 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive inference and artificial reasoning
Dec 24, 2025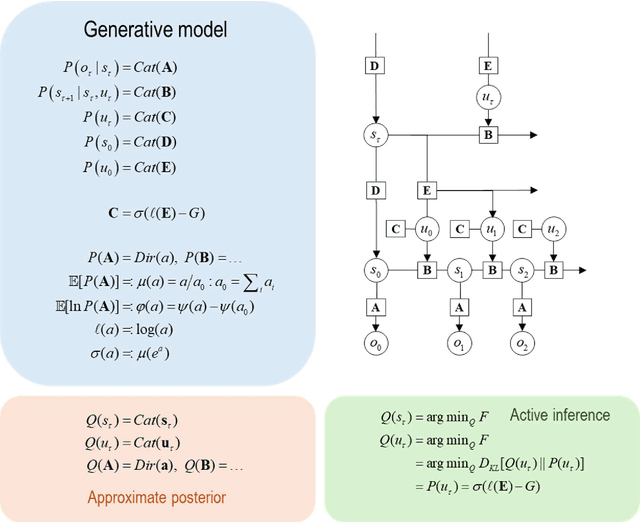
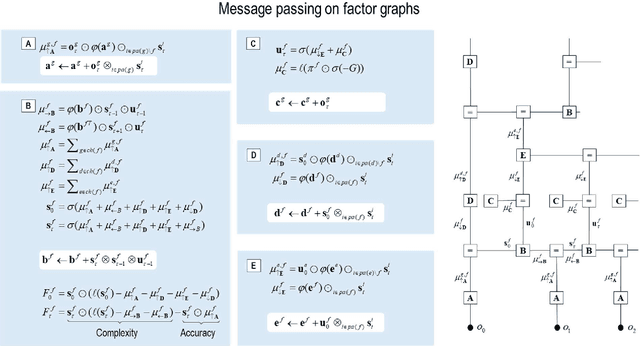
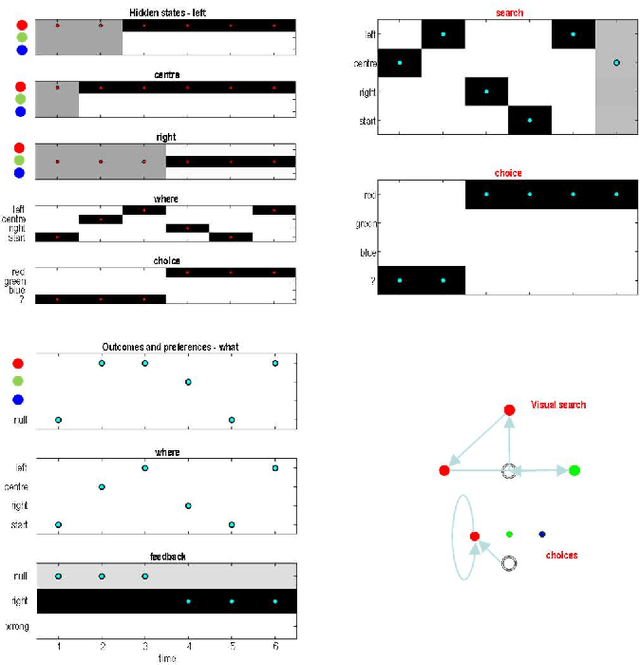
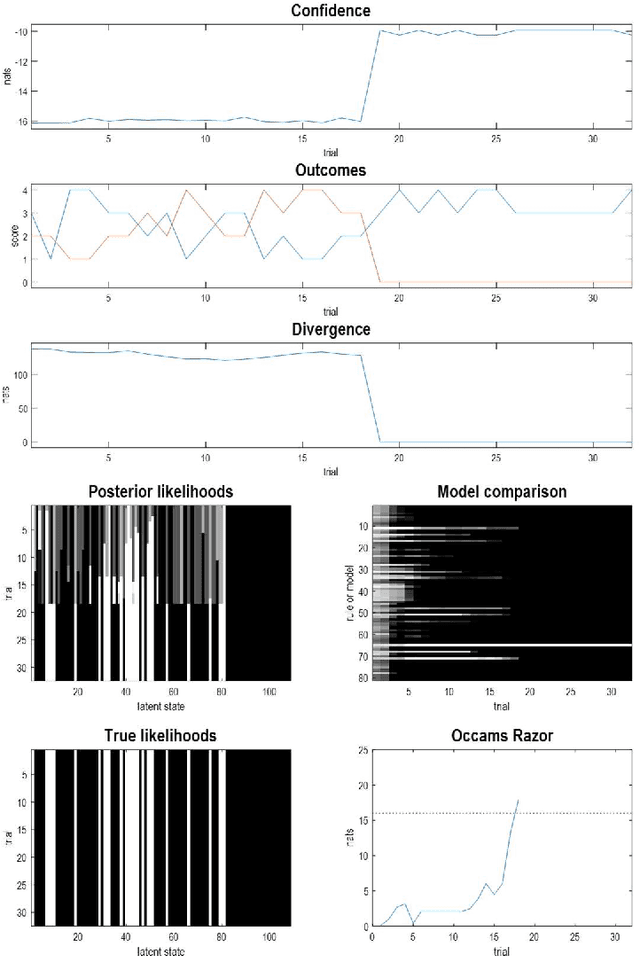
This technical note considers the sampling of outcomes that provide the greatest amount of information about the structure of underlying world models. This generalisation furnishes a principled approach to structure learning under a plausible set of generative models or hypotheses. In active inference, policies - i.e., combinations of actions - are selected based on their expected free energy, which comprises expected information gain and value. Information gain corresponds to the KL divergence between predictive posteriors with, and without, the consequences of action. Posteriors over models can be evaluated quickly and efficiently using Bayesian Model Reduction, based upon accumulated posterior beliefs about model parameters. The ensuing information gain can then be used to select actions that disambiguate among alternative models, in the spirit of optimal experimental design. We illustrate this kind of active selection or reasoning using partially observed discrete models; namely, a 'three-ball' paradigm used previously to describe artificial insight and 'aha moments' via (synthetic) introspection or sleep. We focus on the sample efficiency afforded by seeking outcomes that resolve the greatest uncertainty about the world model, under which outcomes are generated.
