 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Biological Intelligence: Active Inference with Experiment-Informed Generative Model
Aug 09, 2025With recent and rapid advancements in artificial intelligence (AI), understanding the foundation of purposeful behaviour in autonomous agents is crucial for developing safe and efficient systems. While artificial neural networks have dominated the path to AI, recent studies are exploring the potential of biologically based systems, such as networks of living biological neuronal networks. Along with promises of high power and data efficiency, these systems may also inform more explainable and biologically plausible models. In this work, we propose a framework rooted in active inference, a general theory of behaviour, to model decision-making in embodied agents. Using experiment-informed generative models, we simulate decision-making processes in a simulated game-play environment, mirroring experimental setups that use biological neurons. Our results demonstrate learning in these agents, providing insights into the role of memory-based learning and predictive planning in intelligent decision-making. This work contributes to the growing field of explainable AI by offering a biologically grounded and scalable approach to understanding purposeful behaviour in agents.
Biological Neurons Compete with Deep Reinforcement Learning in Sample Efficiency in a Simulated Gameworld
May 27, 2024How do biological systems and machine learning algorithms compare in the number of samples required to show significant improvements in completing a task? We compared the learning efficiency of in vitro biological neural networks to the state-of-the-art deep reinforcement learning (RL) algorithms in a simplified simulation of the game `Pong'. Using DishBrain, a system that embodies in vitro neural networks with in silico computation using a high-density multi-electrode array, we contrasted the learning rate and the performance of these biological systems against time-matched learning from three state-of-the-art deep RL algorithms (i.e., DQN, A2C, and PPO) in the same game environment. This allowed a meaningful comparison between biological neural systems and deep RL. We find that when samples are limited to a real-world time course, even these very simple biological cultures outperformed deep RL algorithms across various game performance characteristics, implying a higher sample efficiency. Ultimately, even when tested across multiple types of information input to assess the impact of higher dimensional data input, biological neurons showcased faster learning than all deep reinforcement learning agents.
On Predictive planning and counterfactual learning in active inference
Mar 19, 2024
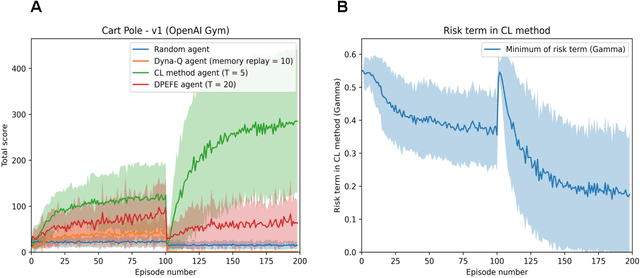
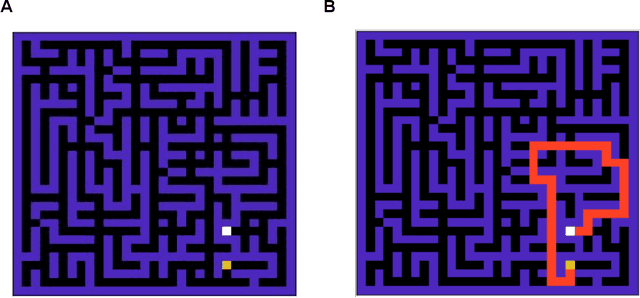
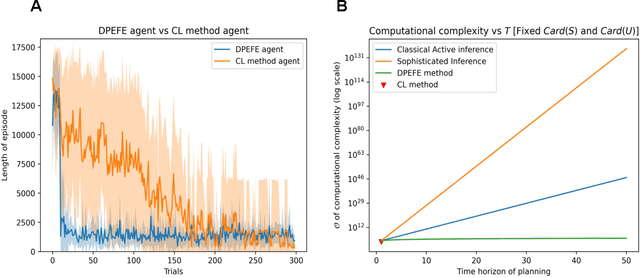
Given the rapid advancement of artificial intelligence, understanding the foundations of intelligent behaviour is increasingly important. Active inference, regarded as a general theory of behaviour, offers a principled approach to probing the basis of sophistication in planning and decision-making. In this paper, we examine two decision-making schemes in active inference based on 'planning' and 'learning from experience'. Furthermore, we also introduce a mixed model that navigates the data-complexity trade-off between these strategies, leveraging the strengths of both to facilitate balanced decision-making. We evaluate our proposed model in a challenging grid-world scenario that requires adaptability from the agent. Additionally, our model provides the opportunity to analyze the evolution of various parameters, offering valuable insights and contributing to an explainable framework for intelligent decision-making.
