 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCriticality and Saturation in Orthogonal Neural Networks
May 07, 2026It has been known for a long time that initializing weight matrices to be orthogonal instead of having i.i.d. Gaussian components can improve training performance. This phenomenon can be analyzed using finite-width corrections, where the infinite-width statistics are supplemented by a power series in $1/\mathrm{width}$. In particular, recent empirical results by Day et al. show that the tensors appearing in this treatment stabilize for large depth, as opposed to the tensors of i.i.d.-initialized networks. In this article, we derive explicit layer-wise recursion relations for the tensors appearing in the finite-width expansion of the network statistics in the case of orthogonal initializations. We also provide an extension of recently-introduced Feynman diagrams for the corresponding recursions in the i.i.d.-case which are valid to all orders in $1/\mathrm{width}$. Finally, we show explicitly that the recursions we derive reproduce the stability of the finite-width tensors which was observed for activation functions with vanishing fixed point. This work therefore provides a theoretical explanation for the stability of nonlinear networks of finite width initialized with orthogonal weights, closing a long-standing gap in the literature. We validate our theoretical results experimentally by showing that numerical solutions of our recursion relations and their analytical large-depth expansions agree excellently with Monte-Carlo estimates from network ensembles.
PEAR: Equal Area Weather Forecasting on the Sphere
May 23, 2025Machine learning methods for global medium-range weather forecasting have recently received immense attention. Following the publication of the Pangu Weather model, the first deep learning model to outperform traditional numerical simulations of the atmosphere, numerous models have been published in this domain, building on Pangu's success. However, all of these models operate on input data and produce predictions on the Driscoll--Healy discretization of the sphere which suffers from a much finer grid at the poles than around the equator. In contrast, in the Hierarchical Equal Area iso-Latitude Pixelization (HEALPix) of the sphere, each pixel covers the same surface area, removing unphysical biases. Motivated by a growing support for this grid in meteorology and climate sciences, we propose to perform weather forecasting with deep learning models which natively operate on the HEALPix grid. To this end, we introduce Pangu Equal ARea (PEAR), a transformer-based weather forecasting model which operates directly on HEALPix-features and outperforms the corresponding model on Driscoll--Healy without any computational overhead.
Learning Chern Numbers of Topological Insulators with Gauge Equivariant Neural Networks
Feb 21, 2025



Equivariant network architectures are a well-established tool for predicting invariant or equivariant quantities. However, almost all learning problems considered in this context feature a global symmetry, i.e. each point of the underlying space is transformed with the same group element, as opposed to a local ``gauge'' symmetry, where each point is transformed with a different group element, exponentially enlarging the size of the symmetry group. Gauge equivariant networks have so far mainly been applied to problems in quantum chromodynamics. Here, we introduce a novel application domain for gauge-equivariant networks in the theory of topological condensed matter physics. We use gauge equivariant networks to predict topological invariants (Chern numbers) of multiband topological insulators. The gauge symmetry of the network guarantees that the predicted quantity is a topological invariant. We introduce a novel gauge equivariant normalization layer to stabilize the training and prove a universal approximation theorem for our setup. We train on samples with trivial Chern number only but show that our models generalize to samples with non-trivial Chern number. We provide various ablations of our setup. Our code is available at https://github.com/sitronsea/GENet/tree/main.
