 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensory robustness through top-down feedback and neural stochasticity in recurrent vision models
Aug 09, 2025Biological systems leverage top-down feedback for visual processing, yet most artificial vision models succeed in image classification using purely feedforward or recurrent architectures, calling into question the functional significance of descending cortical pathways. Here, we trained convolutional recurrent neural networks (ConvRNN) on image classification in the presence or absence of top-down feedback projections to elucidate the specific computational contributions of those feedback pathways. We found that ConvRNNs with top-down feedback exhibited remarkable speed-accuracy trade-off and robustness to noise perturbations and adversarial attacks, but only when they were trained with stochastic neural variability, simulated by randomly silencing single units via dropout. By performing detailed analyses to identify the reasons for such benefits, we observed that feedback information substantially shaped the representational geometry of the post-integration layer, combining the bottom-up and top-down streams, and this effect was amplified by dropout. Moreover, feedback signals coupled with dropout optimally constrained network activity onto a low-dimensional manifold and encoded object information more efficiently in out-of-distribution regimes, with top-down information stabilizing the representational dynamics at the population level. Together, these findings uncover a dual mechanism for resilient sensory coding. On the one hand, neural stochasticity prevents unit-level co-adaptation albeit at the cost of more chaotic dynamics. On the other hand, top-down feedback harnesses high-level information to stabilize network activity on compact low-dimensional manifolds.
Active Inference and Intentional Behaviour
Dec 16, 2023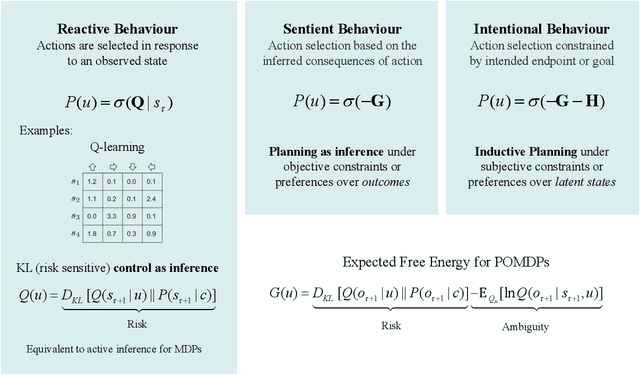
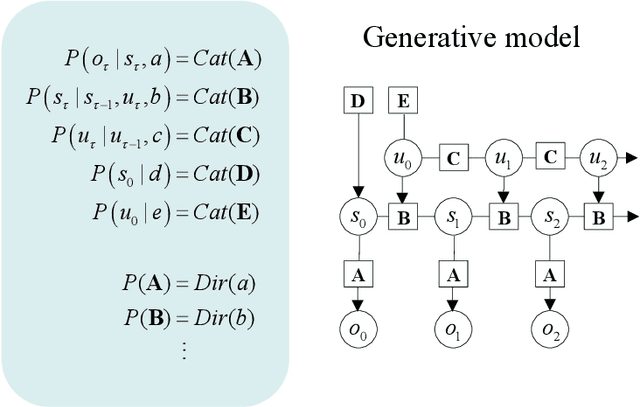

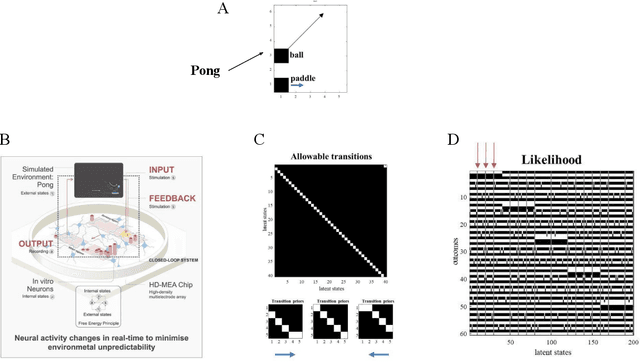
Recent advances in theoretical biology suggest that basal cognition and sentient behaviour are emergent properties of in vitro cell cultures and neuronal networks, respectively. Such neuronal networks spontaneously learn structured behaviours in the absence of reward or reinforcement. In this paper, we characterise this kind of self-organisation through the lens of the free energy principle, i.e., as self-evidencing. We do this by first discussing the definitions of reactive and sentient behaviour in the setting of active inference, which describes the behaviour of agents that model the consequences of their actions. We then introduce a formal account of intentional behaviour, that describes agents as driven by a preferred endpoint or goal in latent state-spaces. We then investigate these forms of (reactive, sentient, and intentional) behaviour using simulations. First, we simulate the aforementioned in vitro experiments, in which neuronal cultures spontaneously learn to play Pong, by implementing nested, free energy minimising processes. The simulations are then used to deconstruct the ensuing predictive behaviour, leading to the distinction between merely reactive, sentient, and intentional behaviour, with the latter formalised in terms of inductive planning. This distinction is further studied using simple machine learning benchmarks (navigation in a grid world and the Tower of Hanoi problem), that show how quickly and efficiently adaptive behaviour emerges under an inductive form of active inference.
