 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossMap Transformer: A Crossmodal Masked Path Transformer Using Double Back-Translation for Vision-and-Language Navigation
Paper and Code
Mar 01, 2021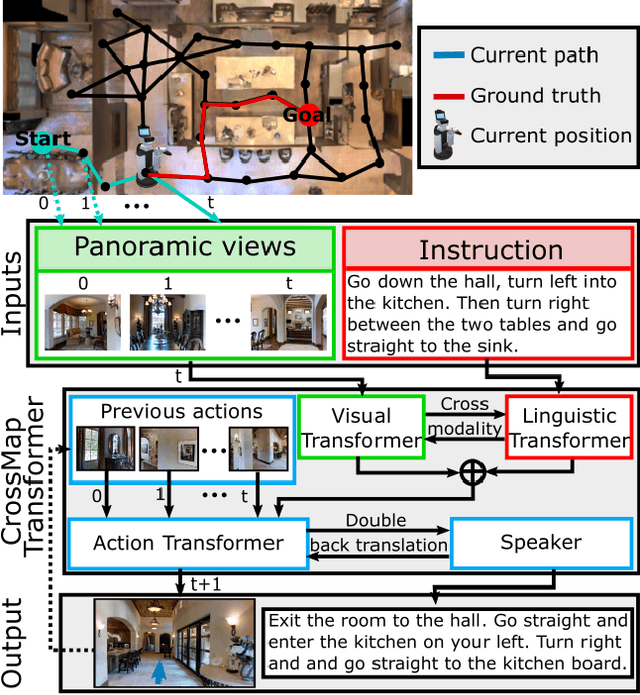
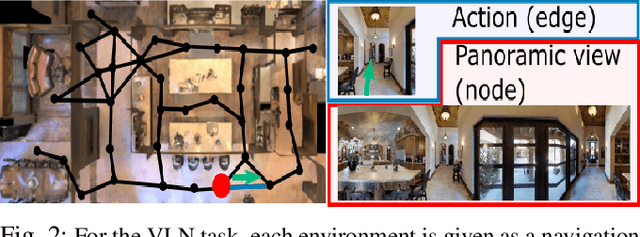
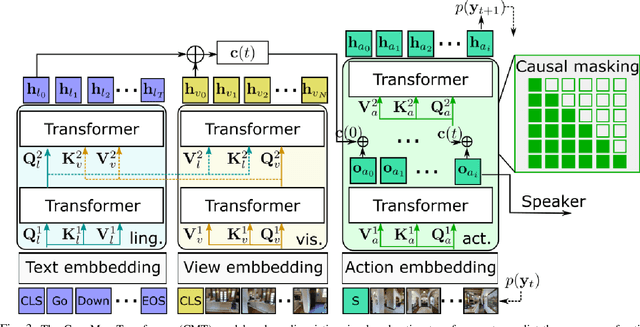
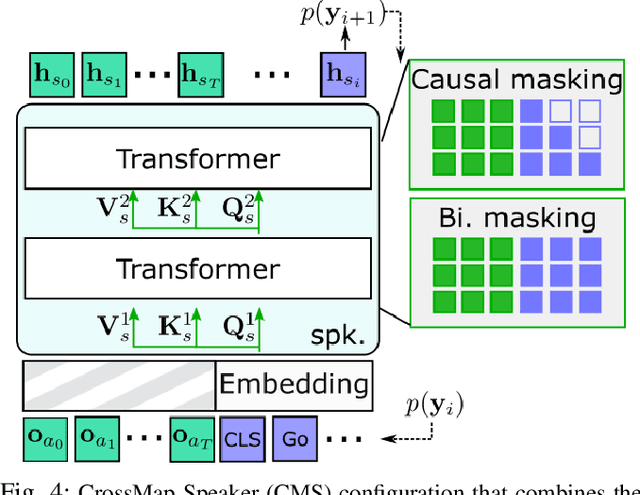
Navigation guided by natural language instructions is particularly suitable for Domestic Service Robots that interacts naturally with users. This task involves the prediction of a sequence of actions that leads to a specified destination given a natural language navigation instruction. The task thus requires the understanding of instructions, such as ``Walk out of the bathroom and wait on the stairs that are on the right''. The Visual and Language Navigation remains challenging, notably because it requires the exploration of the environment and at the accurate following of a path specified by the instructions to model the relationship between language and vision. To address this, we propose the CrossMap Transformer network, which encodes the linguistic and visual features to sequentially generate a path. The CrossMap transformer is tied to a Transformer-based speaker that generates navigation instructions. The two networks share common latent features, for mutual enhancement through a double back translation model: Generated paths are translated into instructions while generated instructions are translated into path The experimental results show the benefits of our approach in terms of instruction understanding and instruction generation.