 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Narrative Processing in Large Language Models (LLMs): Using GPT4 to test BERT
May 03, 2024The ability to transmit and receive complex information via language is unique to humans and is the basis of traditions, culture and versatile social interactions. Through the disruptive introduction of transformer based large language models (LLMs) humans are not the only entity to "understand" and produce language any more. In the present study, we have performed the first steps to use LLMs as a model to understand fundamental mechanisms of language processing in neural networks, in order to make predictions and generate hypotheses on how the human brain does language processing. Thus, we have used ChatGPT to generate seven different stylistic variations of ten different narratives (Aesop's fables). We used these stories as input for the open source LLM BERT and have analyzed the activation patterns of the hidden units of BERT using multi-dimensional scaling and cluster analysis. We found that the activation vectors of the hidden units cluster according to stylistic variations in earlier layers of BERT (1) than narrative content (4-5). Despite the fact that BERT consists of 12 identical building blocks that are stacked and trained on large text corpora, the different layers perform different tasks. This is a very useful model of the human brain, where self-similar structures, i.e. different areas of the cerebral cortex, can have different functions and are therefore well suited to processing language in a very efficient way. The proposed approach has the potential to open the black box of LLMs on the one hand, and might be a further step to unravel the neural processes underlying human language processing and cognition in general.
Leveraging Speech for Gesture Detection in Multimodal Communication
Apr 23, 2024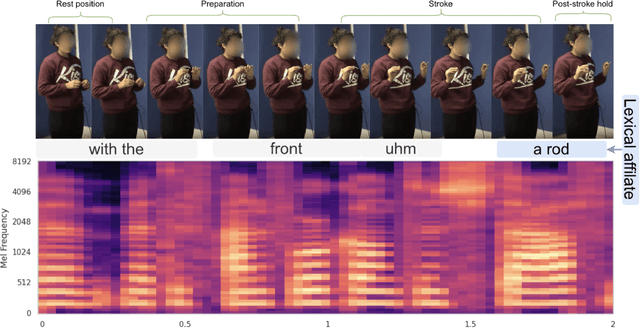
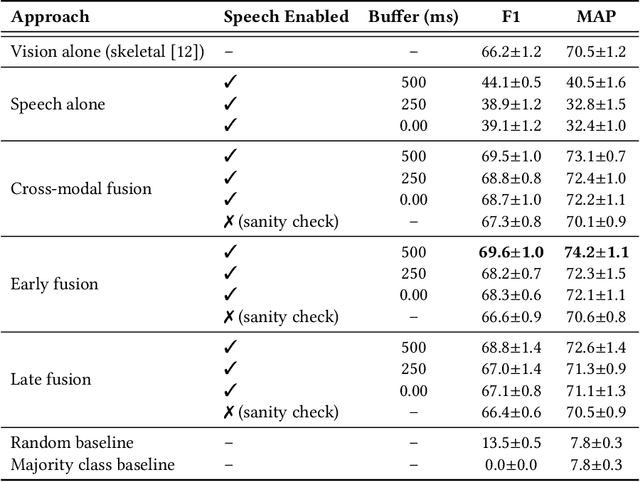

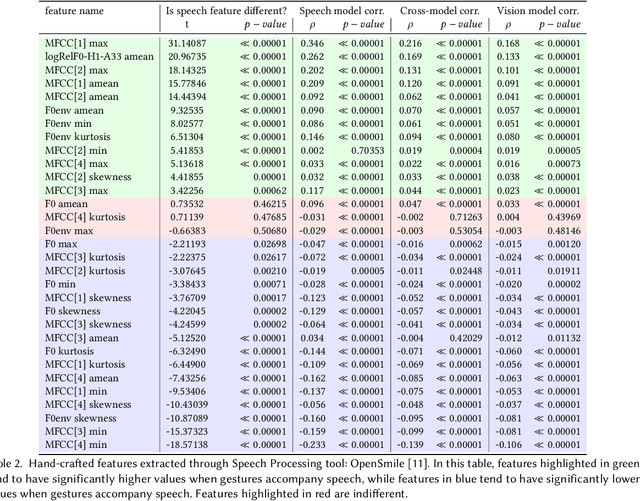
Gestures are inherent to human interaction and often complement speech in face-to-face communication, forming a multimodal communication system. An important task in gesture analysis is detecting a gesture's beginning and end. Research on automatic gesture detection has primarily focused on visual and kinematic information to detect a limited set of isolated or silent gestures with low variability, neglecting the integration of speech and vision signals to detect gestures that co-occur with speech. This work addresses this gap by focusing on co-speech gesture detection, emphasising the synchrony between speech and co-speech hand gestures. We address three main challenges: the variability of gesture forms, the temporal misalignment between gesture and speech onsets, and differences in sampling rate between modalities. We investigate extended speech time windows and employ separate backbone models for each modality to address the temporal misalignment and sampling rate differences. We utilize Transformer encoders in cross-modal and early fusion techniques to effectively align and integrate speech and skeletal sequences. The study results show that combining visual and speech information significantly enhances gesture detection performance. Our findings indicate that expanding the speech buffer beyond visual time segments improves performance and that multimodal integration using cross-modal and early fusion techniques outperforms baseline methods using unimodal and late fusion methods. Additionally, we find a correlation between the models' gesture prediction confidence and low-level speech frequency features potentially associated with gestures. Overall, the study provides a better understanding and detection methods for co-speech gestures, facilitating the analysis of multimodal communication.