Supervised structure learning
Nov 17, 2023



This paper concerns structure learning or discovery of discrete generative models. It focuses on Bayesian model selection and the assimilation of training data or content, with a special emphasis on the order in which data are ingested. A key move - in the ensuing schemes - is to place priors on the selection of models, based upon expected free energy. In this setting, expected free energy reduces to a constrained mutual information, where the constraints inherit from priors over outcomes (i.e., preferred outcomes). The resulting scheme is first used to perform image classification on the MNIST dataset to illustrate the basic idea, and then tested on a more challenging problem of discovering models with dynamics, using a simple sprite-based visual disentanglement paradigm and the Tower of Hanoi (cf., blocks world) problem. In these examples, generative models are constructed autodidactically to recover (i.e., disentangle) the factorial structure of latent states - and their characteristic paths or dynamics.
Bayesian sparsification for deep neural networks with Bayesian model reduction
Sep 21, 2023



Deep learning's immense capabilities are often constrained by the complexity of its models, leading to an increasing demand for effective sparsification techniques. Bayesian sparsification for deep learning emerges as a crucial approach, facilitating the design of models that are both computationally efficient and competitive in terms of performance across various deep learning applications. The state-of-the-art -- in Bayesian sparsification of deep neural networks -- combines structural shrinkage priors on model weights with an approximate inference scheme based on black-box stochastic variational inference. However, model inversion of the full generative model is exceptionally computationally demanding, especially when compared to standard deep learning of point estimates. In this context, we advocate for the use of Bayesian model reduction (BMR) as a more efficient alternative for pruning of model weights. As a generalization of the Savage-Dickey ratio, BMR allows a post-hoc elimination of redundant model weights based on the posterior estimates under a straightforward (non-hierarchical) generative model. Our comparative study highlights the computational efficiency and the pruning rate of the BMR method relative to the established stochastic variational inference (SVI) scheme, when applied to the full hierarchical generative model. We illustrate the potential of BMR to prune model parameters across various deep learning architectures, from classical networks like LeNet to modern frameworks such as Vision Transformers and MLP-Mixers.
Life-inspired Interoceptive Artificial Intelligence for Autonomous and Adaptive Agents
Sep 12, 2023Building autonomous --- i.e., choosing goals based on one's needs -- and adaptive -- i.e., surviving in ever-changing environments -- agents has been a holy grail of artificial intelligence (AI). A living organism is a prime example of such an agent, offering important lessons about adaptive autonomy. Here, we focus on interoception, a process of monitoring one's internal environment to keep it within certain bounds, which underwrites the survival of an organism. To develop AI with interoception, we need to factorize the state variables representing internal environments from external environments and adopt life-inspired mathematical properties of internal environment states. This paper offers a new perspective on how interoception can help build autonomous and adaptive agents by integrating the legacy of cybernetics with recent advances in theories of life, reinforcement learning, and neuroscience.
