 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeBiFormer: Vision Transformer with Deformable Agent Bi-level Routing Attention
Oct 11, 2024



Vision Transformers with various attention modules have demonstrated superior performance on vision tasks. While using sparsity-adaptive attention, such as in DAT, has yielded strong results in image classification, the key-value pairs selected by deformable points lack semantic relevance when fine-tuning for semantic segmentation tasks. The query-aware sparsity attention in BiFormer seeks to focus each query on top-k routed regions. However, during attention calculation, the selected key-value pairs are influenced by too many irrelevant queries, reducing attention on the more important ones. To address these issues, we propose the Deformable Bi-level Routing Attention (DBRA) module, which optimizes the selection of key-value pairs using agent queries and enhances the interpretability of queries in attention maps. Based on this, we introduce the Deformable Bi-level Routing Attention Transformer (DeBiFormer), a novel general-purpose vision transformer built with the DBRA module. DeBiFormer has been validated on various computer vision tasks, including image classification, object detection, and semantic segmentation, providing strong evidence of its effectiveness.Code is available at {https://github.com/maclong01/DeBiFormer}
* 20 pages, 7 figures. arXiv admin note: text overlap with arXiv:2303.08810 by other authors
STEP CATFormer: Spatial-Temporal Effective Body-Part Cross Attention Transformer for Skeleton-based Action Recognition
Dec 06, 2023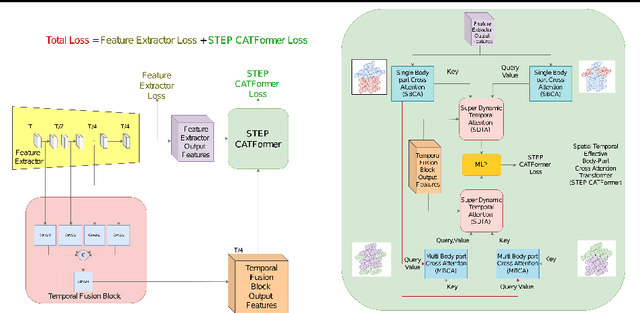
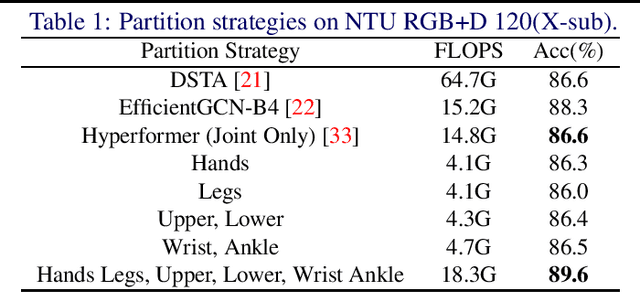
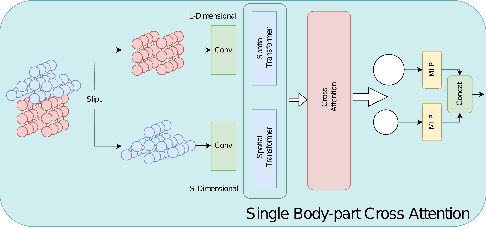
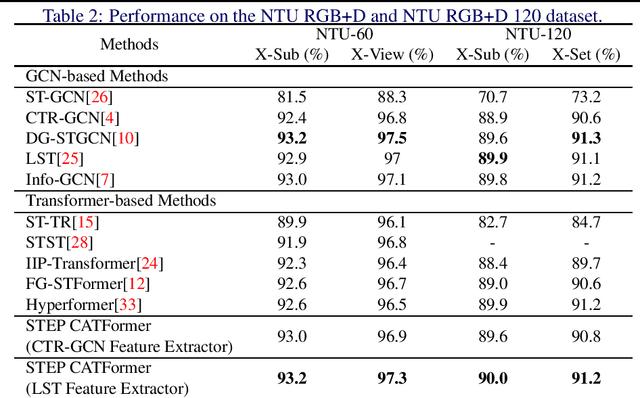
Graph convolutional networks (GCNs) have been widely used and achieved remarkable results in skeleton-based action recognition. We think the key to skeleton-based action recognition is a skeleton hanging in frames, so we focus on how the Graph Convolutional Convolution networks learn different topologies and effectively aggregate joint features in the global temporal and local temporal. In this work, we propose three Channel-wise Tolopogy Graph Convolution based on Channel-wise Topology Refinement Graph Convolution (CTR-GCN). Combining CTR-GCN with two joint cross-attention modules can capture the upper-lower body part and hand-foot relationship skeleton features. After that, to capture features of human skeletons changing in frames we design the Temporal Attention Transformers to extract skeletons effectively. The Temporal Attention Transformers can learn the temporal features of human skeleton sequences. Finally, we fuse the temporal features output scale with MLP and classification. We develop a powerful graph convolutional network named Spatial Temporal Effective Body-part Cross Attention Transformer which notably high-performance on the NTU RGB+D, NTU RGB+D 120 datasets. Our code and models are available at https://github.com/maclong01/STEP-CATFormer