Equivariant Neural Tangent Kernels
Jun 10, 2024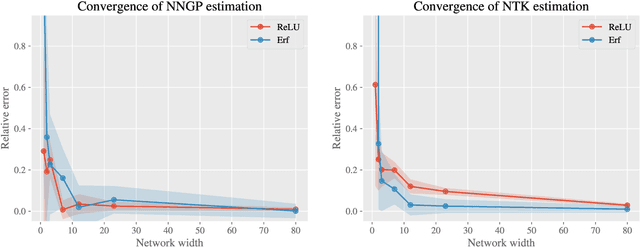
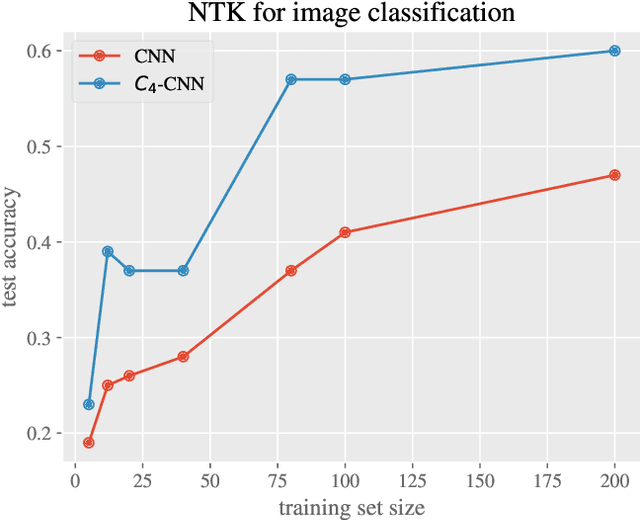
Equivariant neural networks have in recent years become an important technique for guiding architecture selection for neural networks with many applications in domains ranging from medical image analysis to quantum chemistry. In particular, as the most general linear equivariant layers with respect to the regular representation, group convolutions have been highly impactful in numerous applications. Although equivariant architectures have been studied extensively, much less is known about the training dynamics of equivariant neural networks. Concurrently, neural tangent kernels (NTKs) have emerged as a powerful tool to analytically understand the training dynamics of wide neural networks. In this work, we combine these two fields for the first time by giving explicit expressions for NTKs of group convolutional neural networks. In numerical experiments, we demonstrate superior performance for equivariant NTKs over non-equivariant NTKs on a classification task for medical images.
Emergent Equivariance in Deep Ensembles
Mar 05, 2024



We demonstrate that deep ensembles are secretly equivariant models. More precisely, we show that deep ensembles become equivariant for all inputs and at all training times by simply using data augmentation. Crucially, equivariance holds off-manifold and for any architecture in the infinite width limit. The equivariance is emergent in the sense that predictions of individual ensemble members are not equivariant but their collective prediction is. Neural tangent kernel theory is used to derive this result and we verify our theoretical insights using detailed numerical experiments.
HEAL-SWIN: A Vision Transformer On The Sphere
Jul 14, 2023



High-resolution wide-angle fisheye images are becoming more and more important for robotics applications such as autonomous driving. However, using ordinary convolutional neural networks or vision transformers on this data is problematic due to projection and distortion losses introduced when projecting to a rectangular grid on the plane. We introduce the HEAL-SWIN transformer, which combines the highly uniform Hierarchical Equal Area iso-Latitude Pixelation (HEALPix) grid used in astrophysics and cosmology with the Hierarchical Shifted-Window (SWIN) transformer to yield an efficient and flexible model capable of training on high-resolution, distortion-free spherical data. In HEAL-SWIN, the nested structure of the HEALPix grid is used to perform the patching and windowing operations of the SWIN transformer, resulting in a one-dimensional representation of the spherical data with minimal computational overhead. We demonstrate the superior performance of our model for semantic segmentation and depth regression tasks on both synthetic and real automotive datasets. Our code is available at https://github.com/JanEGerken/HEAL-SWIN.
Diffeomorphic Counterfactuals with Generative Models
Jun 16, 2022

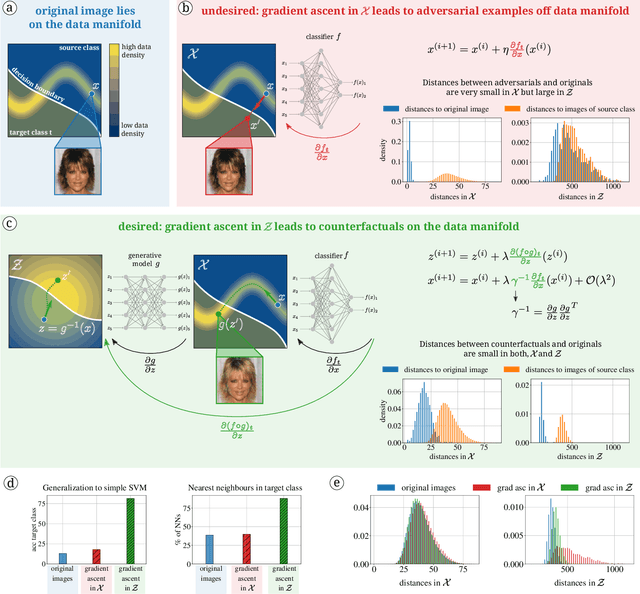
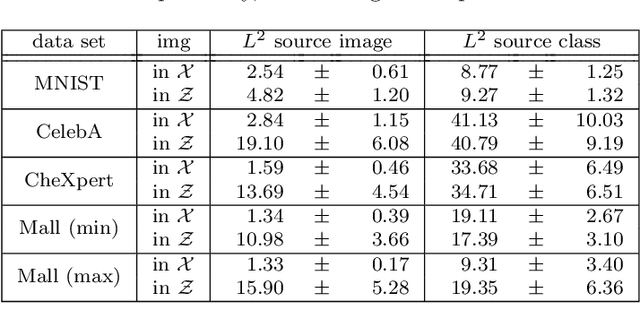
Counterfactuals can explain classification decisions of neural networks in a human interpretable way. We propose a simple but effective method to generate such counterfactuals. More specifically, we perform a suitable diffeomorphic coordinate transformation and then perform gradient ascent in these coordinates to find counterfactuals which are classified with great confidence as a specified target class. We propose two methods to leverage generative models to construct such suitable coordinate systems that are either exactly or approximately diffeomorphic. We analyze the generation process theoretically using Riemannian differential geometry and validate the quality of the generated counterfactuals using various qualitative and quantitative measures.