Predictive Coding and Stochastic Resonance: Towards a Unified Theory of Auditory (Phantom) Perception
Apr 07, 2022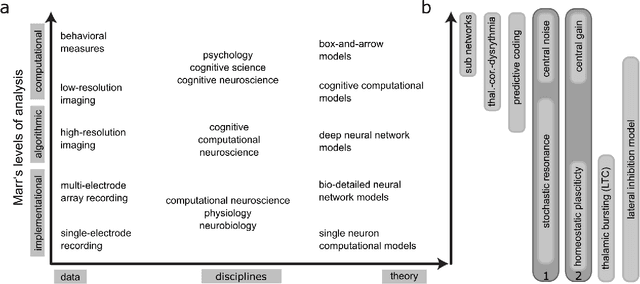
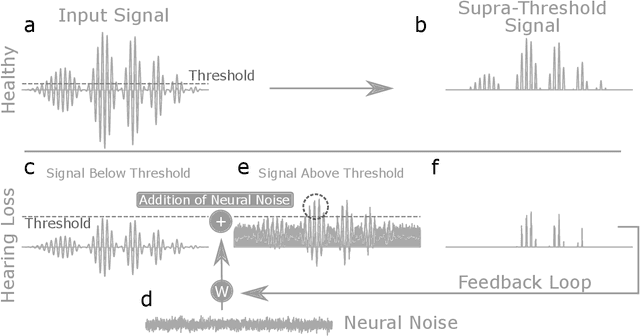
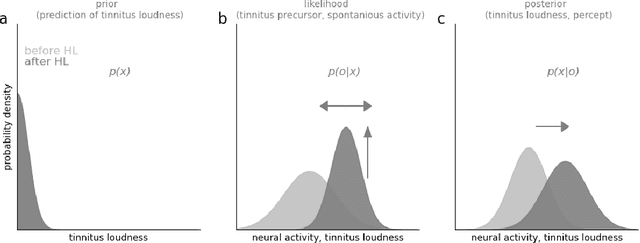

Cognitive computational neuroscience (CCN) suggests that to gain a mechanistic understanding of brain function, hypothesis driven experiments should be accompanied by biologically plausible computational models. This novel research paradigm offers a way from alchemy to chemistry, in auditory neuroscience. With a special focus on tinnitus - as the prime example of auditory phantom perception - we review recent work at the intersection of artificial intelligence, psychology, and neuroscience, foregrounding the idea that experiments will yield mechanistic insight only when employed to test formal or computational models. This view challenges the popular notion that tinnitus research is primarily data limited, and that producing large, multi-modal, and complex data-sets, analyzed with advanced data analysis algorithms, will lead to fundamental insights into how tinnitus emerges. We conclude that two fundamental processing principles - being ubiquitous in the brain - best fit to a vast number of experimental results and therefore provide the most explanatory power: predictive coding as a top-down, and stochastic resonance as a complementary bottom-up mechanism. Furthermore, we argue that even though contemporary artificial intelligence and machine learning approaches largely lack biological plausibility, the models to be constructed will have to draw on concepts from these fields; since they provide a formal account of the requisite computations that underlie brain function. Nevertheless, biological fidelity will have to be addressed, allowing for testing possible treatment strategies in silico, before application in animal or patient studies. This iteration of computational and empirical studies may help to open the "black boxes" of both machine learning and the human brain.