From pixels to planning: scale-free active inference
Jul 27, 2024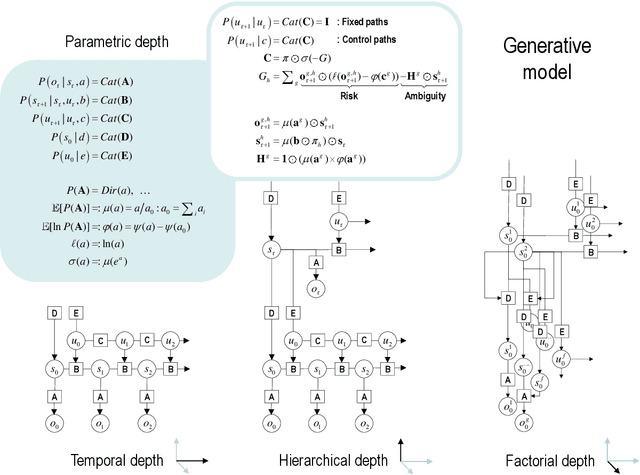
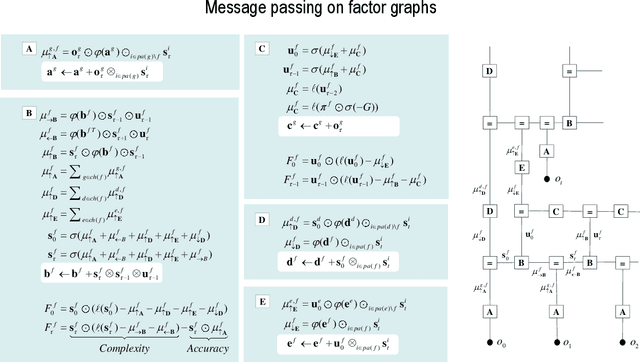
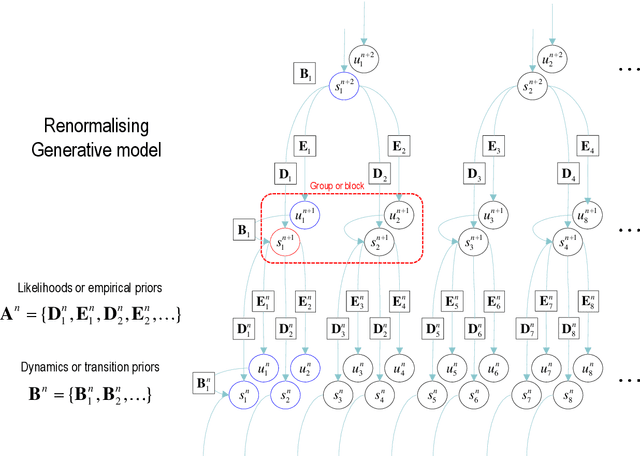
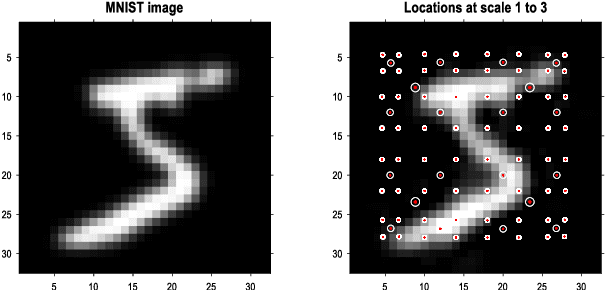
This paper describes a discrete state-space model -- and accompanying methods -- for generative modelling. This model generalises partially observed Markov decision processes to include paths as latent variables, rendering it suitable for active inference and learning in a dynamic setting. Specifically, we consider deep or hierarchical forms using the renormalisation group. The ensuing renormalising generative models (RGM) can be regarded as discrete homologues of deep convolutional neural networks or continuous state-space models in generalised coordinates of motion. By construction, these scale-invariant models can be used to learn compositionality over space and time, furnishing models of paths or orbits; i.e., events of increasing temporal depth and itinerancy. This technical note illustrates the automatic discovery, learning and deployment of RGMs using a series of applications. We start with image classification and then consider the compression and generation of movies and music. Finally, we apply the same variational principles to the learning of Atari-like games.
Active Inference and Intentional Behaviour
Dec 16, 2023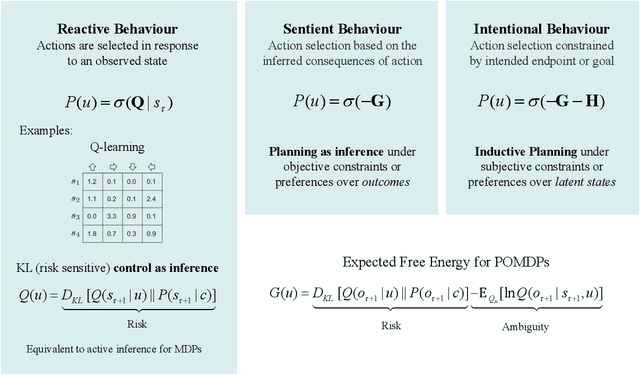
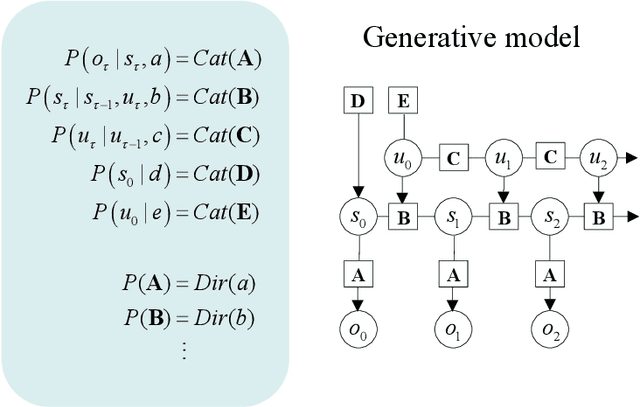

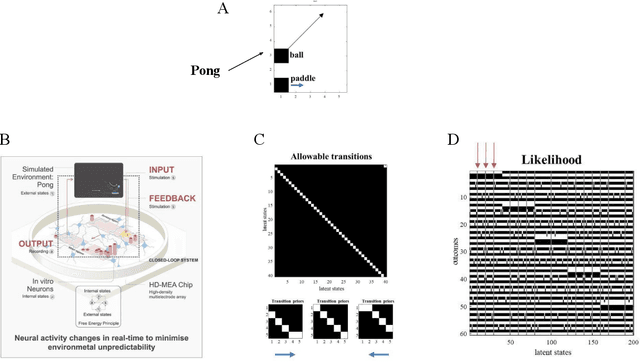
Recent advances in theoretical biology suggest that basal cognition and sentient behaviour are emergent properties of in vitro cell cultures and neuronal networks, respectively. Such neuronal networks spontaneously learn structured behaviours in the absence of reward or reinforcement. In this paper, we characterise this kind of self-organisation through the lens of the free energy principle, i.e., as self-evidencing. We do this by first discussing the definitions of reactive and sentient behaviour in the setting of active inference, which describes the behaviour of agents that model the consequences of their actions. We then introduce a formal account of intentional behaviour, that describes agents as driven by a preferred endpoint or goal in latent state-spaces. We then investigate these forms of (reactive, sentient, and intentional) behaviour using simulations. First, we simulate the aforementioned in vitro experiments, in which neuronal cultures spontaneously learn to play Pong, by implementing nested, free energy minimising processes. The simulations are then used to deconstruct the ensuing predictive behaviour, leading to the distinction between merely reactive, sentient, and intentional behaviour, with the latter formalised in terms of inductive planning. This distinction is further studied using simple machine learning benchmarks (navigation in a grid world and the Tower of Hanoi problem), that show how quickly and efficiently adaptive behaviour emerges under an inductive form of active inference.
