 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Continual Learning for Gaussian Splatting based Environments Reconstruction on Commercial Off-the-Shelf Edge Devices
Mar 09, 2026Novel view synthesis (NVS) is increasingly relevant for edge robotics, where compact and incrementally updatable 3D scene models are needed for SLAM, navigation, and inspection under tight memory and latency budgets. Variational Bayesian Gaussian Splatting (VBGS) enables replay-free continual updates for the 3DGS algorithm by maintaining a probabilistic scene model, but its high-precision computations and large intermediate tensors make on-device training impractical. We present a precision-adaptive optimization framework that enables VBGS training on resource-constrained hardware without altering its variational formulation. We (i) profile VBGS to identify memory/latency hotspots, (ii) fuse memory-dominant kernels to reduce materialized intermediate tensors, and (iii) automatically assign operation-level precisions via a mixed-precision search with bounded relative error. Across the Blender, Habitat, and Replica datasets, our optimised pipeline reduces peak memory from 9.44 GB to 1.11 GB and training time from ~234 min to ~61 min on an A5000 GPU, while preserving (and in some cases improving) reconstruction quality of the state-of-the-art VBGS baseline. We also enable for the first time NVS training on a commercial embedded platform, the Jetson Orin Nano, reducing per-frame latency by 19x compared to 3DGS.
Mobile Manipulation with Active Inference for Long-Horizon Rearrangement Tasks
Jul 23, 2025Despite growing interest in active inference for robotic control, its application to complex, long-horizon tasks remains untested. We address this gap by introducing a fully hierarchical active inference architecture for goal-directed behavior in realistic robotic settings. Our model combines a high-level active inference model that selects among discrete skills realized via a whole-body active inference controller. This unified approach enables flexible skill composition, online adaptability, and recovery from task failures without requiring offline training. Evaluated on the Habitat Benchmark for mobile manipulation, our method outperforms state-of-the-art baselines across the three long-horizon tasks, demonstrating for the first time that active inference can scale to the complexity of modern robotics benchmarks.
AXIOM: Learning to Play Games in Minutes with Expanding Object-Centric Models
May 30, 2025Current deep reinforcement learning (DRL) approaches achieve state-of-the-art performance in various domains, but struggle with data efficiency compared to human learning, which leverages core priors about objects and their interactions. Active inference offers a principled framework for integrating sensory information with prior knowledge to learn a world model and quantify the uncertainty of its own beliefs and predictions. However, active inference models are usually crafted for a single task with bespoke knowledge, so they lack the domain flexibility typical of DRL approaches. To bridge this gap, we propose a novel architecture that integrates a minimal yet expressive set of core priors about object-centric dynamics and interactions to accelerate learning in low-data regimes. The resulting approach, which we call AXIOM, combines the usual data efficiency and interpretability of Bayesian approaches with the across-task generalization usually associated with DRL. AXIOM represents scenes as compositions of objects, whose dynamics are modeled as piecewise linear trajectories that capture sparse object-object interactions. The structure of the generative model is expanded online by growing and learning mixture models from single events and periodically refined through Bayesian model reduction to induce generalization. AXIOM masters various games within only 10,000 interaction steps, with both a small number of parameters compared to DRL, and without the computational expense of gradient-based optimization.
Variational Bayes Gaussian Splatting
Oct 04, 2024