Trust as Extended Control: Active Inference and User Feedback During Human-Robot Collaboration
Apr 22, 2021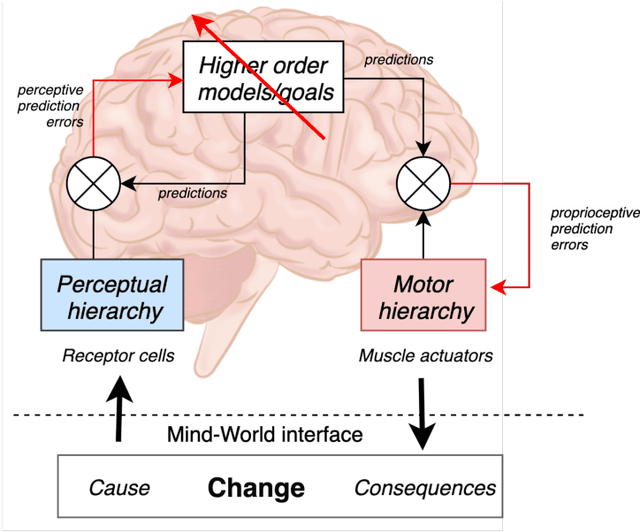

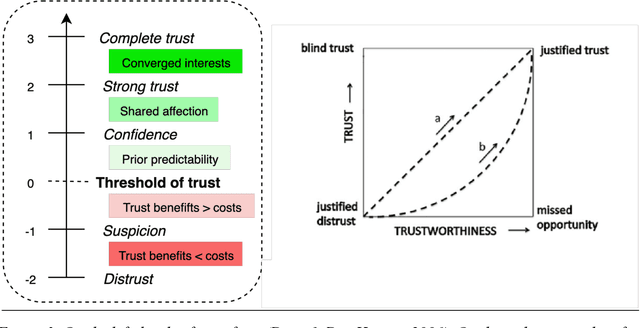

To interact seamlessly with robots, users must infer the causes of a robot's behavior and be confident about that inference. Hence, trust is a necessary condition for human-robot collaboration (HRC). Despite its crucial role, it is largely unknown how trust emerges, develops, and supports human interactions with nonhuman artefacts. Here, we review the literature on trust, human-robot interaction, human-robot collaboration, and human interaction at large. Early models of trust suggest that trust entails a trade-off between benevolence and competence, while studies of human-to-human interaction emphasize the role of shared behavior and mutual knowledge in the gradual building of trust. We then introduce a model of trust as an agent's best explanation for reliable sensory exchange with an extended motor plant or partner. This model is based on the cognitive neuroscience of active inference and suggests that, in the context of HRC, trust can be cast in terms of virtual control over an artificial agent. In this setting, interactive feedback becomes a necessary component of the trustor's perception-action cycle. The resulting model has important implications for understanding human-robot interaction and collaboration, as it allows the traditional determinants of human trust to be defined in terms of active inference, information exchange and empowerment. Furthermore, this model suggests that boredom and surprise may be used as markers for under and over-reliance on the system. Finally, we examine the role of shared behavior in the genesis of trust, especially in the context of dyadic collaboration, suggesting important consequences for the acceptability and design of human-robot collaborative systems.
