 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture-Oriented Navigation: Dynamic Obstacle Avoidance with One-Shot Energy-Based Multimodal Motion Prediction
May 01, 2025This paper proposes an integrated approach for the safe and efficient control of mobile robots in dynamic and uncertain environments. The approach consists of two key steps: one-shot multimodal motion prediction to anticipate motions of dynamic obstacles and model predictive control to incorporate these predictions into the motion planning process. Motion prediction is driven by an energy-based neural network that generates high-resolution, multi-step predictions in a single operation. The prediction outcomes are further utilized to create geometric shapes formulated as mathematical constraints. Instead of treating each dynamic obstacle individually, predicted obstacles are grouped by proximity in an unsupervised way to improve performance and efficiency. The overall collision-free navigation is handled by model predictive control with a specific design for proactive dynamic obstacle avoidance. The proposed approach allows mobile robots to navigate effectively in dynamic environments. Its performance is accessed across various scenarios that represent typical warehouse settings. The results demonstrate that the proposed approach outperforms other existing dynamic obstacle avoidance methods.
SplatAD: Real-Time Lidar and Camera Rendering with 3D Gaussian Splatting for Autonomous Driving
Nov 25, 2024Ensuring the safety of autonomous robots, such as self-driving vehicles, requires extensive testing across diverse driving scenarios. Simulation is a key ingredient for conducting such testing in a cost-effective and scalable way. Neural rendering methods have gained popularity, as they can build simulation environments from collected logs in a data-driven manner. However, existing neural radiance field (NeRF) methods for sensor-realistic rendering of camera and lidar data suffer from low rendering speeds, limiting their applicability for large-scale testing. While 3D Gaussian Splatting (3DGS) enables real-time rendering, current methods are limited to camera data and are unable to render lidar data essential for autonomous driving. To address these limitations, we propose SplatAD, the first 3DGS-based method for realistic, real-time rendering of dynamic scenes for both camera and lidar data. SplatAD accurately models key sensor-specific phenomena such as rolling shutter effects, lidar intensity, and lidar ray dropouts, using purpose-built algorithms to optimize rendering efficiency. Evaluation across three autonomous driving datasets demonstrates that SplatAD achieves state-of-the-art rendering quality with up to +2 PSNR for NVS and +3 PSNR for reconstruction while increasing rendering speed over NeRF-based methods by an order of magnitude. See https://research.zenseact.com/publications/splatad/ for our project page.
Are NeRFs ready for autonomous driving? Towards closing the real-to-simulation gap
Mar 24, 2024Neural Radiance Fields (NeRFs) have emerged as promising tools for advancing autonomous driving (AD) research, offering scalable closed-loop simulation and data augmentation capabilities. However, to trust the results achieved in simulation, one needs to ensure that AD systems perceive real and rendered data in the same way. Although the performance of rendering methods is increasing, many scenarios will remain inherently challenging to reconstruct faithfully. To this end, we propose a novel perspective for addressing the real-to-simulated data gap. Rather than solely focusing on improving rendering fidelity, we explore simple yet effective methods to enhance perception model robustness to NeRF artifacts without compromising performance on real data. Moreover, we conduct the first large-scale investigation into the real-to-simulated data gap in an AD setting using a state-of-the-art neural rendering technique. Specifically, we evaluate object detectors and an online mapping model on real and simulated data, and study the effects of different pre-training strategies. Our results show notable improvements in model robustness to simulated data, even improving real-world performance in some cases. Last, we delve into the correlation between the real-to-simulated gap and image reconstruction metrics, identifying FID and LPIPS as strong indicators.
Transformer-Based Multi-Object Smoothing with Decoupled Data Association and Smoothing
Dec 22, 2023Multi-object tracking (MOT) is the task of estimating the state trajectories of an unknown and time-varying number of objects over a certain time window. Several algorithms have been proposed to tackle the multi-object smoothing task, where object detections can be conditioned on all the measurements in the time window. However, the best-performing methods suffer from intractable computational complexity and require approximations, performing suboptimally in complex settings. Deep learning based algorithms are a possible venue for tackling this issue but have not been applied extensively in settings where accurate multi-object models are available and measurements are low-dimensional. We propose a novel DL architecture specifically tailored for this setting that decouples the data association task from the smoothing task. We compare the performance of the proposed smoother to the state-of-the-art in different tasks of varying difficulty and provide, to the best of our knowledge, the first comparison between traditional Bayesian trackers and DL trackers in the smoothing problem setting.