Equivariance versus Augmentation for Spherical Images
Feb 08, 2022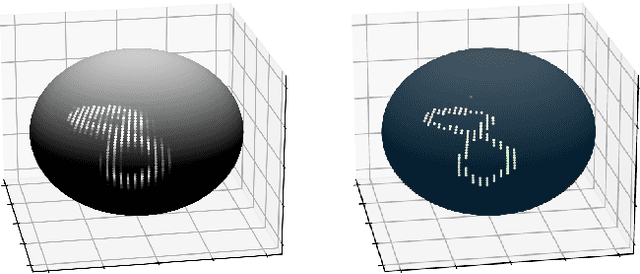
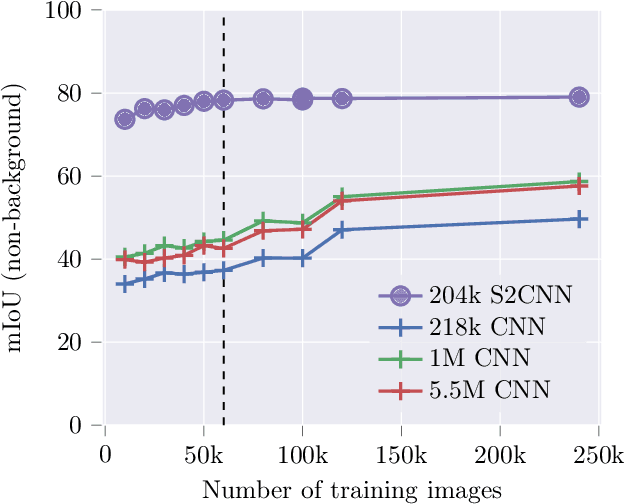
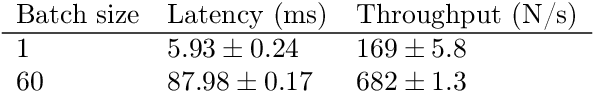
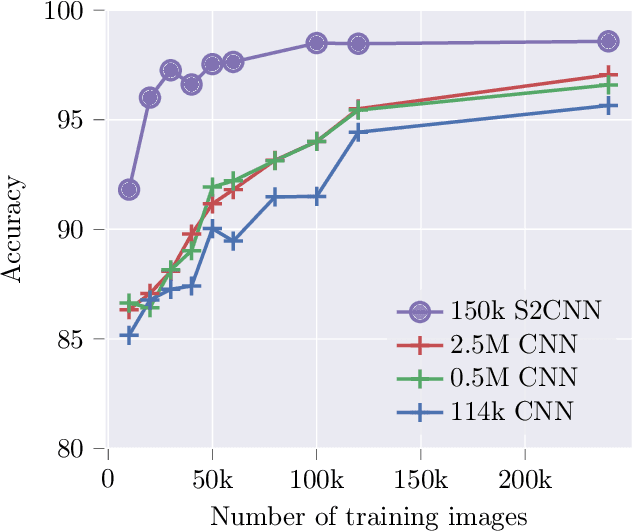
We analyze the role of rotational equivariance in convolutional neural networks (CNNs) applied to spherical images. We compare the performance of the group equivariant networks known as S2CNNs and standard non-equivariant CNNs trained with an increasing amount of data augmentation. The chosen architectures can be considered baseline references for the respective design paradigms. Our models are trained and evaluated on single or multiple items from the MNIST or FashionMNIST dataset projected onto the sphere. For the task of image classification, which is inherently rotationally invariant, we find that by considerably increasing the amount of data augmentation and the size of the networks, it is possible for the standard CNNs to reach at least the same performance as the equivariant network. In contrast, for the inherently equivariant task of semantic segmentation, the non-equivariant networks are consistently outperformed by the equivariant networks with significantly fewer parameters. We also analyze and compare the inference latency and training times of the different networks, enabling detailed tradeoff considerations between equivariant architectures and data augmentation for practical problems. The equivariant spherical networks used in the experiments will be made available at https://github.com/JanEGerken/sem_seg_s2cnn .
