 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergent Representations of Linguistic Constructions in Human and Artificial Neural Systems
Mar 31, 2026Understanding how the brain processes linguistic constructions is a central challenge in cognitive neuroscience and linguistics. Recent computational studies show that artificial neural language models spontaneously develop differentiated representations of Argument Structure Constructions (ASCs), generating predictions about when and how construction-level information emerges during processing. The present study tests these predictions in human neural activity using electroencephalography (EEG). Ten native English speakers listened to 200 synthetically generated sentences across four construction types (transitive, ditransitive, caused-motion, resultative) while neural responses were recorded. Analyses using time-frequency methods, feature extraction, and machine learning classification revealed construction-specific neural signatures emerging primarily at sentence-final positions, where argument structure becomes fully disambiguated, and most prominently in the alpha band. Pairwise classification showed reliable differentiation, especially between ditransitive and resultative constructions, while other pairs overlapped. Crucially, the temporal emergence and similarity structure of these effects mirror patterns in recurrent and transformer-based language models, where constructional representations arise during integrative processing stages. These findings support the view that linguistic constructions are neurally encoded as distinct form-meaning mappings, in line with Construction Grammar, and suggest convergence between biological and artificial systems on similar representational solutions. More broadly, this convergence is consistent with the idea that learning systems discover stable regions within an underlying representational landscape - recently termed a Platonic representational space - that constrains the emergence of efficient linguistic abstractions.
Probing Internal Representations of Multi-Word Verbs in Large Language Models
Feb 07, 2025This study investigates the internal representations of verb-particle combinations, called multi-word verbs, within transformer-based large language models (LLMs), specifically examining how these models capture lexical and syntactic properties at different neural network layers. Using the BERT architecture, we analyze the representations of its layers for two different verb-particle constructions: phrasal verbs like 'give up' and prepositional verbs like 'look at'. Our methodology includes training probing classifiers on the internal representations to classify these categories at both word and sentence levels. The results indicate that the model's middle layers achieve the highest classification accuracies. To further analyze the nature of these distinctions, we conduct a data separability test using the Generalized Discrimination Value (GDV). While GDV results show weak linear separability between the two verb types, probing classifiers still achieve high accuracy, suggesting that representations of these linguistic categories may be non-linearly separable. This aligns with previous research indicating that linguistic distinctions in neural networks are not always encoded in a linearly separable manner. These findings computationally support usage-based claims on the representation of verb-particle constructions and highlight the complex interaction between neural network architectures and linguistic structures.
Author-Specific Linguistic Patterns Unveiled: A Deep Learning Study on Word Class Distributions
Jan 17, 2025Deep learning methods have been increasingly applied to computational linguistics to uncover patterns in text data. This study investigates author-specific word class distributions using part-of-speech (POS) tagging and bigram analysis. By leveraging deep neural networks, we classify literary authors based on POS tag vectors and bigram frequency matrices derived from their works. We employ fully connected and convolutional neural network architectures to explore the efficacy of unigram and bigram-based representations. Our results demonstrate that while unigram features achieve moderate classification accuracy, bigram-based models significantly improve performance, suggesting that sequential word class patterns are more distinctive of authorial style. Multi-dimensional scaling (MDS) visualizations reveal meaningful clustering of authors' works, supporting the hypothesis that stylistic nuances can be captured through computational methods. These findings highlight the potential of deep learning and linguistic feature analysis for author profiling and literary studies.
Exploring Narrative Clustering in Large Language Models: A Layerwise Analysis of BERT
Jan 14, 2025



This study investigates the internal mechanisms of BERT, a transformer-based large language model, with a focus on its ability to cluster narrative content and authorial style across its layers. Using a dataset of narratives developed via GPT-4, featuring diverse semantic content and stylistic variations, we analyze BERT's layerwise activations to uncover patterns of localized neural processing. Through dimensionality reduction techniques such as Principal Component Analysis (PCA) and Multidimensional Scaling (MDS), we reveal that BERT exhibits strong clustering based on narrative content in its later layers, with progressively compact and distinct clusters. While strong stylistic clustering might occur when narratives are rephrased into different text types (e.g., fables, sci-fi, kids' stories), minimal clustering is observed for authorial style specific to individual writers. These findings highlight BERT's prioritization of semantic content over stylistic features, offering insights into its representational capabilities and processing hierarchy. This study contributes to understanding how transformer models like BERT encode linguistic information, paving the way for future interdisciplinary research in artificial intelligence and cognitive neuroscience.