NeuRAD: Neural Rendering for Autonomous Driving
Dec 05, 2023



Neural radiance fields (NeRFs) have gained popularity in the autonomous driving (AD) community. Recent methods show NeRFs' potential for closed-loop simulation, enabling testing of AD systems, and as an advanced training data augmentation technique. However, existing methods often require long training times, dense semantic supervision, or lack generalizability. This, in turn, hinders the application of NeRFs for AD at scale. In this paper, we propose NeuRAD, a robust novel view synthesis method tailored to dynamic AD data. Our method features simple network design, extensive sensor modeling for both camera and lidar -- including rolling shutter, beam divergence and ray dropping -- and is applicable to multiple datasets out of the box. We verify its performance on five popular AD datasets, achieving state-of-the-art performance across the board. To encourage further development, we will openly release the NeuRAD source code. See https://github.com/georghess/NeuRAD .
Zenseact Open Dataset: A large-scale and diverse multimodal dataset for autonomous driving
May 03, 2023



Existing datasets for autonomous driving (AD) often lack diversity and long-range capabilities, focusing instead on 360{\deg} perception and temporal reasoning. To address this gap, we introduce Zenseact Open Dataset (ZOD), a large-scale and diverse multimodal dataset collected over two years in various European countries, covering an area 9x that of existing datasets. ZOD boasts the highest range and resolution sensors among comparable datasets, coupled with detailed keyframe annotations for 2D and 3D objects (up to 245m), road instance/semantic segmentation, traffic sign recognition, and road classification. We believe that this unique combination will facilitate breakthroughs in long-range perception and multi-task learning. The dataset is composed of Frames, Sequences, and Drives, designed to encompass both data diversity and support for spatio-temporal learning, sensor fusion, localization, and mapping. Frames consist of 100k curated camera images with two seconds of other supporting sensor data, while the 1473 Sequences and 29 Drives include the entire sensor suite for 20 seconds and a few minutes, respectively. ZOD is the only large-scale AD dataset released under a permissive license, allowing for both research and commercial use. The dataset is accompanied by an extensive development kit. Data and more information are available online (https://zod.zenseact.com).
LidarCLIP or: How I Learned to Talk to Point Clouds
Dec 13, 2022



Research connecting text and images has recently seen several breakthroughs, with models like CLIP, DALL-E 2, and Stable Diffusion. However, the connection between text and other visual modalities, such as lidar data, has received less attention, prohibited by the lack of text-lidar datasets. In this work, we propose LidarCLIP, a mapping from automotive point clouds to a pre-existing CLIP embedding space. Using image-lidar pairs, we supervise a point cloud encoder with the image CLIP embeddings, effectively relating text and lidar data with the image domain as an intermediary. We show the effectiveness of LidarCLIP by demonstrating that lidar-based retrieval is generally on par with image-based retrieval, but with complementary strengths and weaknesses. By combining image and lidar features, we improve upon both single-modality methods and enable a targeted search for challenging detection scenarios under adverse sensor conditions. We also use LidarCLIP as a tool to investigate fundamental lidar capabilities through natural language. Finally, we leverage our compatibility with CLIP to explore a range of applications, such as point cloud captioning and lidar-to-image generation, without any additional training. We hope LidarCLIP can inspire future work to dive deeper into connections between text and point cloud understanding. Code and trained models available at https://github.com/atonderski/lidarclip.
