLMs to transform student reflections into quantitative scores using two assessment strategies (single-agent and multi-agent) and two prompting techniques (zero-shot and few-shot). Our experiments, conducted on a dataset of 5,278 reflections from 377 students over three academic terms, demonstrate that the single-agent with few-shot strategy achieves the highest match rate with human evaluations. Furthermore, models utilizing LLM-assessed reflection scores outperform baselines in both at-risk student identification and grade prediction tasks. These findings suggest that LLMs can effectively automate reflection assessment, reduce educators' workload, and enable timely support for students who may need additional assistance. Our work emphasizes the potential of integrating advanced generative AI technologies into educational practices to enhance student engagement and academic success.
Panoramic Distortion-Aware Tokenization for Person Detection and Localization Using Transformers in Overhead Fisheye Images
Mar 18, 2025Person detection methods are used widely in applications including visual surveillance, pedestrian detection, and robotics. However, accurate detection of persons from overhead fisheye images remains an open challenge because of factors including person rotation and small-sized persons. To address the person rotation problem, we convert the fisheye images into panoramic images. For smaller people, we focused on the geometry of the panoramas. Conventional detection methods tend to focus on larger people because these larger people yield large significant areas for feature maps. In equirectangular panoramic images, we find that a person's height decreases linearly near the top of the images. Using this finding, we leverage the significance values and aggregate tokens that are sorted based on these values to balance the significant areas. In this leveraging process, we introduce panoramic distortion-aware tokenization. This tokenization procedure divides a panoramic image using self-similarity figures that enable determination of optimal divisions without gaps, and we leverage the maximum significant values in each tile of token groups to preserve the significant areas of smaller people. To achieve higher detection accuracy, we propose a person detection and localization method that combines panoramic-image remapping and the tokenization procedure. Extensive experiments demonstrated that our method outperforms conventional methods when applied to large-scale datasets.
DeBiFormer: Vision Transformer with Deformable Agent Bi-level Routing Attention
Oct 11, 2024



Vision Transformers with various attention modules have demonstrated superior performance on vision tasks. While using sparsity-adaptive attention, such as in DAT, has yielded strong results in image classification, the key-value pairs selected by deformable points lack semantic relevance when fine-tuning for semantic segmentation tasks. The query-aware sparsity attention in BiFormer seeks to focus each query on top-k routed regions. However, during attention calculation, the selected key-value pairs are influenced by too many irrelevant queries, reducing attention on the more important ones. To address these issues, we propose the Deformable Bi-level Routing Attention (DBRA) module, which optimizes the selection of key-value pairs using agent queries and enhances the interpretability of queries in attention maps. Based on this, we introduce the Deformable Bi-level Routing Attention Transformer (DeBiFormer), a novel general-purpose vision transformer built with the DBRA module. DeBiFormer has been validated on various computer vision tasks, including image classification, object detection, and semantic segmentation, providing strong evidence of its effectiveness.Code is available at {https://github.com/maclong01/DeBiFormer}
* 20 pages, 7 figures. arXiv admin note: text overlap with arXiv:2303.08810 by other authors
Nearest Neighbor Future Captioning: Generating Descriptions for Possible Collisions in Object Placement Tasks
Jul 18, 2024



Domestic service robots (DSRs) that support people in everyday environments have been widely investigated. However, their ability to predict and describe future risks resulting from their own actions remains insufficient. In this study, we focus on the linguistic explainability of DSRs. Most existing methods do not explicitly model the region of possible collisions; thus, they do not properly generate descriptions of these regions. In this paper, we propose the Nearest Neighbor Future Captioning Model that introduces the Nearest Neighbor Language Model for future captioning of possible collisions, which enhances the model output with a nearest neighbors retrieval mechanism. Furthermore, we introduce the Collision Attention Module that attends regions of possible collisions, which enables our model to generate descriptions that adequately reflect the objects associated with possible collisions. To validate our method, we constructed a new dataset containing samples of collisions that can occur when a DSR places an object in a simulation environment. The experimental results demonstrated that our method outperformed baseline methods, based on the standard metrics. In particular, on CIDEr-D, the baseline method obtained 25.09 points, whereas our method obtained 33.08 points.
Layer-Wise Relevance Propagation with Conservation Property for ResNet
Jul 12, 2024



