 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3D2: Realistic 3D Asset Insertion via Diffusion for Autonomous Driving Simulation
Jun 09, 2025



Validating autonomous driving (AD) systems requires diverse and safety-critical testing, making photorealistic virtual environments essential. Traditional simulation platforms, while controllable, are resource-intensive to scale and often suffer from a domain gap with real-world data. In contrast, neural reconstruction methods like 3D Gaussian Splatting (3DGS) offer a scalable solution for creating photorealistic digital twins of real-world driving scenes. However, they struggle with dynamic object manipulation and reusability as their per-scene optimization-based methodology tends to result in incomplete object models with integrated illumination effects. This paper introduces R3D2, a lightweight, one-step diffusion model designed to overcome these limitations and enable realistic insertion of complete 3D assets into existing scenes by generating plausible rendering effects-such as shadows and consistent lighting-in real time. This is achieved by training R3D2 on a novel dataset: 3DGS object assets are generated from in-the-wild AD data using an image-conditioned 3D generative model, and then synthetically placed into neural rendering-based virtual environments, allowing R3D2 to learn realistic integration. Quantitative and qualitative evaluations demonstrate that R3D2 significantly enhances the realism of inserted assets, enabling use-cases like text-to-3D asset insertion and cross-scene/dataset object transfer, allowing for true scalability in AD validation. To promote further research in scalable and realistic AD simulation, we will release our dataset and code, see https://research.zenseact.com/publications/R3D2/.
PEAR: Equal Area Weather Forecasting on the Sphere
May 23, 2025Machine learning methods for global medium-range weather forecasting have recently received immense attention. Following the publication of the Pangu Weather model, the first deep learning model to outperform traditional numerical simulations of the atmosphere, numerous models have been published in this domain, building on Pangu's success. However, all of these models operate on input data and produce predictions on the Driscoll--Healy discretization of the sphere which suffers from a much finer grid at the poles than around the equator. In contrast, in the Hierarchical Equal Area iso-Latitude Pixelization (HEALPix) of the sphere, each pixel covers the same surface area, removing unphysical biases. Motivated by a growing support for this grid in meteorology and climate sciences, we propose to perform weather forecasting with deep learning models which natively operate on the HEALPix grid. To this end, we introduce Pangu Equal ARea (PEAR), a transformer-based weather forecasting model which operates directly on HEALPix-features and outperforms the corresponding model on Driscoll--Healy without any computational overhead.
Decoupled Diffusion Sparks Adaptive Scene Generation
Apr 14, 2025Controllable scene generation could reduce the cost of diverse data collection substantially for autonomous driving. Prior works formulate the traffic layout generation as predictive progress, either by denoising entire sequences at once or by iteratively predicting the next frame. However, full sequence denoising hinders online reaction, while the latter's short-sighted next-frame prediction lacks precise goal-state guidance. Further, the learned model struggles to generate complex or challenging scenarios due to a large number of safe and ordinal driving behaviors from open datasets. To overcome these, we introduce Nexus, a decoupled scene generation framework that improves reactivity and goal conditioning by simulating both ordinal and challenging scenarios from fine-grained tokens with independent noise states. At the core of the decoupled pipeline is the integration of a partial noise-masking training strategy and a noise-aware schedule that ensures timely environmental updates throughout the denoising process. To complement challenging scenario generation, we collect a dataset consisting of complex corner cases. It covers 540 hours of simulated data, including high-risk interactions such as cut-in, sudden braking, and collision. Nexus achieves superior generation realism while preserving reactivity and goal orientation, with a 40% reduction in displacement error. We further demonstrate that Nexus improves closed-loop planning by 20% through data augmentation and showcase its capability in safety-critical data generation.