Masked Autoencoders for Self-Supervised Learning on Automotive Point Clouds
Jul 01, 2022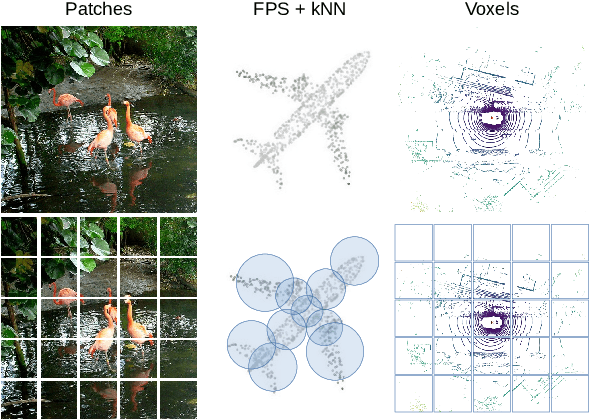

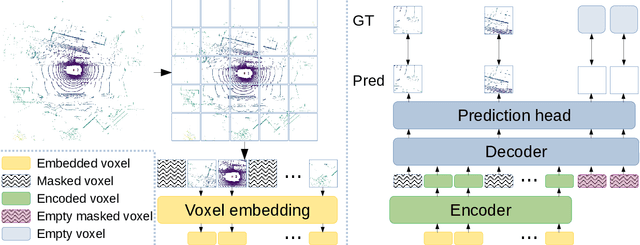
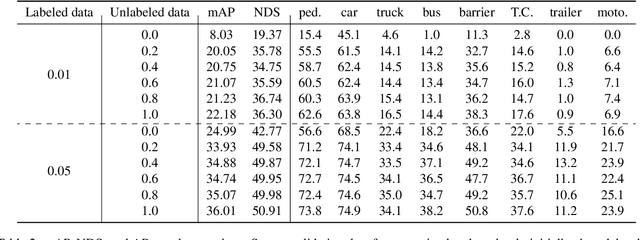
Masked autoencoding has become a successful pre-training paradigm for Transformer models for text, images, and recently, point clouds. Raw automotive datasets are a suitable candidate for self-supervised pre-training as they generally are cheap to collect compared to annotations for tasks like 3D object detection (OD). However, development of masked autoencoders for point clouds has focused solely on synthetic and indoor data. Consequently, existing methods have tailored their representations and models toward point clouds which are small, dense and have homogeneous point density. In this work, we study masked autoencoding for point clouds in an automotive setting, which are sparse and for which the point density can vary drastically among objects in the same scene. To this end, we propose Voxel-MAE, a simple masked autoencoding pre-training scheme designed for voxel representations. We pre-train the backbone of a Transformer-based 3D object detector to reconstruct masked voxels and to distinguish between empty and non-empty voxels. Our method improves the 3D OD performance by 1.75 mAP points and 1.05 NDS on the challenging nuScenes dataset. Compared to existing self-supervised methods for automotive data, Voxel-MAE displays up to $2\times$ performance increase. Further, we show that by pre-training with Voxel-MAE, we require only 40% of the annotated data to outperform a randomly initialized equivalent. Code will be released.
Object Detection as Probabilistic Set Prediction
Mar 16, 2022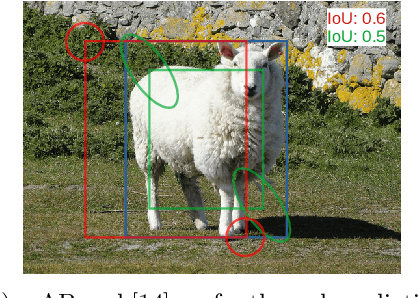
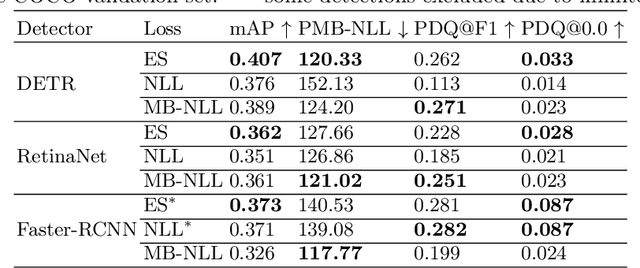

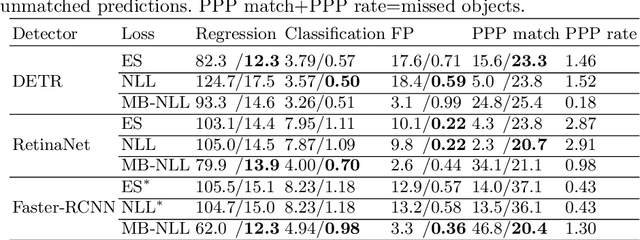
Accurate uncertainty estimates are essential for deploying deep object detectors in safety-critical systems. The development and evaluation of probabilistic object detectors have been hindered by shortcomings in existing performance measures, which tend to involve arbitrary thresholds or limit the detector's choice of distributions. In this work, we propose to view object detection as a set prediction task where detectors predict the distribution over the set of objects. Using the negative log-likelihood for random finite sets, we present a proper scoring rule for evaluating and training probabilistic object detectors. The proposed method can be applied to existing probabilistic detectors, is free from thresholds, and enables fair comparison between architectures. Three different types of detectors are evaluated on the COCO dataset. Our results indicate that the training of existing detectors is optimized toward non-probabilistic metrics. We hope to encourage the development of new object detectors that can accurately estimate their own uncertainty. Code will be released.
