 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$μ$PC: Scaling Predictive Coding to 100+ Layer Networks
May 19, 2025



The biological implausibility of backpropagation (BP) has motivated many alternative, brain-inspired algorithms that attempt to rely only on local information, such as predictive coding (PC) and equilibrium propagation. However, these algorithms have notoriously struggled to train very deep networks, preventing them from competing with BP in large-scale settings. Indeed, scaling PC networks (PCNs) has recently been posed as a challenge for the community (Pinchetti et al., 2024). Here, we show that 100+ layer PCNs can be trained reliably using a Depth-$\mu$P parameterisation (Yang et al., 2023; Bordelon et al., 2023) which we call "$\mu$PC". Through an extensive analysis of the scaling behaviour of PCNs, we reveal several pathologies that make standard PCNs difficult to train at large depths. We then show that, despite addressing only some of these instabilities, $\mu$PC allows stable training of very deep (up to 128-layer) residual networks on simple classification tasks with competitive performance and little tuning compared to current benchmarks. Moreover, $\mu$PC enables zero-shot transfer of both weight and activity learning rates across widths and depths. Our results have implications for other local algorithms and could be extended to convolutional and transformer architectures. Code for $\mu$PC is made available as part of a JAX library for PCNs at https://github.com/thebuckleylab/jpc (Innocenti et al., 2024).
JPC: Flexible Inference for Predictive Coding Networks in JAX
Dec 04, 2024



We introduce JPC, a JAX library for training neural networks with Predictive Coding. JPC provides a simple, fast and flexible interface to train a variety of PC networks (PCNs) including discriminative, generative and hybrid models. Unlike existing libraries, JPC leverages ordinary differential equation solvers to integrate the gradient flow inference dynamics of PCNs. We find that a second-order solver achieves significantly faster runtimes compared to standard Euler integration, with comparable performance on a range of tasks and network depths. JPC also provides some theoretical tools that can be used to study PCNs. We hope that JPC will facilitate future research of PC. The code is available at https://github.com/thebuckleylab/jpc.
Variational Bayes Gaussian Splatting
Oct 04, 2024