Active Inference and Intentional Behaviour
Dec 16, 2023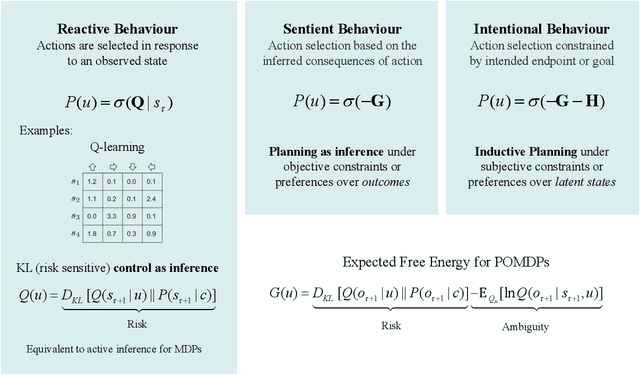
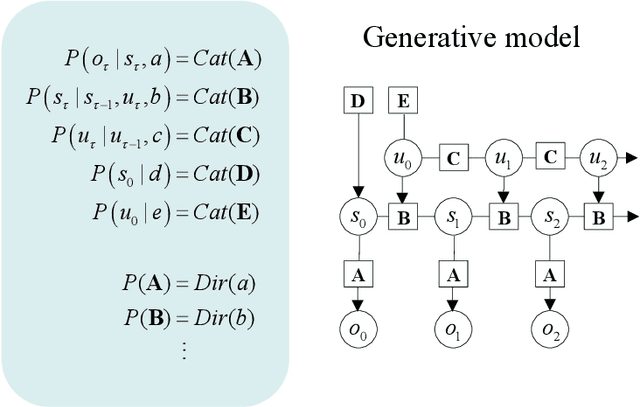

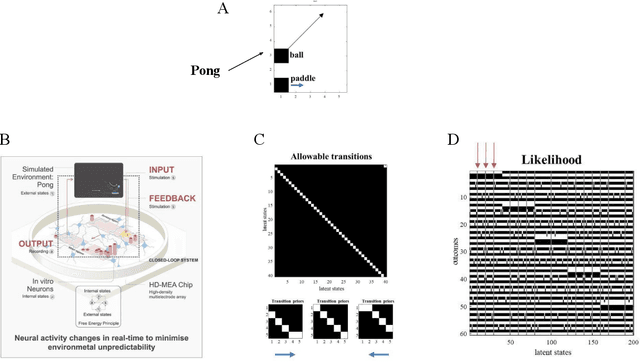
Recent advances in theoretical biology suggest that basal cognition and sentient behaviour are emergent properties of in vitro cell cultures and neuronal networks, respectively. Such neuronal networks spontaneously learn structured behaviours in the absence of reward or reinforcement. In this paper, we characterise this kind of self-organisation through the lens of the free energy principle, i.e., as self-evidencing. We do this by first discussing the definitions of reactive and sentient behaviour in the setting of active inference, which describes the behaviour of agents that model the consequences of their actions. We then introduce a formal account of intentional behaviour, that describes agents as driven by a preferred endpoint or goal in latent state-spaces. We then investigate these forms of (reactive, sentient, and intentional) behaviour using simulations. First, we simulate the aforementioned in vitro experiments, in which neuronal cultures spontaneously learn to play Pong, by implementing nested, free energy minimising processes. The simulations are then used to deconstruct the ensuing predictive behaviour, leading to the distinction between merely reactive, sentient, and intentional behaviour, with the latter formalised in terms of inductive planning. This distinction is further studied using simple machine learning benchmarks (navigation in a grid world and the Tower of Hanoi problem), that show how quickly and efficiently adaptive behaviour emerges under an inductive form of active inference.