Refusal Behavior in Large Language Models: A Nonlinear Perspective
Jan 14, 2025



Refusal behavior in large language models (LLMs) enables them to decline responding to harmful, unethical, or inappropriate prompts, ensuring alignment with ethical standards. This paper investigates refusal behavior across six LLMs from three architectural families. We challenge the assumption of refusal as a linear phenomenon by employing dimensionality reduction techniques, including PCA, t-SNE, and UMAP. Our results reveal that refusal mechanisms exhibit nonlinear, multidimensional characteristics that vary by model architecture and layer. These findings highlight the need for nonlinear interpretability to improve alignment research and inform safer AI deployment strategies.
Analysis and Visualization of Linguistic Structures in Large Language Models: Neural Representations of Verb-Particle Constructions in BERT
Dec 19, 2024
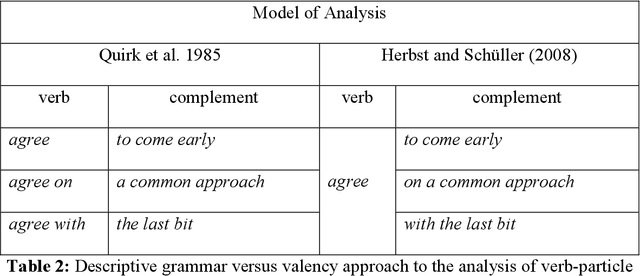

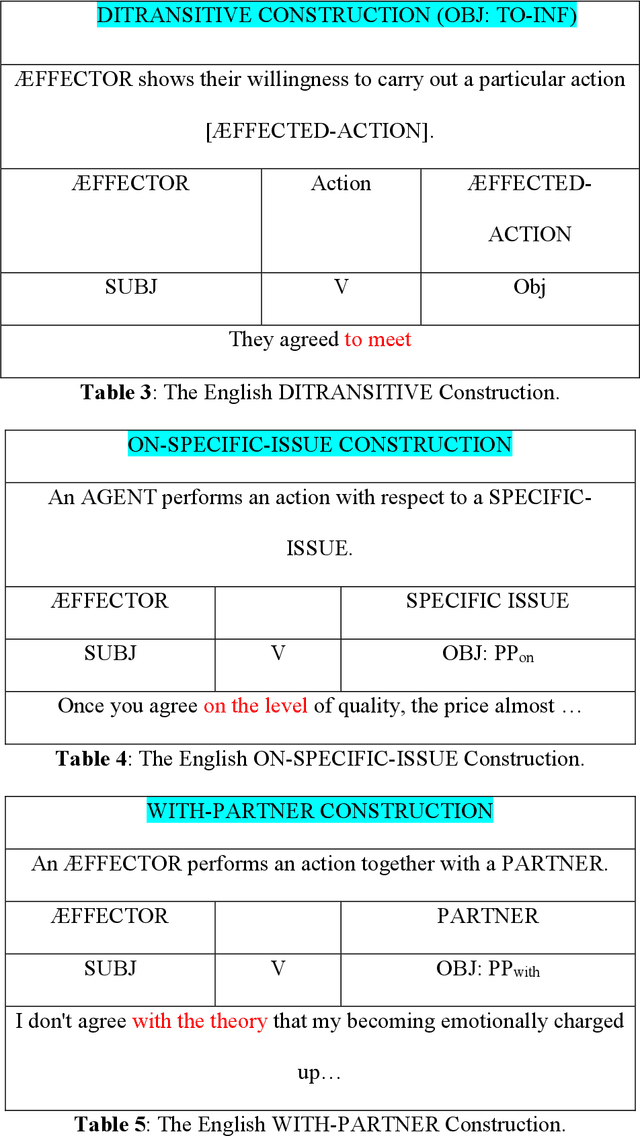
This study investigates the internal representations of verb-particle combinations within transformer-based large language models (LLMs), specifically examining how these models capture lexical and syntactic nuances at different neural network layers. Employing the BERT architecture, we analyse the representational efficacy of its layers for various verb-particle constructions such as 'agree on', 'come back', and 'give up'. Our methodology includes a detailed dataset preparation from the British National Corpus, followed by extensive model training and output analysis through techniques like multi-dimensional scaling (MDS) and generalized discrimination value (GDV) calculations. Results show that BERT's middle layers most effectively capture syntactic structures, with significant variability in representational accuracy across different verb categories. These findings challenge the conventional uniformity assumed in neural network processing of linguistic elements and suggest a complex interplay between network architecture and linguistic representation. Our research contributes to a better understanding of how deep learning models comprehend and process language, offering insights into the potential and limitations of current neural approaches to linguistic analysis. This study not only advances our knowledge in computational linguistics but also prompts further research into optimizing neural architectures for enhanced linguistic precision.
