 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEAR: Equal Area Weather Forecasting on the Sphere
May 23, 2025Machine learning methods for global medium-range weather forecasting have recently received immense attention. Following the publication of the Pangu Weather model, the first deep learning model to outperform traditional numerical simulations of the atmosphere, numerous models have been published in this domain, building on Pangu's success. However, all of these models operate on input data and produce predictions on the Driscoll--Healy discretization of the sphere which suffers from a much finer grid at the poles than around the equator. In contrast, in the Hierarchical Equal Area iso-Latitude Pixelization (HEALPix) of the sphere, each pixel covers the same surface area, removing unphysical biases. Motivated by a growing support for this grid in meteorology and climate sciences, we propose to perform weather forecasting with deep learning models which natively operate on the HEALPix grid. To this end, we introduce Pangu Equal ARea (PEAR), a transformer-based weather forecasting model which operates directly on HEALPix-features and outperforms the corresponding model on Driscoll--Healy without any computational overhead.
Equivariant non-linear maps for neural networks on homogeneous spaces
Apr 29, 2025This paper presents a novel framework for non-linear equivariant neural network layers on homogeneous spaces. The seminal work of Cohen et al. on equivariant $G$-CNNs on homogeneous spaces characterized the representation theory of such layers in the linear setting, finding that they are given by convolutions with kernels satisfying so-called steerability constraints. Motivated by the empirical success of non-linear layers, such as self-attention or input dependent kernels, we set out to generalize these insights to the non-linear setting. We derive generalized steerability constraints that any such layer needs to satisfy and prove the universality of our construction. The insights gained into the symmetry-constrained functional dependence of equivariant operators on feature maps and group elements informs the design of future equivariant neural network layers. We demonstrate how several common equivariant network architectures - $G$-CNNs, implicit steerable kernel networks, conventional and relative position embedded attention based transformers, and LieTransformers - may be derived from our framework.
Learning Chern Numbers of Topological Insulators with Gauge Equivariant Neural Networks
Feb 21, 2025



Equivariant network architectures are a well-established tool for predicting invariant or equivariant quantities. However, almost all learning problems considered in this context feature a global symmetry, i.e. each point of the underlying space is transformed with the same group element, as opposed to a local ``gauge'' symmetry, where each point is transformed with a different group element, exponentially enlarging the size of the symmetry group. Gauge equivariant networks have so far mainly been applied to problems in quantum chromodynamics. Here, we introduce a novel application domain for gauge-equivariant networks in the theory of topological condensed matter physics. We use gauge equivariant networks to predict topological invariants (Chern numbers) of multiband topological insulators. The gauge symmetry of the network guarantees that the predicted quantity is a topological invariant. We introduce a novel gauge equivariant normalization layer to stabilize the training and prove a universal approximation theorem for our setup. We train on samples with trivial Chern number only but show that our models generalize to samples with non-trivial Chern number. We provide various ablations of our setup. Our code is available at https://github.com/sitronsea/GENet/tree/main.
HEAL-SWIN: A Vision Transformer On The Sphere
Jul 14, 2023



High-resolution wide-angle fisheye images are becoming more and more important for robotics applications such as autonomous driving. However, using ordinary convolutional neural networks or vision transformers on this data is problematic due to projection and distortion losses introduced when projecting to a rectangular grid on the plane. We introduce the HEAL-SWIN transformer, which combines the highly uniform Hierarchical Equal Area iso-Latitude Pixelation (HEALPix) grid used in astrophysics and cosmology with the Hierarchical Shifted-Window (SWIN) transformer to yield an efficient and flexible model capable of training on high-resolution, distortion-free spherical data. In HEAL-SWIN, the nested structure of the HEALPix grid is used to perform the patching and windowing operations of the SWIN transformer, resulting in a one-dimensional representation of the spherical data with minimal computational overhead. We demonstrate the superior performance of our model for semantic segmentation and depth regression tasks on both synthetic and real automotive datasets. Our code is available at https://github.com/JanEGerken/HEAL-SWIN.