Recently, 3D Gaussian Splatting has emerged as a promising approach for modeling 3D scenes using mixtures of Gaussians. The predominant optimization method for these models relies on backpropagating gradients through a differentiable rendering pipeline, which struggles with catastrophic forgetting when dealing with continuous streams of data. To address this limitation, we propose Variational Bayes Gaussian Splatting (VBGS), a novel approach that frames training a Gaussian splat as variational inference over model parameters. By leveraging the conjugacy properties of multivariate Gaussians, we derive a closed-form variational update rule, allowing efficient updates from partial, sequential observations without the need for replay buffers. Our experiments show that VBGS not only matches state-of-the-art performance on static datasets, but also enables continual learning from sequentially streamed 2D and 3D data, drastically improving performance in this setting.
R-AIF: Solving Sparse-Reward Robotic Tasks from Pixels with Active Inference and World Models
Sep 21, 2024
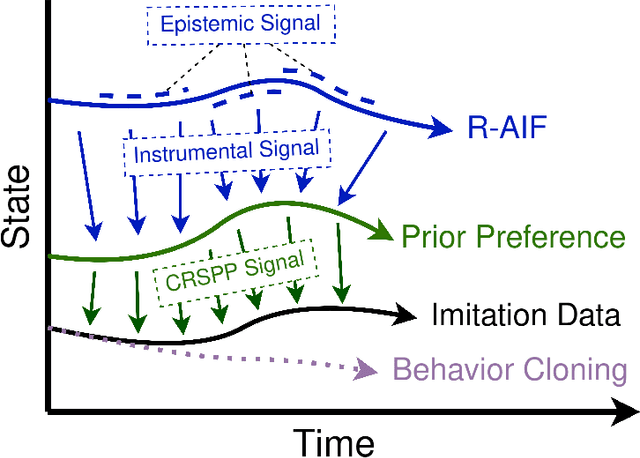
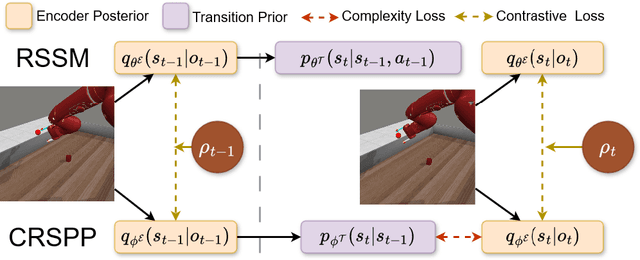
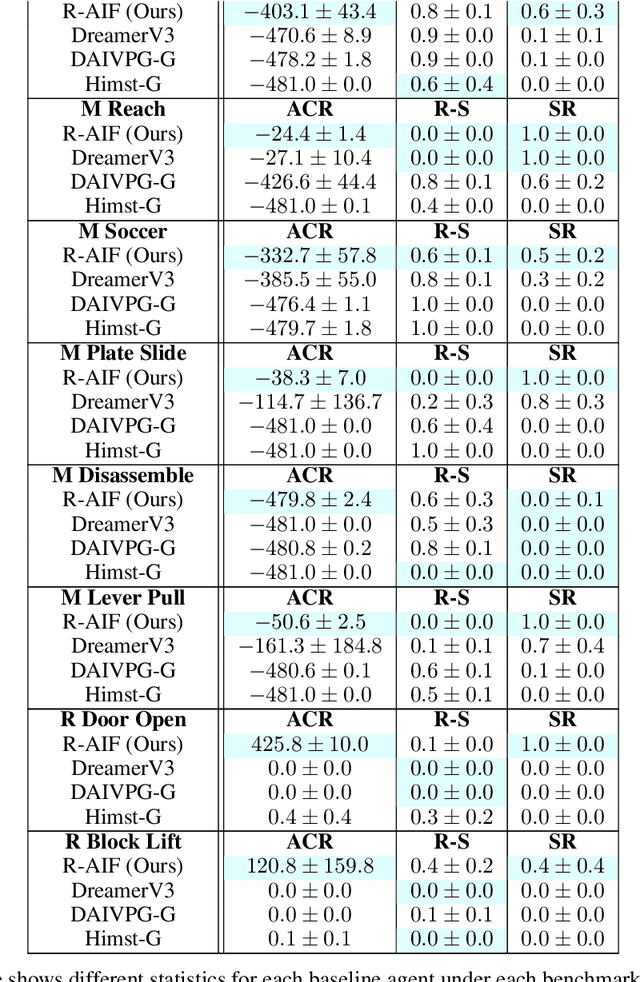
Although research has produced promising results demonstrating the utility of active inference (AIF) in Markov decision processes (MDPs), there is relatively less work that builds AIF models in the context of environments and problems that take the form of partially observable Markov decision processes (POMDPs). In POMDP scenarios, the agent must infer the unobserved environmental state from raw sensory observations, e.g., pixels in an image. Additionally, less work exists in examining the most difficult form of POMDP-centered control: continuous action space POMDPs under sparse reward signals. In this work, we address issues facing the AIF modeling paradigm by introducing novel prior preference learning techniques and self-revision schedules to help the agent excel in sparse-reward, continuous action, goal-based robotic control POMDP environments. Empirically, we show that our agents offer improved performance over state-of-the-art models in terms of cumulative rewards, relative stability, and success rate. The code in support of this work can be found at https://github.com/NACLab/robust-active-inference.
Exploring Action-Centric Representations Through the Lens of Rate-Distortion Theory
Sep 13, 2024Organisms have to keep track of the information in the environment that is relevant for adaptive behaviour. Transmitting information in an economical and efficient way becomes crucial for limited-resourced agents living in high-dimensional environments. The efficient coding hypothesis claims that organisms seek to maximize the information about the sensory input in an efficient manner. Under Bayesian inference, this means that the role of the brain is to efficiently allocate resources in order to make predictions about the hidden states that cause sensory data. However, neither of those frameworks accounts for how that information is exploited downstream, leaving aside the action-oriented role of the perceptual system. Rate-distortion theory, which defines optimal lossy compression under constraints, has gained attention as a formal framework to explore goal-oriented efficient coding. In this work, we explore action-centric representations in the context of rate-distortion theory. We also provide a mathematical definition of abstractions and we argue that, as a summary of the relevant details, they can be used to fix the content of action-centric representations. We model action-centric representations using VAEs and we find that such representations i) are efficient lossy compressions of the data; ii) capture the task-dependent invariances necessary to achieve successful behaviour; and iii) are not in service of reconstructing the data. Thus, we conclude that full reconstruction of the data is rarely needed to achieve optimal behaviour, consistent with a teleological approach to perception.
Only Strict Saddles in the Energy Landscape of Predictive Coding Networks?
Aug 21, 2024