Probing for Consciousness in Machines
Nov 25, 2024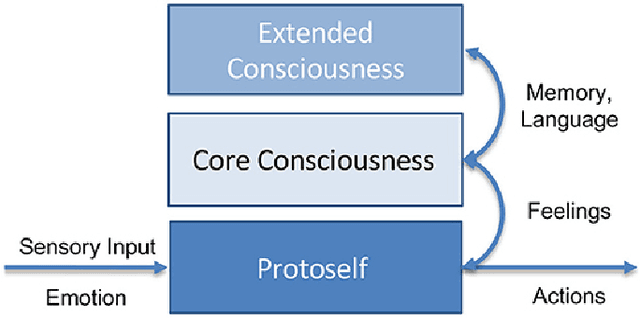
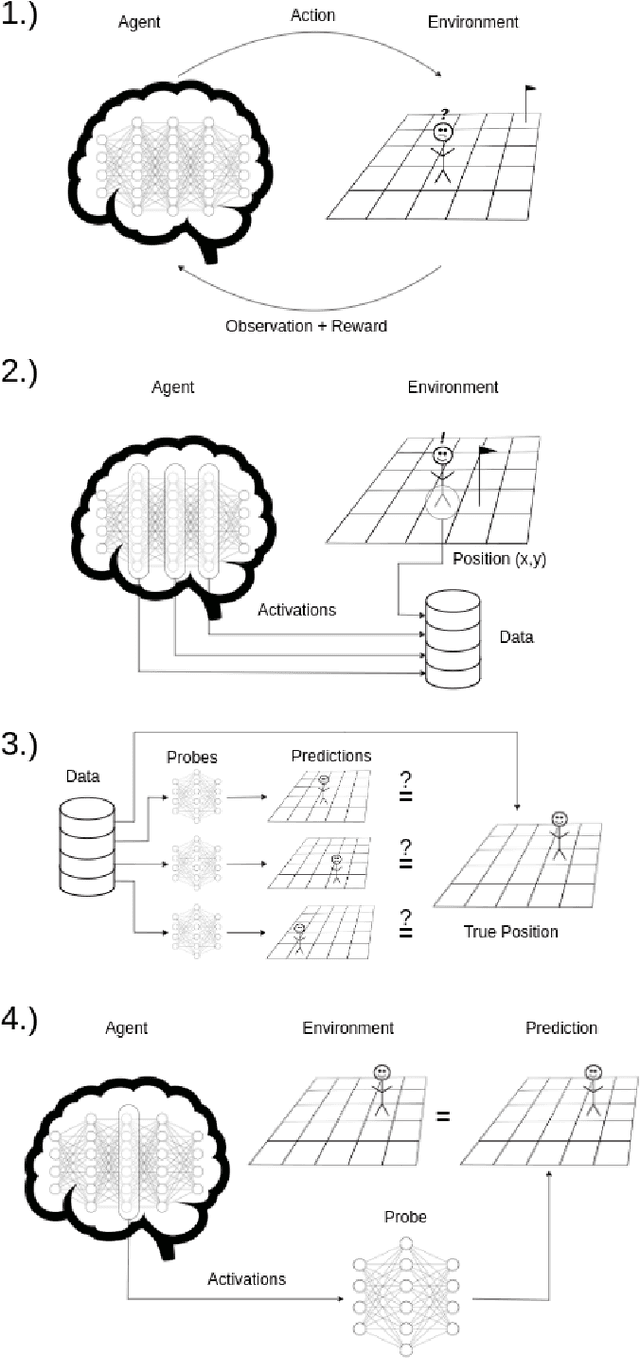

This study explores the potential for artificial agents to develop core consciousness, as proposed by Antonio Damasio's theory of consciousness. According to Damasio, the emergence of core consciousness relies on the integration of a self model, informed by representations of emotions and feelings, and a world model. We hypothesize that an artificial agent, trained via reinforcement learning (RL) in a virtual environment, can develop preliminary forms of these models as a byproduct of its primary task. The agent's main objective is to learn to play a video game and explore the environment. To evaluate the emergence of world and self models, we employ probes-feedforward classifiers that use the activations of the trained agent's neural networks to predict the spatial positions of the agent itself. Our results demonstrate that the agent can form rudimentary world and self models, suggesting a pathway toward developing machine consciousness. This research provides foundational insights into the capabilities of artificial agents in mirroring aspects of human consciousness, with implications for future advancements in artificial intelligence.
Nonlinear Neural Dynamics and Classification Accuracy in Reservoir Computing
Nov 15, 2024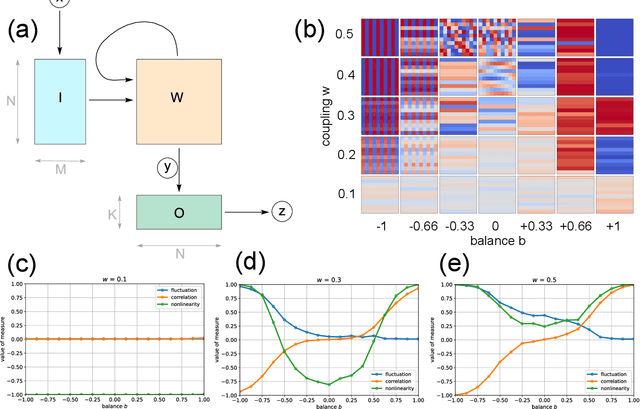

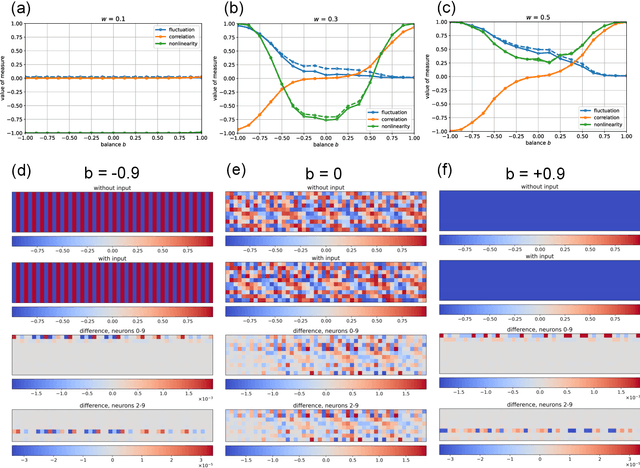
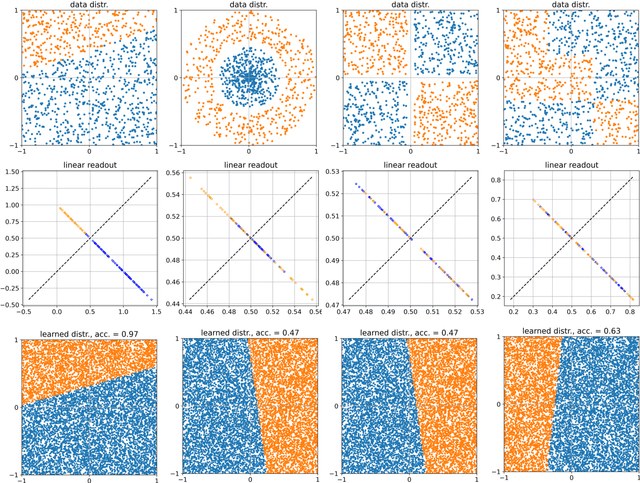
Reservoir computing - information processing based on untrained recurrent neural networks with random connections - is expected to depend on the nonlinear properties of the neurons and the resulting oscillatory, chaotic, or fixpoint dynamics of the network. However, the required degree of nonlinearity and the range of suitable dynamical regimes for a given task are not fully understood. To clarify these questions, we study the accuracy of a reservoir computer in artificial classification tasks of varying complexity, while tuning the neuron's degree of nonlinearity and the reservoir's dynamical