Recently, 3D Gaussian Splatting has emerged as a promising approach for modeling 3D scenes using mixtures of Gaussians. The predominant optimization method for these models relies on backpropagating gradients through a differentiable rendering pipeline, which struggles with catastrophic forgetting when dealing with continuous streams of data. To address this limitation, we propose Variational Bayes Gaussian Splatting (VBGS), a novel approach that frames training a Gaussian splat as variational inference over model parameters. By leveraging the conjugacy properties of multivariate Gaussians, we derive a closed-form variational update rule, allowing efficient updates from partial, sequential observations without the need for replay buffers. Our experiments show that VBGS not only matches state-of-the-art performance on static datasets, but also enables continual learning from sequentially streamed 2D and 3D data, drastically improving performance in this setting.
Belief sharing: a blessing or a curse
Jul 02, 2024When collaborating with multiple parties, communicating relevant information is of utmost importance to efficiently completing the tasks at hand. Under active inference, communication can be cast as sharing beliefs between free-energy minimizing agents, where one agent's beliefs get transformed into an observation modality for the other. However, the best approach for transforming beliefs into observations remains an open question. In this paper, we demonstrate that naively sharing posterior beliefs can give rise to the negative social dynamics of echo chambers and self-doubt. We propose an alternate belief sharing strategy which mitigates these issues.
Learning Spatial and Temporal Hierarchies: Hierarchical Active Inference for navigation in Multi-Room Maze Environments
Sep 18, 2023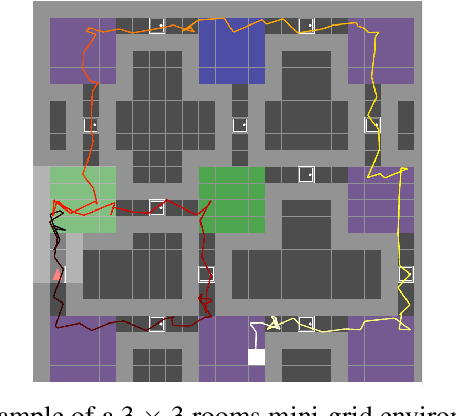
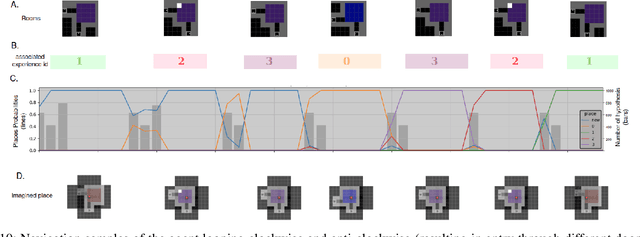
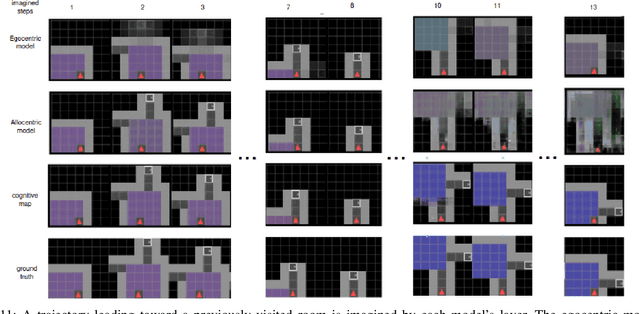
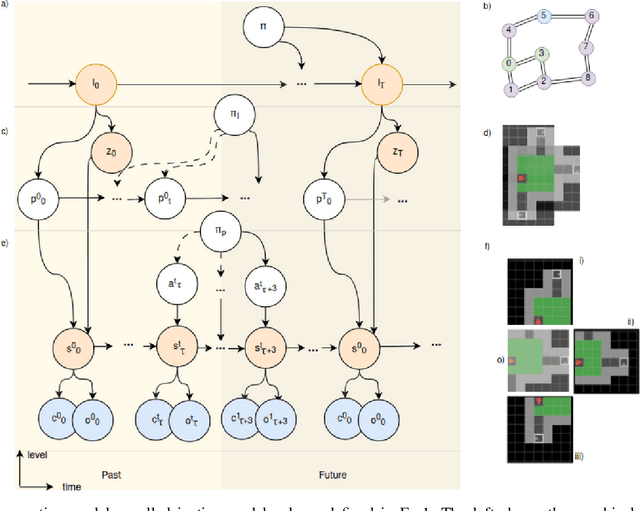
Cognitive maps play a crucial role in facilitating flexible behaviour by representing spatial and conceptual relationships within an environment. The ability to learn and infer the underlying structure of the environment is crucial for effective exploration and navigation. This paper introduces a hierarchical active inference model addressing the challenge of inferring structure in the world from pixel-based observations. We propose a three-layer hierarchical model consisting of a cognitive map, an allocentric, and an egocentric world model, combining curiosity-driven exploration with goal-oriented behaviour at the different levels of reasoning from context to place to motion. This allows for efficient exploration and goal-directed search in room-structured mini-grid environments.
Integrating cognitive map learning and active inference for planning in ambiguous environments
Aug 16, 2023