Co-Speech Gesture Detection through Multi-phase Sequence Labeling
Aug 21, 2023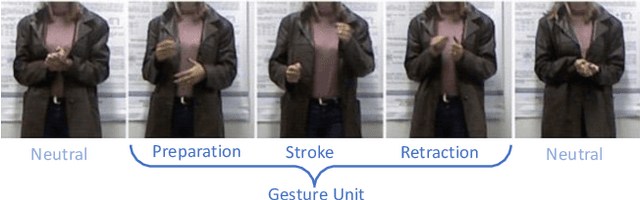
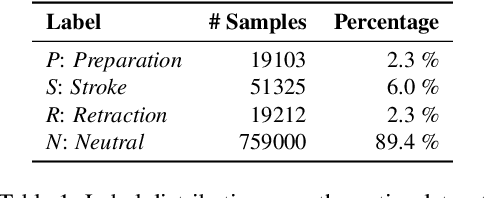

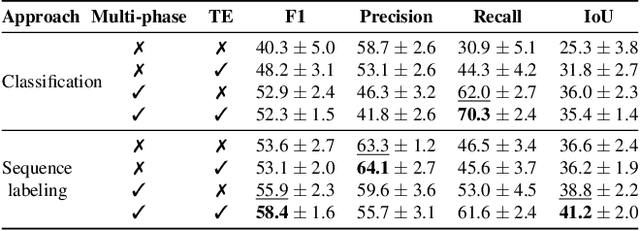
Gestures are integral components of face-to-face communication. They unfold over time, often following predictable movement phases of preparation, stroke, and retraction. Yet, the prevalent approach to automatic gesture detection treats the problem as binary classification, classifying a segment as either containing a gesture or not, thus failing to capture its inherently sequential and contextual nature. To address this, we introduce a novel framework that reframes the task as a multi-phase sequence labeling problem rather than binary classification. Our model processes sequences of skeletal movements over time windows, uses Transformer encoders to learn contextual embeddings, and leverages Conditional Random Fields to perform sequence labeling. We evaluate our proposal on a large dataset of diverse co-speech gestures in task-oriented face-to-face dialogues. The results consistently demonstrate that our method significantly outperforms strong baseline models in detecting gesture strokes. Furthermore, applying Transformer encoders to learn contextual embeddings from movement sequences substantially improves gesture unit detection. These results highlight our framework's capacity to capture the fine-grained dynamics of co-speech gesture phases, paving the way for more nuanced and accurate gesture detection and analysis.