Supervised structure learning
Nov 17, 2023



This paper concerns structure learning or discovery of discrete generative models. It focuses on Bayesian model selection and the assimilation of training data or content, with a special emphasis on the order in which data are ingested. A key move - in the ensuing schemes - is to place priors on the selection of models, based upon expected free energy. In this setting, expected free energy reduces to a constrained mutual information, where the constraints inherit from priors over outcomes (i.e., preferred outcomes). The resulting scheme is first used to perform image classification on the MNIST dataset to illustrate the basic idea, and then tested on a more challenging problem of discovering models with dynamics, using a simple sprite-based visual disentanglement paradigm and the Tower of Hanoi (cf., blocks world) problem. In these examples, generative models are constructed autodidactically to recover (i.e., disentangle) the factorial structure of latent states - and their characteristic paths or dynamics.
Reclaiming saliency: rhythmic precision-modulated action and perception
Mar 23, 2022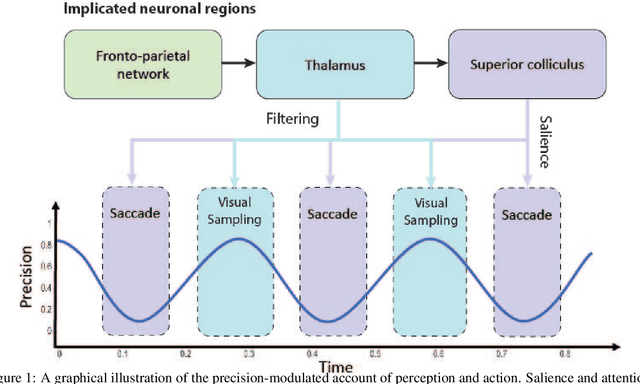

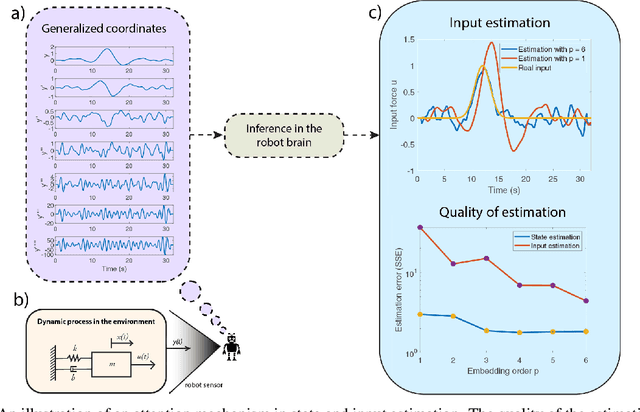
Computational models of visual attention in artificial intelligence and robotics have been inspired by the concept of a saliency map. These models account for the mutual information between the (current) visual information and its estimated causes. However, they fail to consider the circular causality between perception and action. In other words, they do not consider where to sample next, given current beliefs. Here, we reclaim salience as an active inference process that relies on two basic principles: uncertainty minimisation and rhythmic scheduling. For this, we make a distinction between attention and salience. Briefly, we associate attention with precision control, i.e., the confidence with which beliefs can be updated given sampled sensory data, and salience with uncertainty minimisation that underwrites the selection of future sensory data. Using this, we propose a new account of attention based on rhythmic precision-modulation and discuss its potential in robotics, providing numerical experiments that showcase advantages of precision-modulation for state and noise estimation, system identification and action selection for informative path planning.