Geometric Deep Learning and Equivariant Neural Networks
May 28, 2021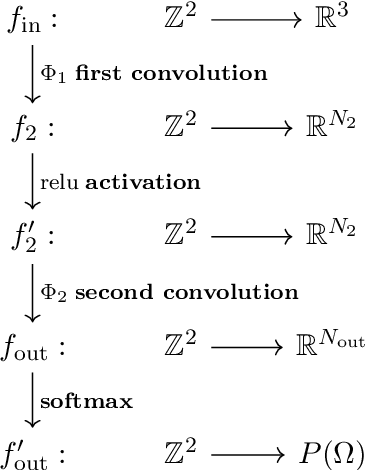
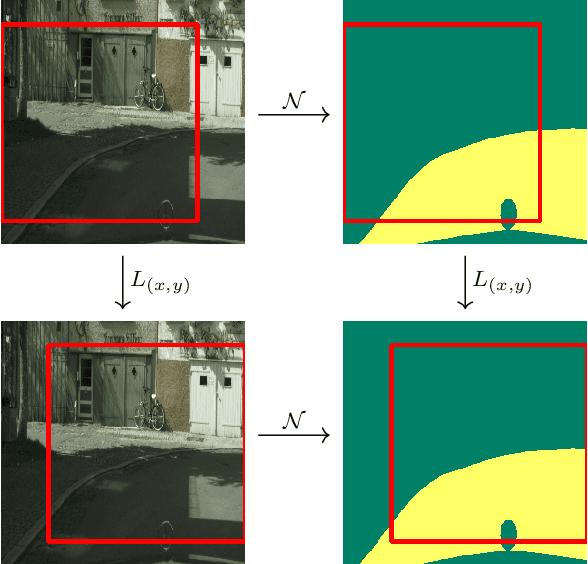
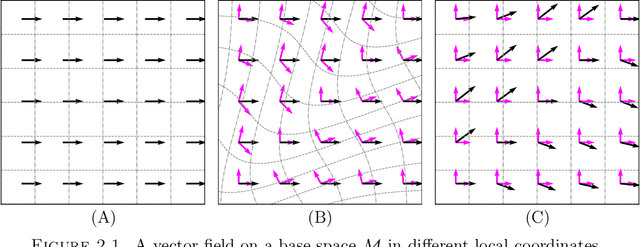
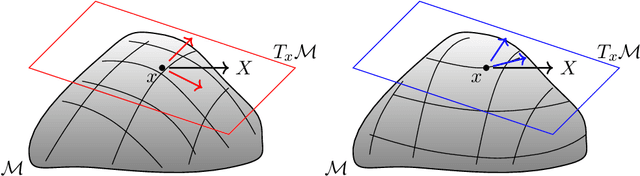
We survey the mathematical foundations of geometric deep learning, focusing on group equivariant and gauge equivariant neural networks. We develop gauge equivariant convolutional neural networks on arbitrary manifolds $\mathcal{M}$ using principal bundles with structure group $K$ and equivariant maps between sections of associated vector bundles. We also discuss group equivariant neural networks for homogeneous spaces $\mathcal{M}=G/K$, which are instead equivariant with respect to the global symmetry $G$ on $\mathcal{M}$. Group equivariant layers can be interpreted as intertwiners between induced representations of $G$, and we show their relation to gauge equivariant convolutional layers. We analyze several applications of this formalism, including semantic segmentation and object detection networks. We also discuss the case of spherical networks in great detail, corresponding to the case $\mathcal{M}=S^2=\mathrm{SO}(3)/\mathrm{SO}(2)$. Here we emphasize the use of Fourier analysis involving Wigner matrices, spherical harmonics and Clebsch-Gordan coefficients for $G=\mathrm{SO}(3)$, illustrating the power of representation theory for deep learning.