 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Geometric Inductive Bias for Object Centric Dynamics
Dec 17, 2025Equivariance is a powerful prior for learning physical dynamics, yet exact group equivariance can degrade performance if the symmetries are broken. We propose object-centric world models built with geometric algebra neural networks, providing a soft geometric inductive bias. Our models are evaluated using simulated environments of 2d rigid body dynamics with static obstacles, where we train for next-step predictions autoregressively. For long-horizon rollouts we show that the soft inductive bias of our models results in better performance in terms of physical fidelity compared to non-equivariant baseline models. The approach complements recent soft-equivariance ideas and aligns with the view that simple, well-chosen priors can yield robust generalization. These results suggest that geometric algebra offers an effective middle ground between hand-crafted physics and unstructured deep nets, delivering sample-efficient dynamics models for multi-object scenes.
AXIOM: Learning to Play Games in Minutes with Expanding Object-Centric Models
May 30, 2025Current deep reinforcement learning (DRL) approaches achieve state-of-the-art performance in various domains, but struggle with data efficiency compared to human learning, which leverages core priors about objects and their interactions. Active inference offers a principled framework for integrating sensory information with prior knowledge to learn a world model and quantify the uncertainty of its own beliefs and predictions. However, active inference models are usually crafted for a single task with bespoke knowledge, so they lack the domain flexibility typical of DRL approaches. To bridge this gap, we propose a novel architecture that integrates a minimal yet expressive set of core priors about object-centric dynamics and interactions to accelerate learning in low-data regimes. The resulting approach, which we call AXIOM, combines the usual data efficiency and interpretability of Bayesian approaches with the across-task generalization usually associated with DRL. AXIOM represents scenes as compositions of objects, whose dynamics are modeled as piecewise linear trajectories that capture sparse object-object interactions. The structure of the generative model is expanded online by growing and learning mixture models from single events and periodically refined through Bayesian model reduction to induce generalization. AXIOM masters various games within only 10,000 interaction steps, with both a small number of parameters compared to DRL, and without the computational expense of gradient-based optimization.
PEAR: Equal Area Weather Forecasting on the Sphere
May 23, 2025Machine learning methods for global medium-range weather forecasting have recently received immense attention. Following the publication of the Pangu Weather model, the first deep learning model to outperform traditional numerical simulations of the atmosphere, numerous models have been published in this domain, building on Pangu's success. However, all of these models operate on input data and produce predictions on the Driscoll--Healy discretization of the sphere which suffers from a much finer grid at the poles than around the equator. In contrast, in the Hierarchical Equal Area iso-Latitude Pixelization (HEALPix) of the sphere, each pixel covers the same surface area, removing unphysical biases. Motivated by a growing support for this grid in meteorology and climate sciences, we propose to perform weather forecasting with deep learning models which natively operate on the HEALPix grid. To this end, we introduce Pangu Equal ARea (PEAR), a transformer-based weather forecasting model which operates directly on HEALPix-features and outperforms the corresponding model on Driscoll--Healy without any computational overhead.
Bayesian Predictive Coding
Mar 31, 2025Predictive coding (PC) is an influential theory of information processing in the brain, providing a biologically plausible alternative to backpropagation. It is motivated in terms of Bayesian inference, as hidden states and parameters are optimised via gradient descent on variational free energy. However, implementations of PC rely on maximum \textit{a posteriori} (MAP) estimates of hidden states and maximum likelihood (ML) estimates of parameters, limiting their ability to quantify epistemic uncertainty. In this work, we investigate a Bayesian extension to PC that estimates a posterior distribution over network parameters. This approach, termed Bayesian Predictive coding (BPC), preserves the locality of PC and results in closed-form Hebbian weight updates. Compared to PC, our BPC algorithm converges in fewer epochs in the full-batch setting and remains competitive in the mini-batch setting. Additionally, we demonstrate that BPC offers uncertainty quantification comparable to existing methods in Bayesian deep learning, while also improving convergence properties. Together, these results suggest that BPC provides a biologically plausible method for Bayesian learning in the brain, as well as an attractive approach to uncertainty quantification in deep learning.
Learning Chern Numbers of Topological Insulators with Gauge Equivariant Neural Networks
Feb 21, 2025



Equivariant network architectures are a well-established tool for predicting invariant or equivariant quantities. However, almost all learning problems considered in this context feature a global symmetry, i.e. each point of the underlying space is transformed with the same group element, as opposed to a local ``gauge'' symmetry, where each point is transformed with a different group element, exponentially enlarging the size of the symmetry group. Gauge equivariant networks have so far mainly been applied to problems in quantum chromodynamics. Here, we introduce a novel application domain for gauge-equivariant networks in the theory of topological condensed matter physics. We use gauge equivariant networks to predict topological invariants (Chern numbers) of multiband topological insulators. The gauge symmetry of the network guarantees that the predicted quantity is a topological invariant. We introduce a novel gauge equivariant normalization layer to stabilize the training and prove a universal approximation theorem for our setup. We train on samples with trivial Chern number only but show that our models generalize to samples with non-trivial Chern number. We provide various ablations of our setup. Our code is available at https://github.com/sitronsea/GENet/tree/main.