Equivariance versus Augmentation for Spherical Images
Feb 08, 2022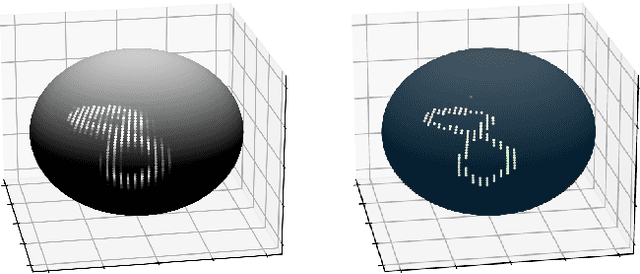
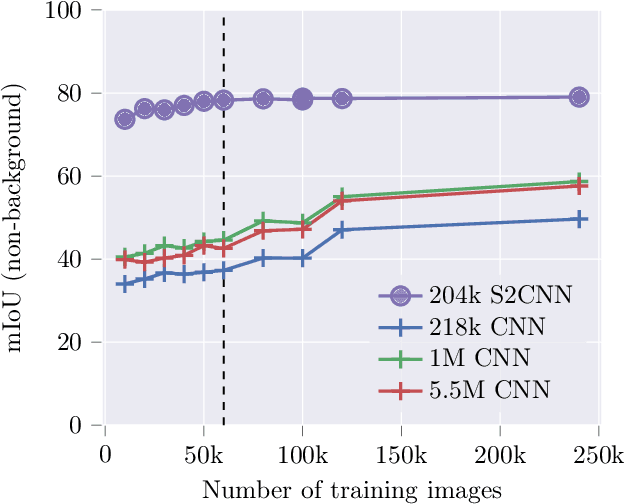
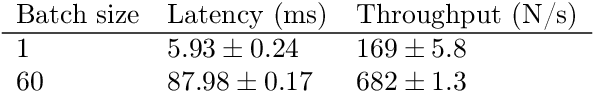
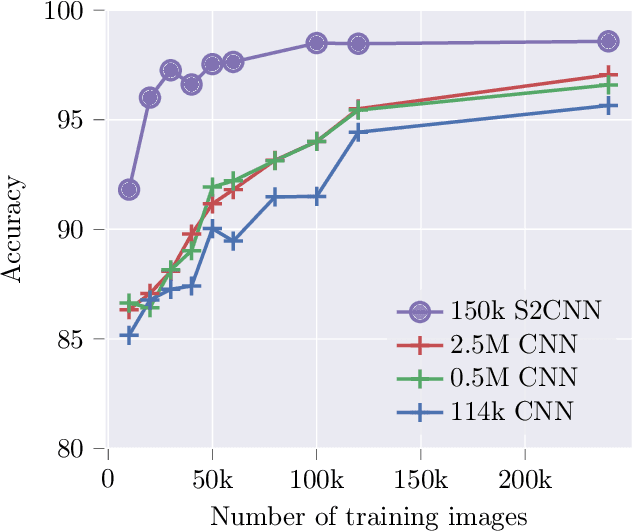
We analyze the role of rotational equivariance in convolutional neural networks (CNNs) applied to spherical images. We compare the performance of the group equivariant networks known as S2CNNs and standard non-equivariant CNNs trained with an increasing amount of data augmentation. The chosen architectures can be considered baseline references for the respective design paradigms. Our models are trained and evaluated on single or multiple items from the MNIST or FashionMNIST dataset projected onto the sphere. For the task of image classification, which is inherently rotationally invariant, we find that by considerably increasing the amount of data augmentation and the size of the networks, it is possible for the standard CNNs to reach at least the same performance as the equivariant network. In contrast, for the inherently equivariant task of semantic segmentation, the non-equivariant networks are consistently outperformed by the equivariant networks with significantly fewer parameters. We also analyze and compare the inference latency and training times of the different networks, enabling detailed tradeoff considerations between equivariant architectures and data augmentation for practical problems. The equivariant spherical networks used in the experiments will be made available at https://github.com/JanEGerken/sem_seg_s2cnn .