Making sense of spoken plurals
Jul 05, 2022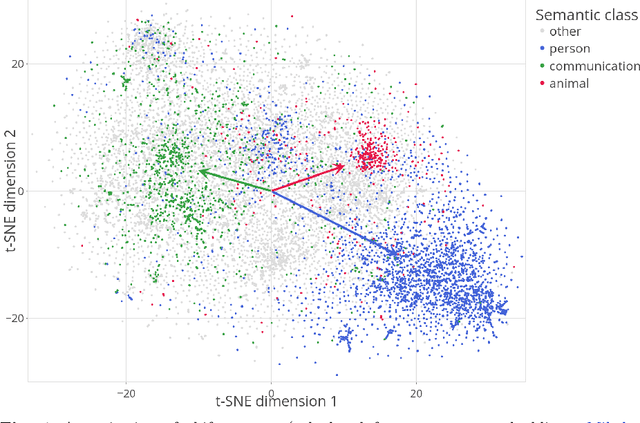
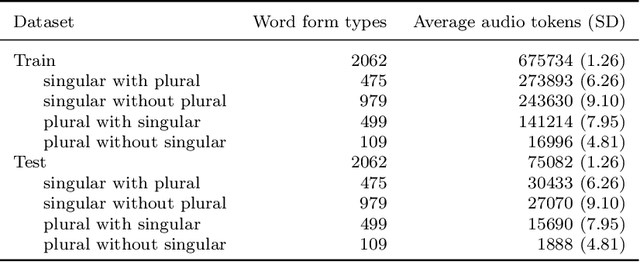

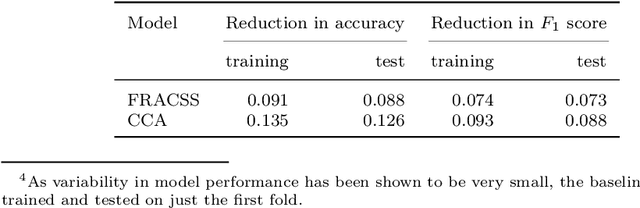
Distributional semantics offers new ways to study the semantics of morphology. This study focuses on the semantics of noun singulars and their plural inflectional variants in English. Our goal is to compare two models for the conceptualization of plurality. One model (FRACSS) proposes that all singular-plural pairs should be taken into account when predicting plural semantics from singular semantics. The other model (CCA) argues that conceptualization for plurality depends primarily on the semantic class of the base word. We compare the two models on the basis of how well the speech signal of plural tokens in a large corpus of spoken American English aligns with the semantic vectors predicted by the two models. Two measures are employed: the performance of a form-to-meaning mapping and the correlations between form distances and meaning distances. Results converge on a superior alignment for CCA. Our results suggest that usage-based approaches to pluralization in which a given word's own semantic neighborhood is given priority outperform theories according to which pluralization is conceptualized as a process building on high-level abstraction. We see that what has often been conceived of as a highly abstract concept, [+plural], is better captured via a family of mid-level partial generalizations.
Semantic properties of English nominal pluralization: Insights from word embeddings
Mar 29, 2022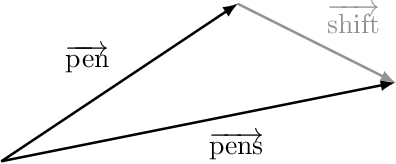
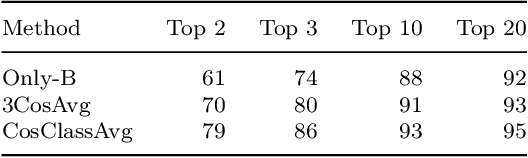
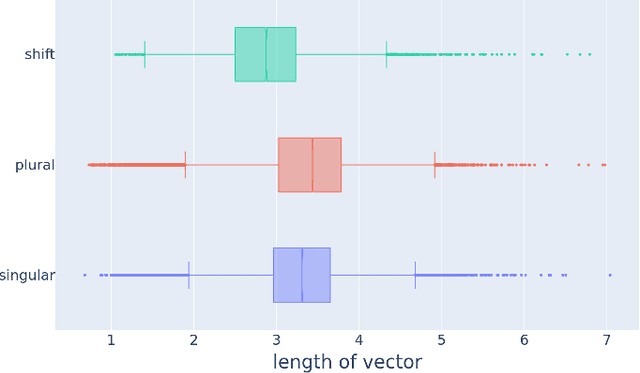
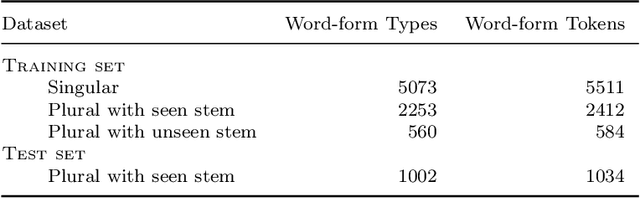
Semantic differentiation of nominal pluralization is grammaticalized in many languages. For example, plural markers may only be relevant for human nouns. English does not appear to make such distinctions. Using distributional semantics, we show that English nominal pluralization exhibits semantic clusters. For instance, pluralization of fruit words is more similar to one another and less similar to pluralization of other semantic classes. Therefore, reduction of the meaning shift in plural formation to the addition of an abstract plural meaning is too simplistic. A semantically informed method, called CosClassAvg, is introduced that outperforms pluralization methods in distributional semantics which assume plural formation amounts to the addition of a fixed plural vector. In comparison with our approach, a method from compositional distributional semantics, called FRACSS, predicted plural vectors that were more similar to the corpus-extracted plural vectors in terms of direction but not vector length. A modeling study reveals that the observed difference between the two predicted semantic spaces by CosClassAvg and FRACSS carries over to how well a computational model of the listener can understand previously unencountered plural forms. Mappings from word forms, represented with triphone vectors, to predicted semantic vectors are more productive when CosClassAvg-generated semantic vectors are employed as gold standard vectors instead of FRACSS-generated vectors.