Predictive coding (PC) is an energy-based learning algorithm that performs iterative inference over network activities before weight updates. Recent work suggests that PC can converge in fewer learning steps than backpropagation thanks to its inference procedure. However, these advantages are not always observed, and the impact of PC inference on learning is theoretically not well understood. Here, we study the geometry of the PC energy landscape at the (inference) equilibrium of the network activities. For deep linear networks, we first show that the equilibrated energy is simply a rescaled mean squared error loss with a weight-dependent rescaling. We then prove that many highly degenerate (non-strict) saddles of the loss including the origin become much easier to escape (strict) in the equilibrated energy. Our theory is validated by experiments on both linear and non-linear networks. Based on these results, we conjecture that all the saddles of the equilibrated energy are strict. Overall, this work suggests that PC inference makes the loss landscape more benign and robust to vanishing gradients, while also highlighting the challenge of speeding up PC inference on large-scale models.
Active Inference and Intentional Behaviour
Dec 16, 2023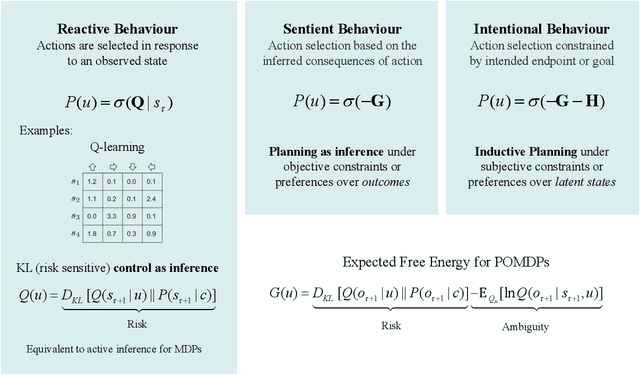
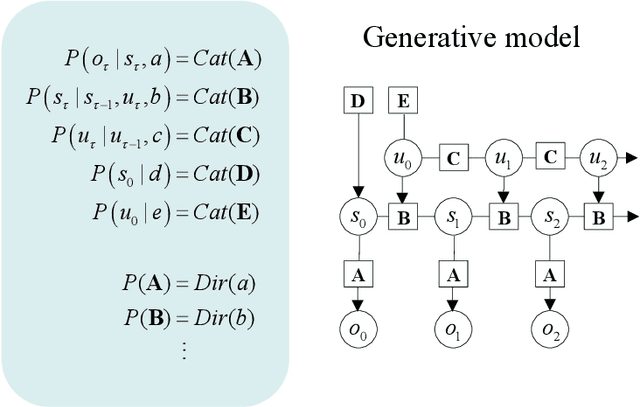

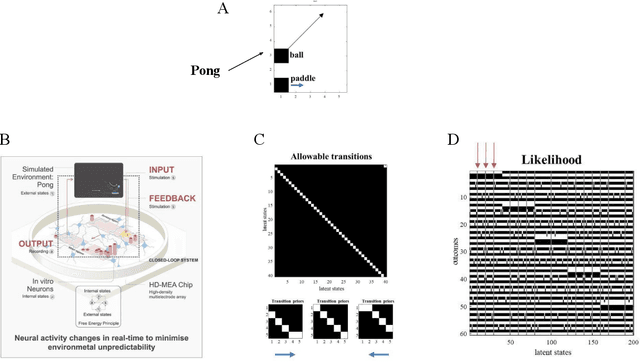
Recent advances in theoretical biology suggest that basal cognition and sentient behaviour are emergent properties of in vitro cell cultures and neuronal networks, respectively. Such neuronal networks spontaneously learn structured behaviours in the absence of reward or reinforcement. In this paper, we characterise this kind of self-organisation through the lens of the free energy principle, i.e., as self-evidencing. We do this by first discussing the definitions of reactive and sentient behaviour in the setting of active inference, which describes the behaviour of agents that model the consequences of their actions. We then introduce a formal account of intentional behaviour, that describes agents as driven by a preferred endpoint or goal in latent state-spaces. We then investigate these forms of (reactive, sentient, and intentional) behaviour using simulations. First, we simulate the aforementioned in vitro experiments, in which neuronal cultures spontaneously learn to play Pong, by implementing nested, free energy minimising processes. The simulations are then used to deconstruct the ensuing predictive behaviour, leading to the distinction between merely reactive, sentient, and intentional behaviour, with the latter formalised in terms of inductive planning. This distinction is further studied using simple machine learning benchmarks (navigation in a grid world and the Tower of Hanoi problem), that show how quickly and efficiently adaptive behaviour emerges under an inductive form of active inference.
Brain-Inspired Computational Intelligence via Predictive Coding
Aug 15, 2023