GASP: Unifying Geometric and Semantic Self-Supervised Pre-training for Autonomous Driving
Mar 19, 2025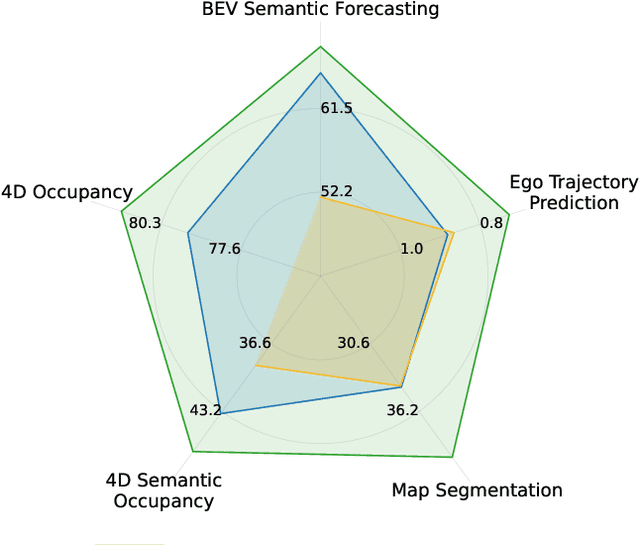
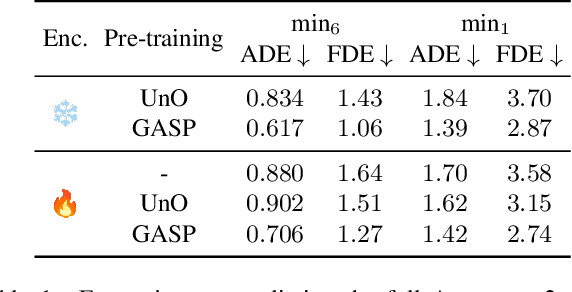
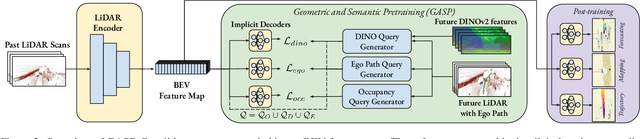
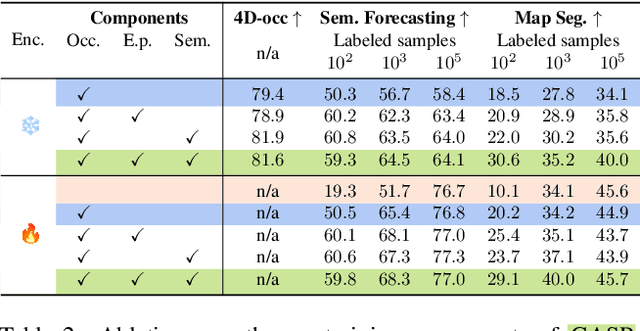
Self-supervised pre-training based on next-token prediction has enabled large language models to capture the underlying structure of text, and has led to unprecedented performance on a large array of tasks when applied at scale. Similarly, autonomous driving generates vast amounts of spatiotemporal data, alluding to the possibility of harnessing scale to learn the underlying geometric and semantic structure of the environment and its evolution over time. In this direction, we propose a geometric and semantic self-supervised pre-training method, GASP, that learns a unified representation by predicting, at any queried future point in spacetime, (1) general occupancy, capturing the evolving structure of the 3D scene; (2) ego occupancy, modeling the ego vehicle path through the environment; and (3) distilled high-level features from a vision foundation model. By modeling geometric and semantic 4D occupancy fields instead of raw sensor measurements, the model learns a structured, generalizable representation of the environment and its evolution through time. We validate GASP on multiple autonomous driving benchmarks, demonstrating significant improvements in semantic occupancy forecasting, online mapping, and ego trajectory prediction. Our results demonstrate that continuous 4D geometric and semantic occupancy prediction provides a scalable and effective pre-training paradigm for autonomous driving. For code and additional visualizations, see \href{https://research.zenseact.com/publications/gasp/.
SplatAD: Real-Time Lidar and Camera Rendering with 3D Gaussian Splatting for Autonomous Driving
Nov 25, 2024Ensuring the safety of autonomous robots, such as self-driving vehicles, requires extensive testing across diverse driving scenarios. Simulation is a key ingredient for conducting such testing in a cost-effective and scalable way. Neural rendering methods have gained popularity, as they can build simulation environments from collected logs in a data-driven manner. However, existing neural radiance field (NeRF) methods for sensor-realistic rendering of camera and lidar data suffer from low rendering speeds, limiting their applicability for large-scale testing. While 3D Gaussian Splatting (3DGS) enables real-time rendering, current methods are limited to camera data and are unable to render lidar data essential for autonomous driving. To address these limitations, we propose SplatAD, the first 3DGS-based method for realistic, real-time rendering of dynamic scenes for both camera and lidar data. SplatAD accurately models key sensor-specific phenomena such as rolling shutter effects, lidar intensity, and lidar ray dropouts, using purpose-built algorithms to optimize rendering efficiency. Evaluation across three autonomous driving datasets demonstrates that SplatAD achieves state-of-the-art rendering quality with up to +2 PSNR for NVS and +3 PSNR for reconstruction while increasing rendering speed over NeRF-based methods by an order of magnitude. See https://research.zenseact.com/publications/splatad/ for our project page.
