 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Gene-Based Testing for Antibiotic Resistance Prediction
Feb 19, 2025Antibiotic Resistance (AR) is a critical global health challenge that necessitates the development of cost-effective, efficient, and accurate diagnostic tools. Given the genetic basis of AR, techniques such as Polymerase Chain Reaction (PCR) that target specific resistance genes offer a promising approach for predictive diagnostics using a limited set of key genes. This study introduces GenoARM, a novel framework that integrates reinforcement learning (RL) with transformer-based models to optimize the selection of PCR gene tests and improve AR predictions, leveraging observed metadata for improved accuracy. In our evaluation, we developed several high-performing baselines and compared them using publicly available datasets derived from real-world bacterial samples representing multiple clinically relevant pathogens. The results show that all evaluated methods achieve strong and reliable performance when metadata is not utilized. When metadata is introduced and the number of selected genes increases, GenoARM demonstrates superior performance due to its capacity to approximate rewards for unseen and sparse combinations. Overall, our framework represents a major advancement in optimizing diagnostic tools for AR in clinical settings.
Masked Autoencoders for Self-Supervised Learning on Automotive Point Clouds
Jul 01, 2022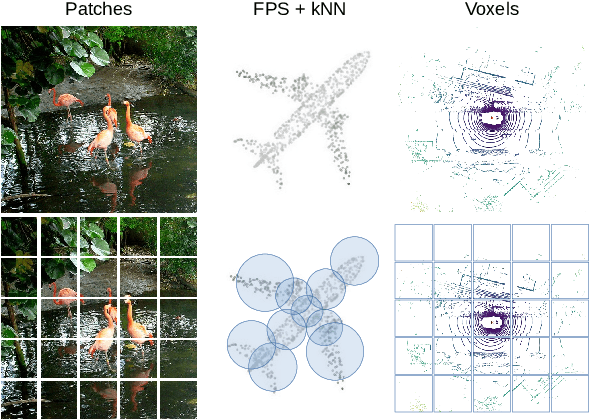

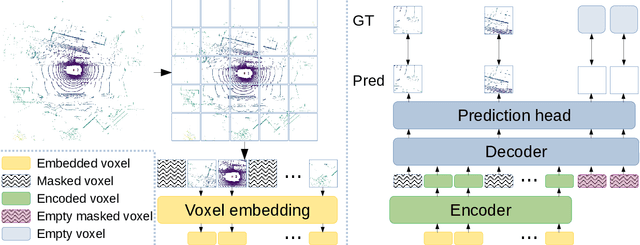
Masked autoencoding has become a successful pre-training paradigm for Transformer models for text, images, and recently, point clouds. Raw automotive datasets are a suitable candidate for self-supervised pre-training as they generally are cheap to collect compared to annotations for tasks like 3D object detection (OD). However, development of masked autoencoders for point clouds has focused solely on synthetic and indoor data. Consequently, existing methods have tailored their representations and models toward point clouds which are small, dense and have homogeneous point density. In this work, we study masked autoencoding for point clouds in an automotive setting, which are sparse and for which the point density can vary drastically among objects in the same scene. To this end, we propose Voxel-MAE, a simple masked autoencoding pre-training scheme designed for voxel representations. We pre-train the backbone of a Transformer-based 3D object detector to reconstruct masked voxels and to distinguish between empty and non-empty voxels. Our method improves the 3D OD performance by 1.75 mAP points and 1.05 NDS on the challenging nuScenes dataset. Compared to existing self-supervised methods for automotive data, Voxel-MAE displays up to $2\times$ performance increase. Further, we show that by pre-training with Voxel-MAE, we require only 40% of the annotated data to outperform a randomly initialized equivalent. Code will be released.