Uncertainty quantification in fine-tuned LLMs using LoRA ensembles
Feb 19, 2024Fine-tuning large language models can improve task specific performance, although a general understanding of what the fine-tuned model has learned, forgotten and how to trust its predictions is still missing. We derive principled uncertainty quantification for fine-tuned LLMs with posterior approximations using computationally efficient low-rank adaptation ensembles. We analyze three common multiple-choice datasets using low-rank adaptation ensembles based on Mistral-7b, and draw quantitative and qualitative conclusions on their perceived complexity and model efficacy on the different target domains during and after fine-tuning. In particular, backed by the numerical experiments, we hypothesise about signals from entropic uncertainty measures for data domains that are inherently difficult for a given architecture to learn.
HEAL-SWIN: A Vision Transformer On The Sphere
Jul 14, 2023



High-resolution wide-angle fisheye images are becoming more and more important for robotics applications such as autonomous driving. However, using ordinary convolutional neural networks or vision transformers on this data is problematic due to projection and distortion losses introduced when projecting to a rectangular grid on the plane. We introduce the HEAL-SWIN transformer, which combines the highly uniform Hierarchical Equal Area iso-Latitude Pixelation (HEALPix) grid used in astrophysics and cosmology with the Hierarchical Shifted-Window (SWIN) transformer to yield an efficient and flexible model capable of training on high-resolution, distortion-free spherical data. In HEAL-SWIN, the nested structure of the HEALPix grid is used to perform the patching and windowing operations of the SWIN transformer, resulting in a one-dimensional representation of the spherical data with minimal computational overhead. We demonstrate the superior performance of our model for semantic segmentation and depth regression tasks on both synthetic and real automotive datasets. Our code is available at https://github.com/JanEGerken/HEAL-SWIN.
Bayesian posterior approximation with stochastic ensembles
Dec 15, 2022We introduce ensembles of stochastic neural networks to approximate the Bayesian posterior, combining stochastic methods such as dropout with deep ensembles. The stochastic ensembles are formulated as families of distributions and trained to approximate the Bayesian posterior with variational inference. We implement stochastic ensembles based on Monte Carlo dropout, DropConnect and a novel non-parametric version of dropout and evaluate them on a toy problem and CIFAR image classification. For CIFAR, the stochastic ensembles are quantitatively compared to published Hamiltonian Monte Carlo results for a ResNet-20 architecture. We also test the quality of the posteriors directly against Hamiltonian Monte Carlo simulations in a simplified toy model. Our results show that in a number of settings, stochastic ensembles provide more accurate posterior estimates than regular deep ensembles.
Real-time semantic segmentation on FPGAs for autonomous vehicles with hls4ml
May 16, 2022

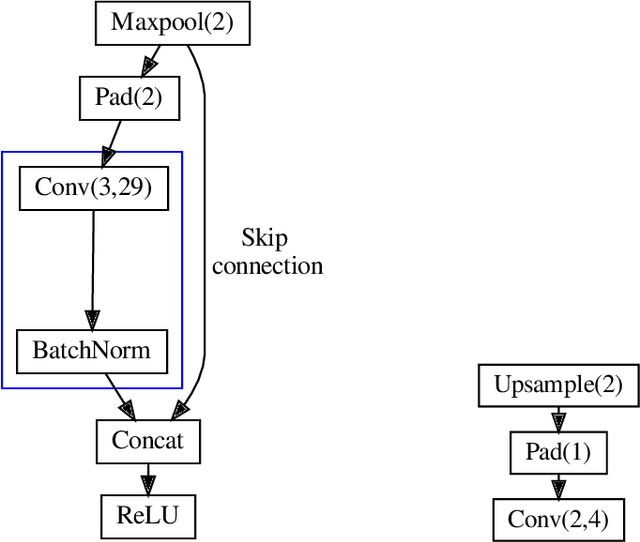
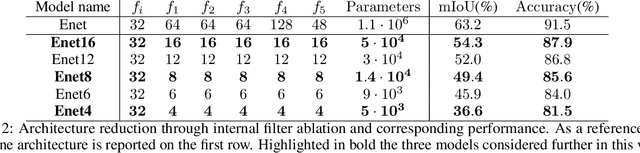
In this paper, we investigate how field programmable gate arrays can serve as hardware accelerators for real-time semantic segmentation tasks relevant for autonomous driving. Considering compressed versions of the ENet convolutional neural network architecture, we demonstrate a fully-on-chip deployment with a latency of 4.9 ms per image, using less than 30% of the available resources on a Xilinx ZCU102 evaluation board. The latency is reduced to 3 ms per image when increasing the batch size to ten, corresponding to the use case where the autonomous vehicle receives inputs from multiple cameras simultaneously. We show, through aggressive filter reduction and heterogeneous quantization-aware training, and an optimized implementation of convolutional layers, that the power consumption and resource utilization can be significantly reduced while maintaining accuracy on the Cityscapes dataset.