Demystifying active inference
Sep 24, 2019
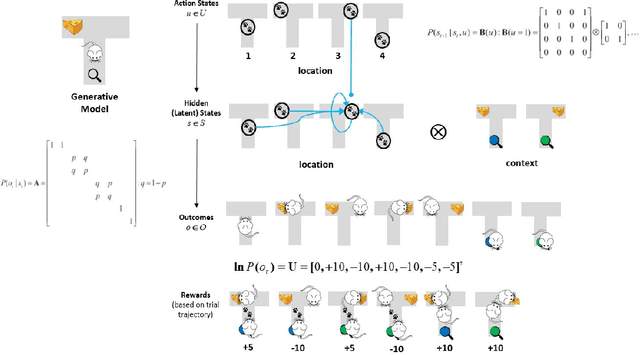
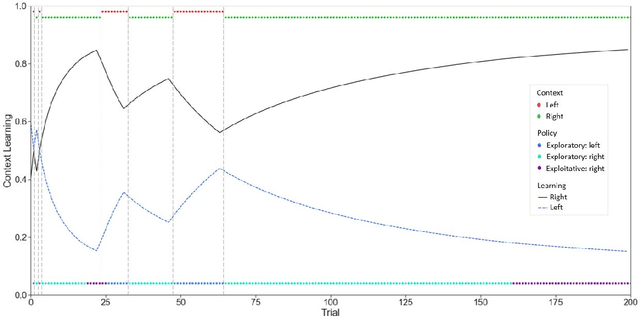
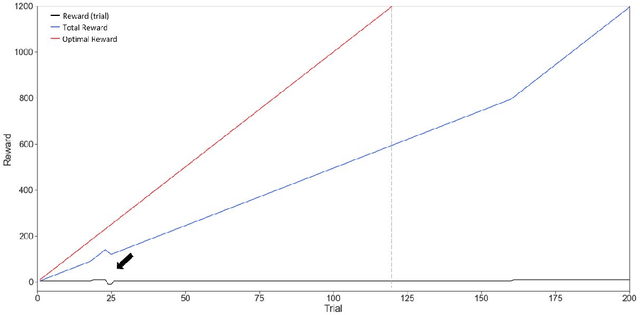
Active inference is a first (Bayesian) principles account of how autonomous agents might operate in dynamic, non-stationary environments. The optimization of congruent formulations of the free energy functional (variational and expected), in active inference, enables agents to make inferences about the environment and select optimal behaviors. The agent achieves this by evaluating (sensory) evidence in relation to its internal generative model that entails beliefs about future (hidden) states and sequence of actions that it can choose. In contrast to analogous frameworks $-$ by operating in a pure belief-based setting (free energy functional of beliefs about states) $-$ active inference agents can carry out epistemic exploration and naturally account for uncertainty about their environment. Through this review, we disambiguate these properties, by providing a condensed overview of the theory underpinning active inference. A T-maze simulation is used to demonstrate how these behaviors emerge naturally, as the agent makes inferences about the observed outcomes and optimizes its generative model (via belief updating). Additionally, the discrete state-space and time formulation presented provides an accessible guide on how to derive the (variational and