Can Deep Learning be Applied to Model-Based Multi-Object Tracking?
Feb 16, 2022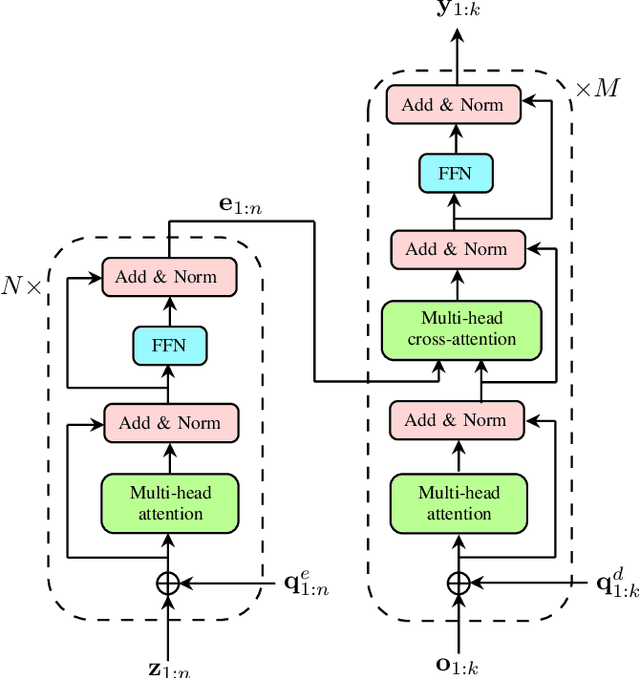
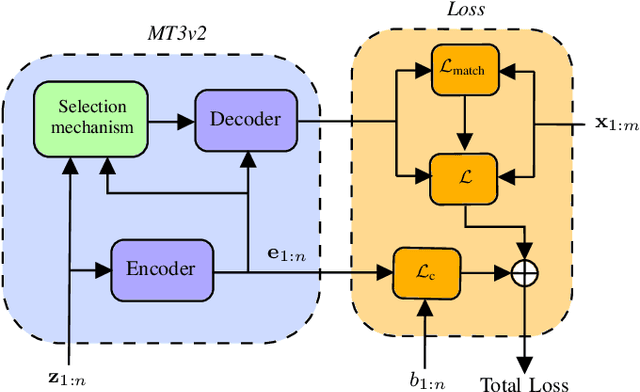

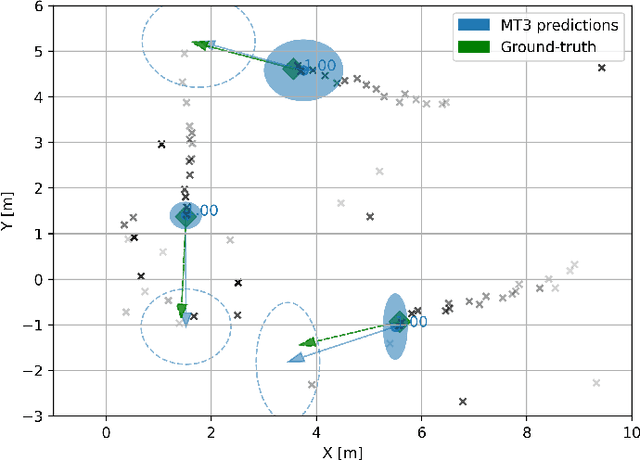
Multi-object tracking (MOT) is the problem of tracking the state of an unknown and time-varying number of objects using noisy measurements, with important applications such as autonomous driving, tracking animal behavior, defense systems, and others. In recent years, deep learning (DL) has been increasingly used in MOT for improving tracking performance, but mostly in settings where the measurements are high-dimensional and there are no available models of the measurement likelihood and the object dynamics. The model-based setting instead has not attracted as much attention, and it is still unclear if DL methods can outperform traditional model-based Bayesian methods, which are the state of the art (SOTA) in this context. In this paper, we propose a Transformer-based DL tracker and evaluate its performance in the model-based setting, comparing it to SOTA model-based Bayesian methods in a variety of different tasks. Our results show that the proposed DL method can match the performance of the model-based methods in simple tasks, while outperforming them when the task gets more complicated, either due to an increase in the data association complexity, or to stronger nonlinearities of the models of the environment.