regime. We find that, even for activation functions with extremely reduced nonlinearity, weak recurrent interactions and small input signals, the reservoir is able to compute useful representations, detectable only in higher order principal components, that render complex classificiation tasks linearly separable for the readout layer. When increasing the recurrent coupling, the reservoir develops spontaneous dynamical behavior. Nevertheless, the input-related computations can 'ride on top' of oscillatory or fixpoint attractors without much loss of accuracy, whereas chaotic dynamics reduces task performance more drastically. By tuning the system through the full range of dynamical phases, we find that the accuracy peaks both at the oscillatory/chaotic and at the chaotic/fixpoint phase boundaries, thus supporting the 'edge of chaos' hypothesis. Our results, in particular the robust weakly nonlinear operating regime, may offer new perspectives both for technical and biological neural networks with random connectivity.
Analysis of Argument Structure Constructions in a Deep Recurrent Language Model
Aug 06, 2024Understanding how language and linguistic constructions are processed in the brain is a fundamental question in cognitive computational neuroscience. In this study, we explore the representation and processing of Argument Structure Constructions (ASCs) in a recurrent neural language model. We trained a Long Short-Term Memory (LSTM) network on a custom-made dataset consisting of 2000 sentences, generated using GPT-4, representing four distinct ASCs: transitive, ditransitive, caused-motion, and resultative constructions. We analyzed the internal activations of the LSTM model's hidden layers using Multidimensional Scaling (MDS) and t-Distributed Stochastic Neighbor Embedding (t-SNE) to visualize the sentence representations. The Generalized Discrimination Value (GDV) was calculated to quantify the degree of clustering within these representations. Our results show that sentence representations form distinct clusters corresponding to the four ASCs across all hidden layers, with