The transparent formulation of explanation methods is essential for elucidating the predictions of neural networks, which are typically black-box models. Layer-wise Relevance Propagation (LRP) is a well-established method that transparently traces the flow of a model's prediction backward through its architecture by backpropagating relevance scores. However, the conventional LRP does not fully consider the existence of skip connections, and thus its application to the widely used ResNet architecture has not been thoroughly explored. In this study, we extend LRP to ResNet models by introducing Relevance Splitting at points where the output from a skip connection converges with that from a residual block. Our formulation guarantees the conservation property throughout the process, thereby preserving the integrity of the generated explanations. To evaluate the effectiveness of our approach, we conduct experiments on ImageNet and the Caltech-UCSD Birds-200-2011 dataset. Our method achieves superior performance to that of baseline methods on standard evaluation metrics such as the Insertion-Deletion score while maintaining its conservation property. We will release our code for further research at https://5ei74r0.github.io/lrp-for-resnet.page/
Action Q-Transformer: Visual Explanation in Deep Reinforcement Learning with Encoder-Decoder Model using Action Query
Jun 24, 2023The excellent performance of Transformer in supervised learning has led to growing interest in its potential application to deep reinforcement learning (DRL) to achieve high performance on a wide variety of problems. However, the decision making of a DRL agent is a black box, which greatly hinders the application of the agent to real-world problems. To address this problem, we propose the Action Q-Transformer (AQT), which introduces a transformer encoder-decoder structure to Q-learning based DRL methods. In AQT, the encoder calculates the state value function and the decoder calculates the advantage function to promote the acquisition of different attentions indicating the agent's decision-making. The decoder in AQT utilizes action queries, which represent the information of each action, as queries. This enables us to obtain the attentions for the state value and for each action. By acquiring and visualizing these attentions that detail the agent's decision-making, we achieve a DRL model with high interpretability. In this paper, we show that visualization of attention in Atari 2600 games enables detailed analysis of agents' decision-making in various game tasks. Further, experimental results demonstrate that our method can achieve higher performance than the baseline in some games.
Learning from AI: An Interactive Learning Method Using a DNN Model Incorporating Expert Knowledge as a Teacher
Jun 04, 2023


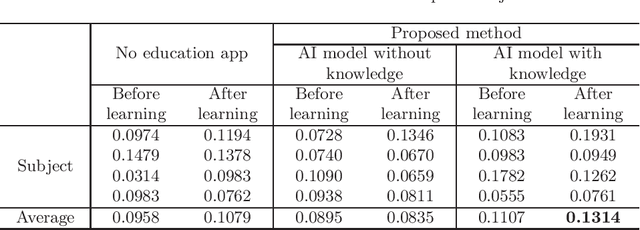
Visual explanation is an approach for visualizing the grounds of judgment by deep learning, and it is possible to visually interpret the grounds of a judgment for a certain input by visualizing an attention map. As for deep-learning models that output erroneous decision-making grounds, a method that incorporates expert human knowledge in the model via an attention map in a manner that improves explanatory power and recognition accuracy is proposed. In this study, based on a deep-learning model that incorporates the knowledge of experts, a method by which a learner "learns from AI" the grounds for its decisions is proposed. An "attention branch network" (ABN), which has been fine-tuned with attention maps modified by experts, is prepared as a teacher. By using an interactive editing tool for the fine-tuned ABN and attention maps, the learner learns by editing the attention maps and changing the inference results. By repeatedly editing the attention maps and making inferences so that the correct recognition results are output, the learner can acquire the grounds for the expert's judgments embedded in the ABN. The results of an evaluation experiment with subjects show that learning using the proposed method is more efficient than the conventional method.
PALF: Pre-Annotation and Camera-LiDAR Late Fusion for the Easy Annotation of Point Clouds
Apr 13, 20233D object detection has become indispensable in the field of autonomous driving. To date, gratifying breakthroughs have been recorded in 3D object detection research, attributed to deep learning. However, deep learning algorithms are data-driven and require large amounts of annotated point cloud data for training and evaluation. Unlike 2D image labels, annotating point cloud data is difficult due to the limitations of sparsity, irregularity, and low resolution, which requires more manual work, and the annotation efficiency is much lower than 2D image.Therefore, we propose an annotation algorithm for point cloud data, which is pre-annotation and camera-LiDAR late fusion algorithm to easily and accurately annotate. The contributions of this study are as follows. We propose (1) a pre-annotation algorithm that employs 3D object detection and auto fitting for the easy annotation of point clouds, (2) a camera-LiDAR late fusion algorithm using 2D and 3D results for easily error checking, which helps annotators easily identify missing objects, and (3) a point cloud annotation evaluation pipeline to evaluate our experiments. The experimental results show that the proposed algorithm improves the annotating speed by 6.5 times and the annotation quality in terms of the 3D Intersection over Union and precision by 8.2 points and 5.6 points, respectively; additionally, the miss rate is reduced by 31.9 points.