Active inference, Bayesian optimal design, and expected utility
Sep 21, 2021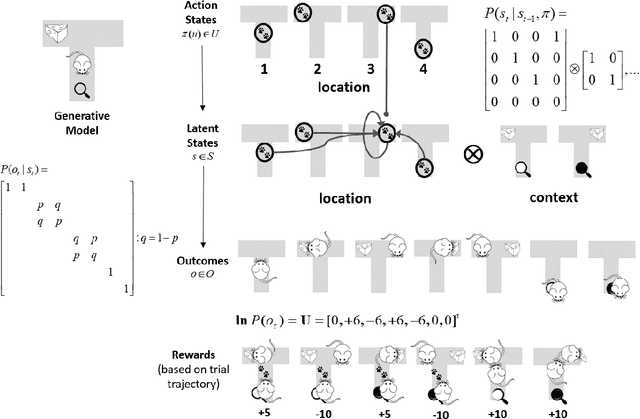
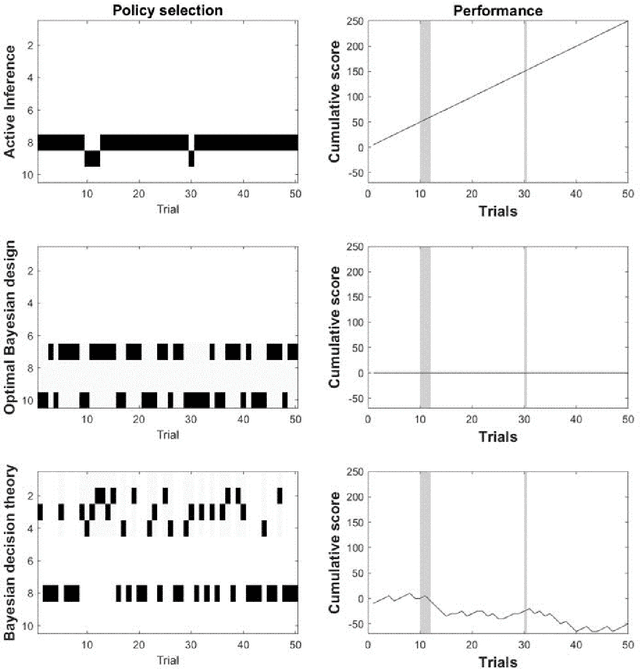
Active inference, a corollary of the free energy principle, is a formal way of describing the behavior of certain kinds of random dynamical systems that have the appearance of sentience. In this chapter, we describe how active inference combines Bayesian decision theory and optimal Bayesian design principles under a single imperative to minimize expected free energy. It is this aspect of active inference that allows for the natural emergence of information-seeking behavior. When removing prior outcomes preferences from expected free energy, active inference reduces to optimal Bayesian design, i.e., information gain maximization. Conversely, active inference reduces to Bayesian decision theory in the absence of ambiguity and relative risk, i.e., expected utility maximization. Using these limiting cases, we illustrate how behaviors differ when agents select actions that optimize expected utility, expected information gain, and expected free energy. Our T-maze simulations show optimizing expected free energy produces goal-directed information-seeking behavior while optimizing expected utility induces purely exploitive behavior and maximizing information gain engenders intrinsically motivated behavior.