the most pronounced clustering observed in the last hidden layer before the output layer. This indicates that even a relatively simple, brain-constrained recurrent neural network can effectively differentiate between various construction types. These findings are consistent with previous studies demonstrating the emergence of word class and syntax rule representations in recurrent language models trained on next word prediction tasks. In future work, we aim to validate these results using larger language models and compare them with neuroimaging data obtained during continuous speech perception. This study highlights the potential of recurrent neural language models to mirror linguistic processing in the human brain, providing valuable insights into the computational and neural mechanisms underlying language understanding.
Data-driven Modeling in Metrology -- A Short Introduction, Current Developments and Future Perspectives
Jun 24, 2024Mathematical models are vital to the field of metrology, playing a key role in the derivation of measurement results and the calculation of uncertainties from measurement data, informed by an understanding of the measurement process. These models generally represent the correlation between the quantity being measured and all other pertinent quantities. Such relationships are used to construct measurement systems that can interpret measurement data to generate conclusions and predictions about the measurement system itself. Classic models are typically analytical, built on fundamental physical principles. However, the rise of digital technology, expansive sensor networks, and high-performance computing hardware have led to a growing shift towards data-driven methodologies. This trend is especially prominent when dealing with large, intricate networked sensor systems in situations where there is limited expert understanding of the frequently changing real-world contexts. Here, we demonstrate the variety of opportunities that data-driven modeling presents, and how they have been already implemented in various real-world applications.