NeuroNCAP: Photorealistic Closed-loop Safety Testing for Autonomous Driving
Apr 12, 2024



We present a versatile NeRF-based simulator for testing autonomous driving (AD) software systems, designed with a focus on sensor-realistic closed-loop evaluation and the creation of safety-critical scenarios. The simulator learns from sequences of real-world driving sensor data and enables reconfigurations and renderings of new, unseen scenarios. In this work, we use our simulator to test the responses of AD models to safety-critical scenarios inspired by the European New Car Assessment Programme (Euro NCAP). Our evaluation reveals that, while state-of-the-art end-to-end planners excel in nominal driving scenarios in an open-loop setting, they exhibit critical flaws when navigating our safety-critical scenarios in a closed-loop setting. This highlights the need for advancements in the safety and real-world usability of end-to-end planners. By publicly releasing our simulator and scenarios as an easy-to-run evaluation suite, we invite the research community to explore, refine, and validate their AD models in controlled, yet highly configurable and challenging sensor-realistic environments. Code and instructions can be found at https://github.com/wljungbergh/NeuroNCAP
Are NeRFs ready for autonomous driving? Towards closing the real-to-simulation gap
Mar 24, 2024Neural Radiance Fields (NeRFs) have emerged as promising tools for advancing autonomous driving (AD) research, offering scalable closed-loop simulation and data augmentation capabilities. However, to trust the results achieved in simulation, one needs to ensure that AD systems perceive real and rendered data in the same way. Although the performance of rendering methods is increasing, many scenarios will remain inherently challenging to reconstruct faithfully. To this end, we propose a novel perspective for addressing the real-to-simulated data gap. Rather than solely focusing on improving rendering fidelity, we explore simple yet effective methods to enhance perception model robustness to NeRF artifacts without compromising performance on real data. Moreover, we conduct the first large-scale investigation into the real-to-simulated data gap in an AD setting using a state-of-the-art neural rendering technique. Specifically, we evaluate object detectors and an online mapping model on real and simulated data, and study the effects of different pre-training strategies. Our results show notable improvements in model robustness to simulated data, even improving real-world performance in some cases. Last, we delve into the correlation between the real-to-simulated gap and image reconstruction metrics, identifying FID and LPIPS as strong indicators.
NeuRAD: Neural Rendering for Autonomous Driving
Dec 05, 2023



Neural radiance fields (NeRFs) have gained popularity in the autonomous driving (AD) community. Recent methods show NeRFs' potential for closed-loop simulation, enabling testing of AD systems, and as an advanced training data augmentation technique. However, existing methods often require long training times, dense semantic supervision, or lack generalizability. This, in turn, hinders the application of NeRFs for AD at scale. In this paper, we propose NeuRAD, a robust novel view synthesis method tailored to dynamic AD data. Our method features simple network design, extensive sensor modeling for both camera and lidar -- including rolling shutter, beam divergence and ray dropping -- and is applicable to multiple datasets out of the box. We verify its performance on five popular AD datasets, achieving state-of-the-art performance across the board. To encourage further development, we will openly release the NeuRAD source code. See https://github.com/georghess/NeuRAD .
You can have your ensemble and run it too -- Deep Ensembles Spread Over Time
Sep 20, 2023Ensembles of independently trained deep neural networks yield uncertainty estimates that rival Bayesian networks in performance. They also offer sizable improvements in terms of predictive performance over single models. However, deep ensembles are not commonly used in environments with limited computational budget -- such as autonomous driving -- since the complexity grows linearly with the number of ensemble members. An important observation that can be made for robotics applications, such as autonomous driving, is that data is typically sequential. For instance, when an object is to be recognized, an autonomous vehicle typically observes a sequence of images, rather than a single image. This raises the question, could the deep ensemble be spread over time? In this work, we propose and analyze Deep Ensembles Spread Over Time (DESOT). The idea is to apply only a single ensemble member to each data point in the sequence, and fuse the predictions over a sequence of data points. We implement and experiment with DESOT for traffic sign classification, where sequences of tracked image patches are to be classified. We find that DESOT obtains the benefits of deep ensembles, in terms of predictive and uncertainty estimation performance, while avoiding the added computational cost. Moreover, DESOT is simple to implement and does not require sequences during training. Finally, we find that DESOT, like deep ensembles, outperform single models for out-of-distribution detection.
HEAL-SWIN: A Vision Transformer On The Sphere
Jul 14, 2023



High-resolution wide-angle fisheye images are becoming more and more important for robotics applications such as autonomous driving. However, using ordinary convolutional neural networks or vision transformers on this data is problematic due to projection and distortion losses introduced when projecting to a rectangular grid on the plane. We introduce the HEAL-SWIN transformer, which combines the highly uniform Hierarchical Equal Area iso-Latitude Pixelation (HEALPix) grid used in astrophysics and cosmology with the Hierarchical Shifted-Window (SWIN) transformer to yield an efficient and flexible model capable of training on high-resolution, distortion-free spherical data. In HEAL-SWIN, the nested structure of the HEALPix grid is used to perform the patching and windowing operations of the SWIN transformer, resulting in a one-dimensional representation of the spherical data with minimal computational overhead. We demonstrate the superior performance of our model for semantic segmentation and depth regression tasks on both synthetic and real automotive datasets. Our code is available at https://github.com/JanEGerken/HEAL-SWIN.