Bayesian brains and the Rényi divergence
Jul 12, 2021
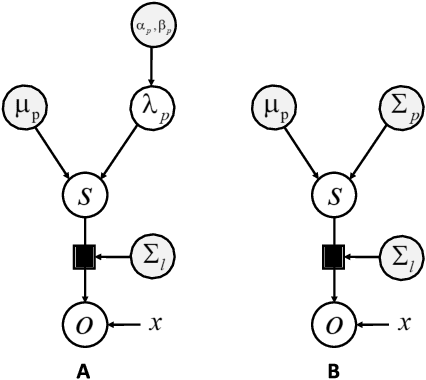
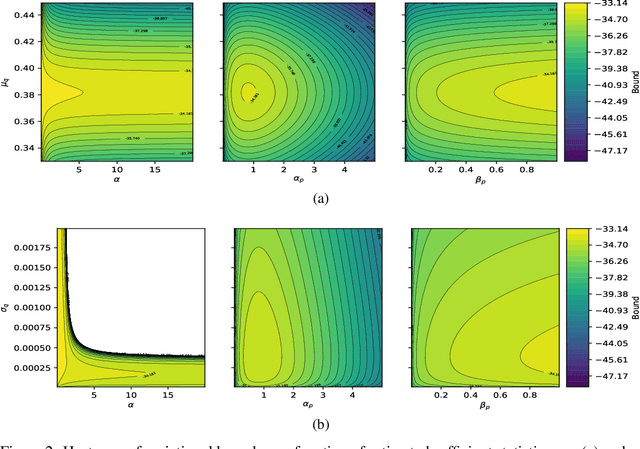
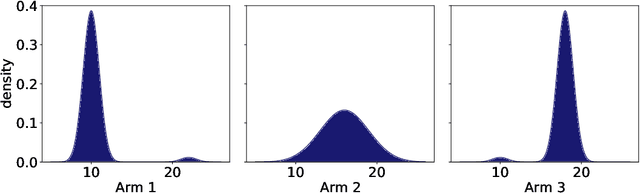
Under the Bayesian brain hypothesis, behavioural variations can be attributed to different priors over generative model parameters. This provides a formal explanation for why individuals exhibit inconsistent behavioural preferences when confronted with similar choices. For example, greedy preferences are a consequence of confident (or precise) beliefs over certain outcomes. Here, we offer an alternative account of behavioural variability using R\'enyi divergences and their associated variational bounds. R\'enyi bounds are analogous to the variational free energy (or evidence lower bound) and can be derived under the same assumptions. Importantly, these bounds provide a formal way to establish behavioural differences through an $\alpha$ parameter, given fixed priors. This rests on changes in $\alpha$ that alter the bound (on a continuous scale), inducing different posterior estimates and consequent variations in behaviour. Thus, it looks as if individuals have different priors, and have reached different conclusions. More specifically, $\alpha \to 0^{+}$ optimisation leads to mass-covering variational estimates and increased variability in choice behaviour. Furthermore, $\alpha \to + \infty$ optimisation leads to mass-seeking variational posteriors and greedy preferences. We exemplify this formulation through simulations of the multi-armed bandit task. We note that these $\alpha$ parameterisations may be especially relevant, i.e., shape preferences, when the true posterior is not in the same family of distributions as the assumed (simpler) approximate density, which may be the case in many real-world scenarios. The ensuing departure from vanilla variational inference provides a potentially useful explanation for differences in behavioural preferences of biological (or artificial) agents under the assumption that the brain performs variational Bayesian inference.
Action and Perception as Divergence Minimization
Oct 05, 2020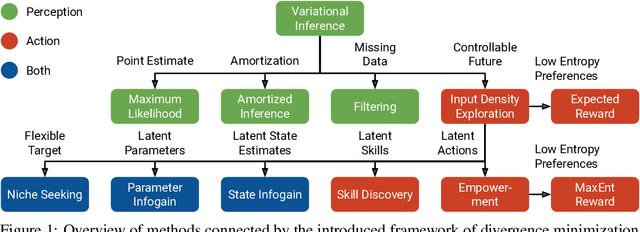

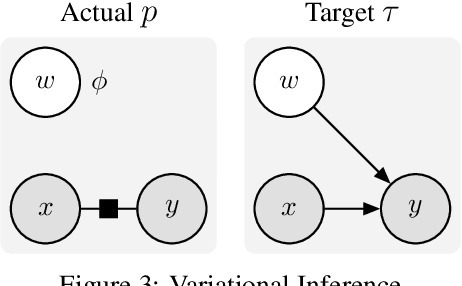
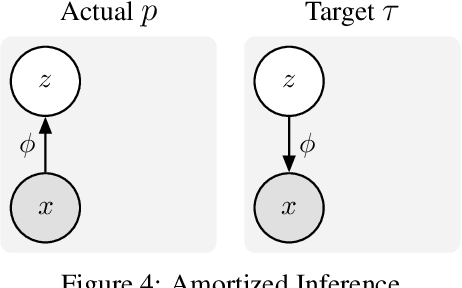
We introduce a unified objective for action and perception of intelligent agents. Extending representation learning and control, we minimize the joint divergence between the combined system of agent and environment and a target distribution. Intuitively, such agents use perception to align their beliefs with the world, and use actions to align the world with their beliefs. Minimizing the joint divergence to an expressive target maximizes the mutual information between the agent's representations and inputs, thus inferring representations that are informative of past inputs and exploring future inputs that are informative of the representations. This lets us explain intrinsic objectives, such as representation learning, information gain, empowerment, and skill discovery from minimal assumptions. Moreover, interpreting the target distribution as a latent variable model suggests powerful world models as a path toward highly adaptive agents that seek large niches in their environments, rendering task rewards optional. The framework provides a common language for comparing a wide range of objectives, advances the understanding of latent variables for decision making, and offers a recipe for designing novel objectives. We recommend deriving future agent objectives the joint divergence to facilitate comparison, to point out the agent's target distribution, and to identify the intrinsic objective terms needed to reach that distribution.