Living organisms need to acquire both cognitive maps for learning the structure of the world and planning mechanisms able to deal with the challenges of navigating ambiguous environments. Although significant progress has been made in each of these areas independently, the best way to integrate them is an open research question. In this paper, we propose the integration of a statistical model of cognitive map formation within an active inference agent that supports planning under uncertainty. Specifically, we examine the clone-structured cognitive graph (CSCG) model of cognitive map formation and compare a naive clone graph agent with an active inference-driven clone graph agent, in three spatial navigation scenarios. Our findings demonstrate that while both agents are effective in simple scenarios, the active inference agent is more effective when planning in challenging scenarios, in which sensory observations provide ambiguous information about location.
Inferring Hierarchical Structure in Multi-Room Maze Environments
Jun 23, 2023

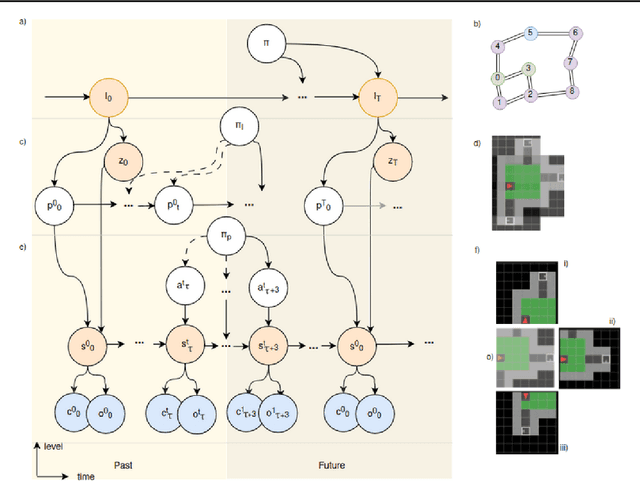

Cognitive maps play a crucial role in facilitating flexible behaviour by representing spatial and conceptual relationships within an environment. The ability to learn and infer the underlying structure of the environment is crucial for effective exploration and navigation. This paper introduces a hierarchical active inference model addressing the challenge of inferring structure in the world from pixel-based observations. We propose a three-layer hierarchical model consisting of a cognitive map, an allocentric, and an egocentric world model, combining curiosity-driven exploration with goal-oriented behaviour at the different levels of reasoning from context to place to motion. This allows for efficient exploration and goal-directed search in room-structured mini-grid environments.
Symmetry and Complexity in Object-Centric Deep Active Inference Models
Apr 14, 2023



Humans perceive and interact with hundreds of objects every day. In doing so, they need to employ mental models of these objects and often exploit symmetries in the object's shape and appearance in order to learn generalizable and transferable skills. Active inference is a first principles approach to understanding and modeling sentient agents. It states that agents entertain a generative model of their environment, and learn and act by minimizing an upper bound on their surprisal, i.e. their Free Energy. The Free Energy decomposes into an accuracy and complexity term, meaning that agents favor the least complex model, that can accurately explain their sensory observations. In this paper, we investigate how inherent symmetries of particular objects also emerge as symmetries in the latent state space of the generative model learnt under deep active inference. In particular, we focus on object-centric representations, which are trained from pixels to predict novel object views as the agent moves its viewpoint. First, we investigate the relation between model complexity and symmetry exploitation in the state space. Second, we do a principal component analysis to demonstrate how the model encodes the principal axis of symmetry of the object in the latent space. Finally, we also demonstrate how more symmetrical representations can be exploited for better generalization in the context of manipulation.
Object-Centric Scene Representations using Active Inference
Feb 07, 2023Representing a scene and its constituent objects from raw sensory data is a core ability for enabling robots to interact with their environment. In this paper, we propose a novel approach for scene understanding, leveraging a hierarchical object-centric generative model that enables an agent to infer object category and pose in an allocentric reference frame using active inference, a neuro-inspired framework for action and perception. For evaluating the behavior of an active vision agent, we also propose a new benchmark where, given a target viewpoint of a particular object, the agent needs to find the best matching viewpoint given a workspace with randomly positioned objects in 3D. We demonstrate that our active inference agent is able to balance epistemic foraging and goal-driven behavior, and outperforms both supervised and reinforcement learning baselines by a large margin.