Artificial intelligence (AI) is rapidly becoming one of the key technologies of this century. The majority of results in AI thus far have been achieved using deep neural networks trained with the error backpropagation learning algorithm. However, the ubiquitous adoption of this approach has highlighted some important limitations such as substantial computational cost, difficulty in quantifying uncertainty, lack of robustness, unreliability, and biological implausibility. It is possible that addressing these limitations may require schemes that are inspired and guided by neuroscience theories. One such theory, called predictive coding (PC), has shown promising performance in machine intelligence tasks, exhibiting exciting properties that make it potentially valuable for the machine learning community: PC can model information processing in different brain areas, can be used in cognitive control and robotics, and has a solid mathematical grounding in variational inference, offering a powerful inversion scheme for a specific class of continuous-state generative models. With the hope of foregrounding research in this direction, we survey the literature that has contributed to this perspective, highlighting the many ways that PC might play a role in the future of machine learning and computational intelligence at large.
Understanding Predictive Coding as an Adaptive Trust-Region Method
May 29, 2023


Predictive coding (PC) is a brain-inspired local learning algorithm that has recently been suggested to provide advantages over backpropagation (BP) in biologically relevant scenarios. While theoretical work has mainly focused on showing how PC can approximate BP in various limits, the putative benefits of "natural" PC are less understood. Here we develop a theory of PC as an adaptive trust-region (TR) algorithm that uses second-order information. We show that the learning dynamics of PC can be interpreted as interpolating between BP's loss gradient direction and a TR direction found by the PC inference dynamics. Our theory suggests that PC should escape saddle points faster than BP, a prediction which we prove in a shallow linear model and support with experiments on deeper networks. This work lays a foundation for understanding PC in deep and wide networks.
Attention: Marginal Probability is All You Need?
Apr 07, 2023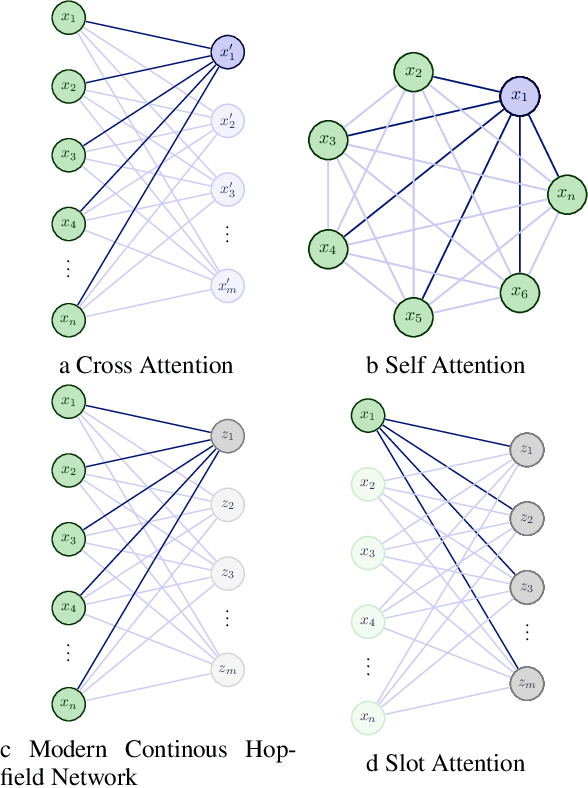
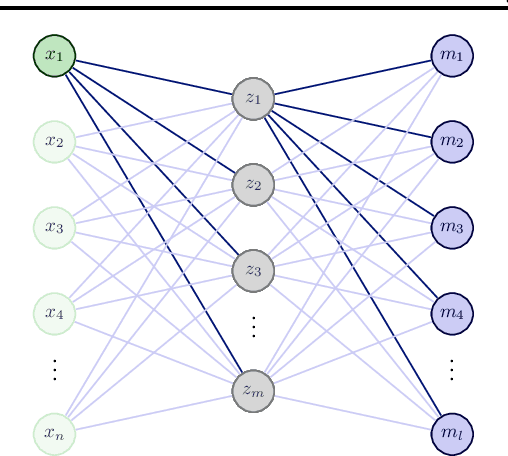
Attention mechanisms are a central property of cognitive systems allowing them to selectively deploy cognitive resources in a flexible manner. Attention has been long studied in the neurosciences and there are numerous phenomenological models that try to capture its core properties. Recently attentional mechanisms have become a dominating architectural choice of machine learning and are the central innovation of Transformers. The dominant intuition and formalism underlying their development has drawn on ideas of keys and queries in database management systems. In this work, we propose an alternative Bayesian foundation for attentional mechanisms and show how this unifies different attentional architectures in machine learning. This formulation allows to to identify commonality across different attention ML architectures as well as suggest a bridge to those developed in neuroscience. We hope this work will guide more sophisticated intuitions into the key properties of attention architectures and suggest new ones.