The relationship between dynamic programming and active inference: the discrete, finite-horizon case
Sep 22, 2020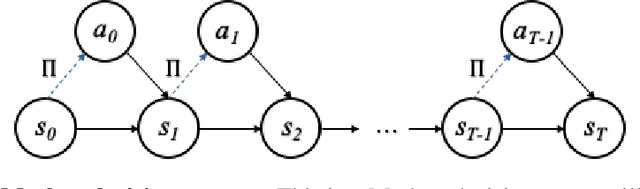
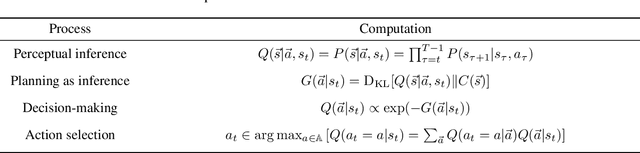
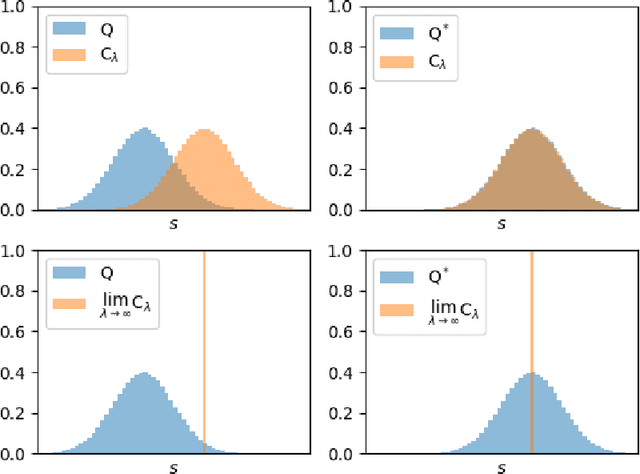

Active inference is a normative framework for generating behaviour based upon the free energy principle, a theory of self-organisation. This framework has been successfully used to solve reinforcement learning and stochastic control problems, yet, the formal relation between active inference and reward maximisation has not been fully explicated. In this paper, we consider the relation between active inference and dynamic programming under the Bellman equation, which underlies many approaches to reinforcement learning and control. We show that, on partially observable Markov decision processes, dynamic programming is a limiting case of active inference. In active inference, agents select actions to minimise expected free energy. In the absence of ambiguity about states, this reduces to matching expected states with a target distribution encoding the agent's preferences. When target states correspond to rewarding states, this maximises expected reward, as in reinforcement learning. When states are ambiguous, active inference agents will choose actions that simultaneously minimise ambiguity. This allows active inference agents to supplement their reward maximising (or exploitative) behaviour with novelty-seeking (or exploratory) behaviour. This clarifies the connection between active inference and reinforcement learning, and how both frameworks may benefit from each other.