On efficient computation in active inference
Jul 02, 2023



Despite being recognized as neurobiologically plausible, active inference faces difficulties when employed to simulate intelligent behaviour in complex environments due to its computational cost and the difficulty of specifying an appropriate target distribution for the agent. This paper introduces two solutions that work in concert to address these limitations. First, we present a novel planning algorithm for finite temporal horizons with drastically lower computational complexity. Second, inspired by Z-learning from control theory literature, we simplify the process of setting an appropriate target distribution for new and existing active inference planning schemes. Our first approach leverages the dynamic programming algorithm, known for its computational efficiency, to minimize the cost function used in planning through the Bellman-optimality principle. Accordingly, our algorithm recursively assesses the expected free energy of actions in the reverse temporal order. This improves computational efficiency by orders of magnitude and allows precise model learning and planning, even under uncertain conditions. Our method simplifies the planning process and shows meaningful behaviour even when specifying only the agent's final goal state. The proposed solutions make defining a target distribution from a goal state straightforward compared to the more complicated task of defining a temporally informed target distribution. The effectiveness of these methods is tested and demonstrated through simulations in standard grid-world tasks. These advances create new opportunities for various applications.
Active Inference for Stochastic Control
Aug 27, 2021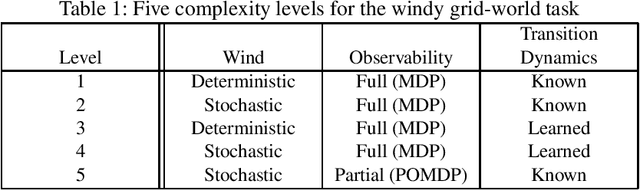
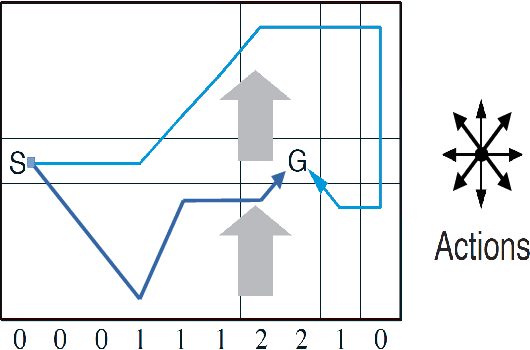

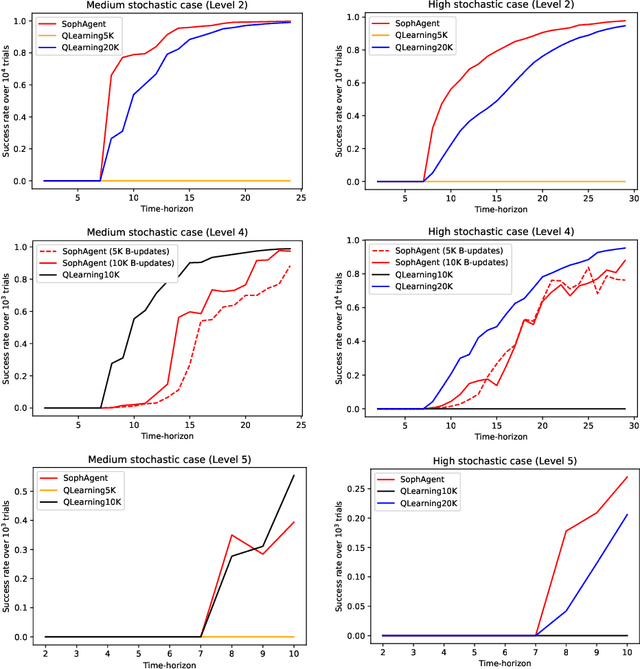
Active inference has emerged as an alternative approach to control problems given its intuitive (probabilistic) formalism. However, despite its theoretical utility, computational implementations have largely been restricted to low-dimensional, deterministic settings. This paper highlights that this is a consequence of the inability to adequately model stochastic transition dynamics, particularly when an extensive policy (i.e., action trajectory) space must be evaluated during planning. Fortunately, recent advancements propose a modified planning algorithm for finite temporal horizons. We build upon this work to assess the utility of active inference for a stochastic control setting. For this, we simulate the classic windy grid-world task with additional complexities, namely: 1) environment stochasticity; 2) learning of transition dynamics; and 3) partial observability. Our results demonstrate the advantage of using active inference, compared to reinforcement learning, in both deterministic and stochastic settings.