expected) free energy equations and belief updating rules. We conclude by noting that this formalism can be applied in other engineering applications; e.g., robotic arm movement, playing Atari games, etc., if appropriate underlying probability distributions (i.e. generative model) can be formulated.
How Robust are Deep Neural Networks?
Apr 30, 2018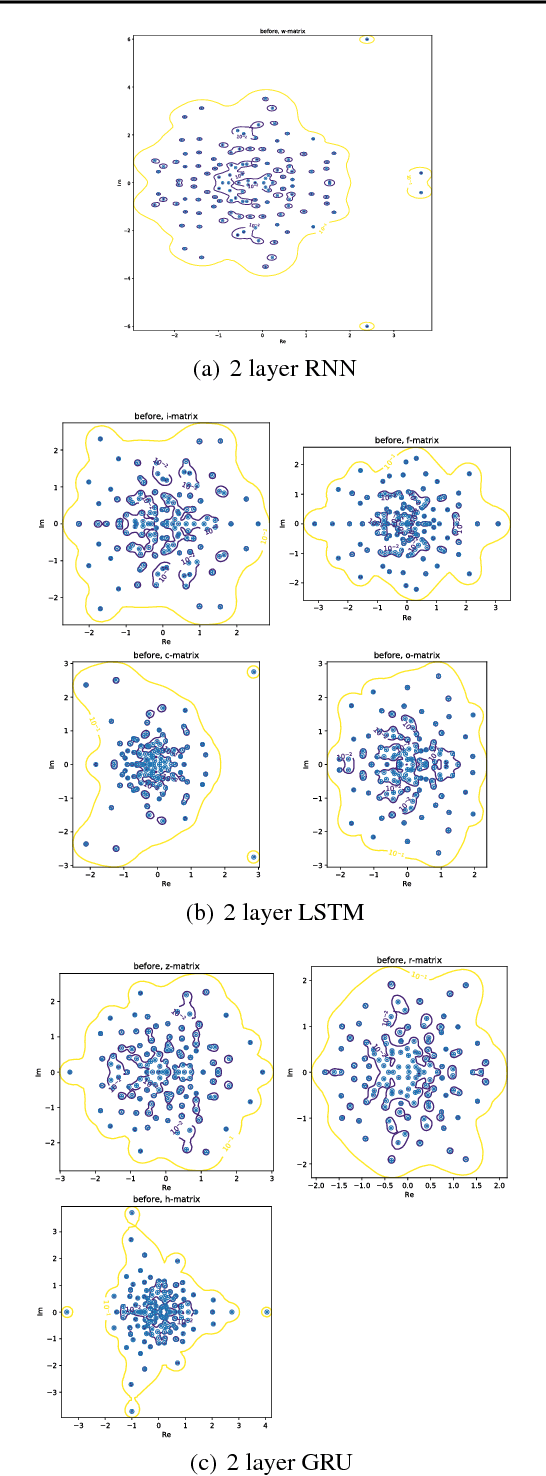

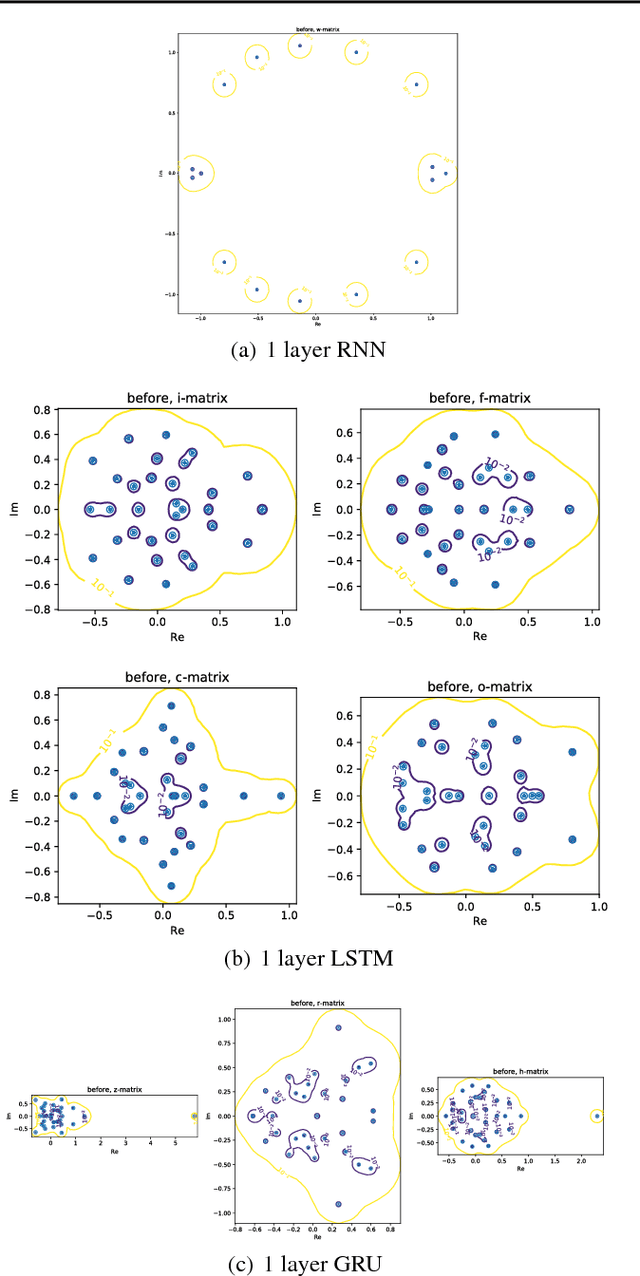
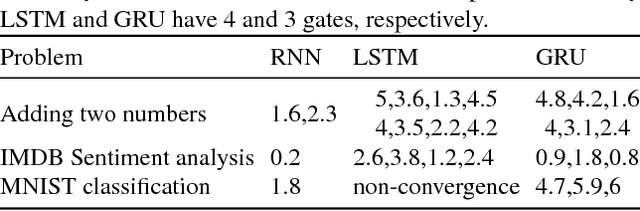
Convolutional and Recurrent, deep neural networks have been successful in machine learning systems for computer vision, reinforcement learning, and other allied fields. However, the robustness of such neural networks is seldom apprised, especially after high classification accuracy has been attained. In this paper, we evaluate the robustness of three recurrent neural networks to tiny perturbations, on three widely used datasets, to argue that high accuracy does not always mean a stable and a robust (to bounded perturbations, adversarial attacks, etc.) system. Especially, normalizing the spectrum of the discrete recurrent network to bound the spectrum (using power method, Rayleigh quotient, etc.) on a unit disk produces stable, albeit highly non-robust neural networks. Furthermore, using the $\epsilon$-pseudo-spectrum, we show that training of recurrent networks, say using gradient-based methods, often result in non-normal matrices that may or may not be diagonalizable. Therefore, the open problem lies in constructing methods that optimize not only for accuracy but also for the stability and the robustness of the underlying neural network, a criterion that is distinct from the other.