Equivariance versus Augmentation for Spherical Images
Feb 08, 2022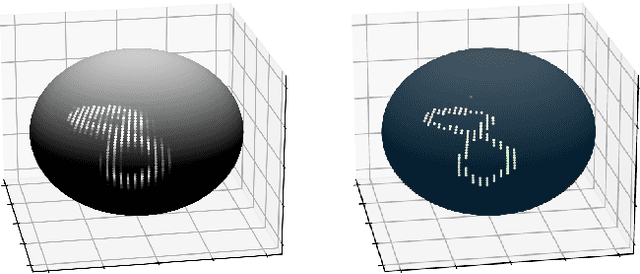
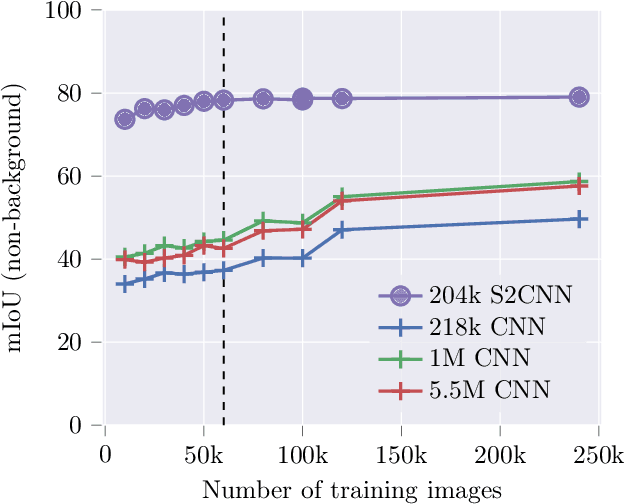
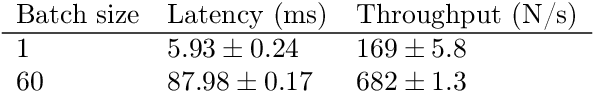
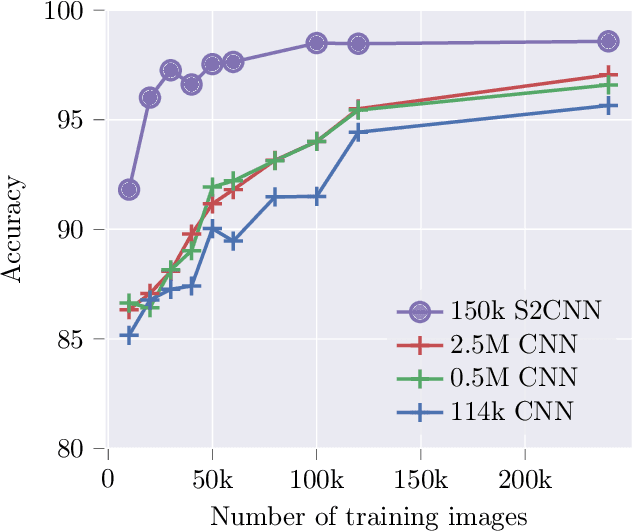
We analyze the role of rotational equivariance in convolutional neural networks (CNNs) applied to spherical images. We compare the performance of the group equivariant networks known as S2CNNs and standard non-equivariant CNNs trained with an increasing amount of data augmentation. The chosen architectures can be considered baseline references for the respective design paradigms. Our models are trained and evaluated on single or multiple items from the MNIST or FashionMNIST dataset projected onto the sphere. For the task of image classification, which is inherently rotationally invariant, we find that by considerably increasing the amount of data augmentation and the size of the networks, it is possible for the standard CNNs to reach at least the same performance as the equivariant network. In contrast, for the inherently equivariant task of semantic segmentation, the non-equivariant networks are consistently outperformed by the equivariant networks with significantly fewer parameters. We also analyze and compare the inference latency and training times of the different networks, enabling detailed tradeoff considerations between equivariant architectures and data augmentation for practical problems. The equivariant spherical networks used in the experiments will be made available at https://github.com/JanEGerken/sem_seg_s2cnn .