Geometric Deep Learning and Equivariant Neural Networks
May 28, 2021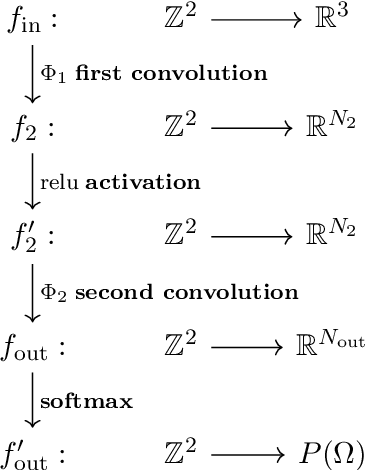
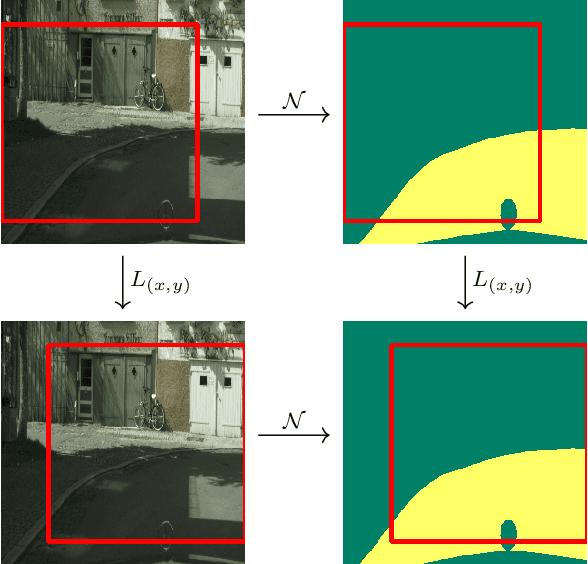
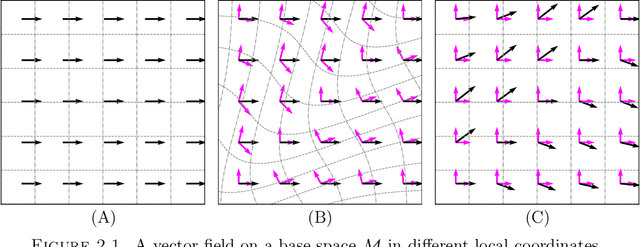
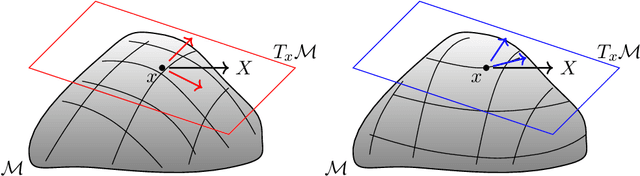
We survey the mathematical foundations of geometric deep learning, focusing on group equivariant and gauge equivariant neural networks. We develop gauge equivariant convolutional neural networks on arbitrary manifolds $\mathcal{M}$ using principal bundles with structure group $K$ and equivariant maps between sections of associated vector bundles. We also discuss group equivariant neural networks for homogeneous spaces $\mathcal{M}=G/K$, which are instead equivariant with respect to the global symmetry $G$ on $\mathcal{M}$. Group equivariant layers can be interpreted as intertwiners between induced representations of $G$, and we show their relation to gauge equivariant convolutional layers. We analyze several applications of this formalism, including semantic segmentation and object detection networks. We also discuss the case of spherical networks in great detail, corresponding to the case $\mathcal{M}=S^2=\mathrm{SO}(3)/\mathrm{SO}(2)$. Here we emphasize the use of Fourier analysis involving Wigner matrices, spherical harmonics and Clebsch-Gordan coefficients for $G=\mathrm{SO}(3)$, illustrating the power of representation theory for deep learning.