Sophisticated Inference
Jun 07, 2020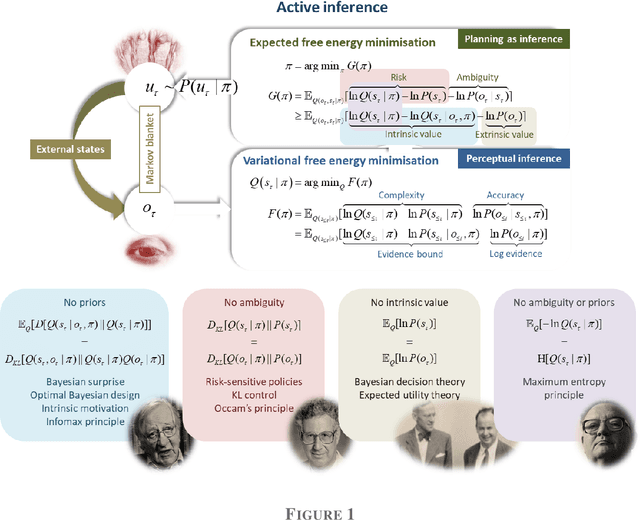
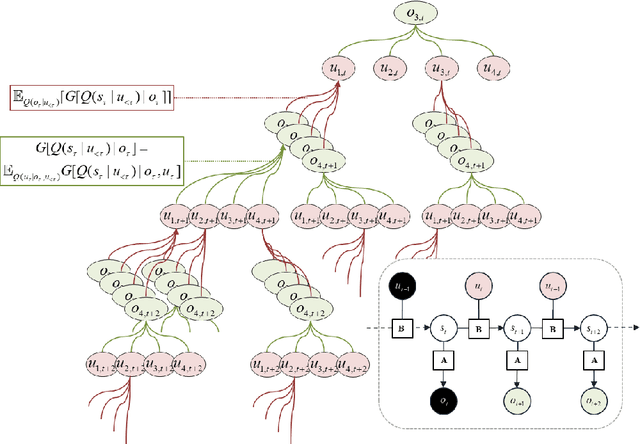
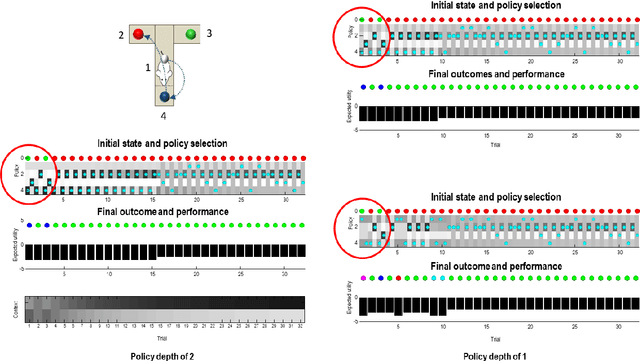
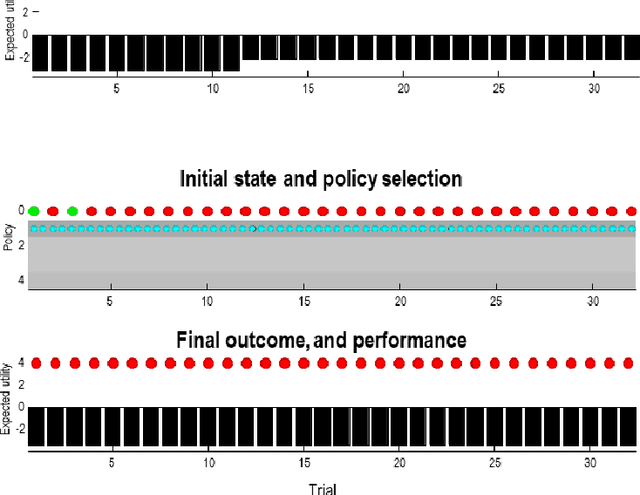
Active inference offers a first principle account of sentient behaviour, from which special and important cases can be derived, e.g., reinforcement learning, active learning, Bayes optimal inference, Bayes optimal design, etc. Active inference resolves the exploitation-exploration dilemma in relation to prior preferences, by placing information gain on the same footing as reward or value. In brief, active inference replaces value functions with functionals of (Bayesian) beliefs, in the form of an expected (variational) free energy. In this paper, we consider a sophisticated kind of active inference, using a recursive form of expected free energy. Sophistication describes the degree to which an agent has beliefs about beliefs. We consider agents with beliefs about the counterfactual consequences of action for states of affairs and beliefs about those latent states. In other words, we move from simply considering beliefs about 'what would happen if I did that' to 'what would I believe about what would happen if I did that'. The recursive form of the free energy functional effectively implements a deep tree search over actions and outcomes in the future. Crucially, this search is over sequences of belief states, as opposed to states per se. We illustrate the competence of this scheme, using numerical simulations of deep decision problems.