 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking sense of spoken plurals
Jul 05, 2022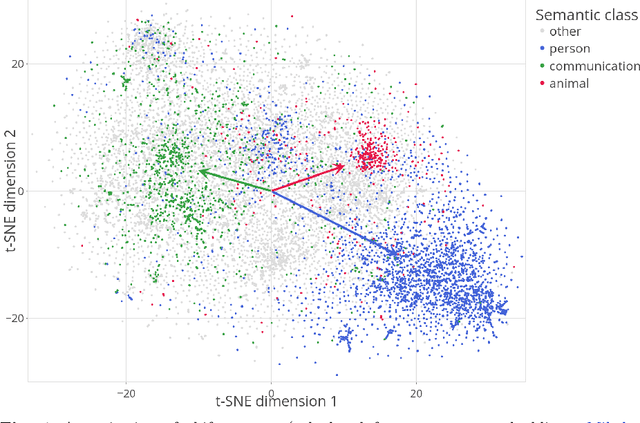
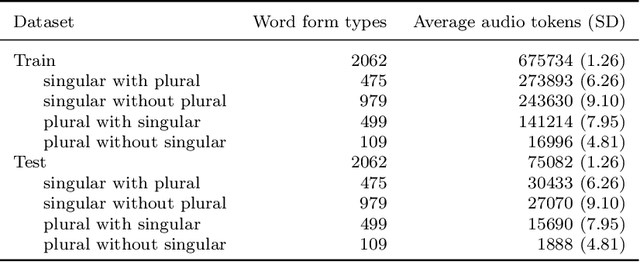

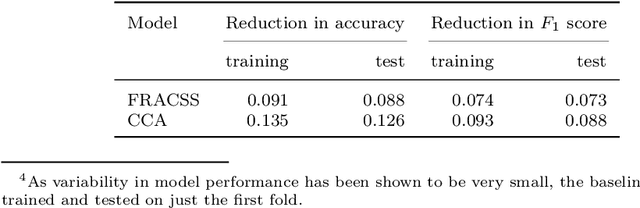
Distributional semantics offers new ways to study the semantics of morphology. This study focuses on the semantics of noun singulars and their plural inflectional variants in English. Our goal is to compare two models for the conceptualization of plurality. One model (FRACSS) proposes that all singular-plural pairs should be taken into account when predicting plural semantics from singular semantics. The other model (CCA) argues that conceptualization for plurality depends primarily on the semantic class of the base word. We compare the two models on the basis of how well the speech signal of plural tokens in a large corpus of spoken American English aligns with the semantic vectors predicted by the two models. Two measures are employed: the performance of a form-to-meaning mapping and the correlations between form distances and meaning distances. Results converge on a superior alignment for CCA. Our results suggest that usage-based approaches to pluralization in which a given word's own semantic neighborhood is given priority outperform theories according to which pluralization is conceptualized as a process building on high-level abstraction. We see that what has often been conceived of as a highly abstract concept, [+plural], is better captured via a family of mid-level partial generalizations.
Visual grounding of abstract and concrete words: A response to Günther et al. (2020)
Jun 30, 2022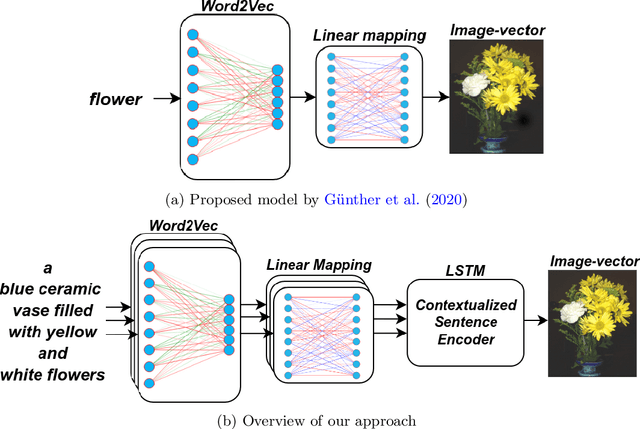

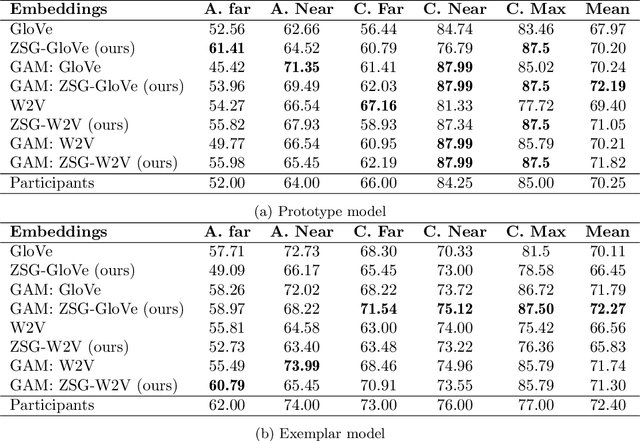
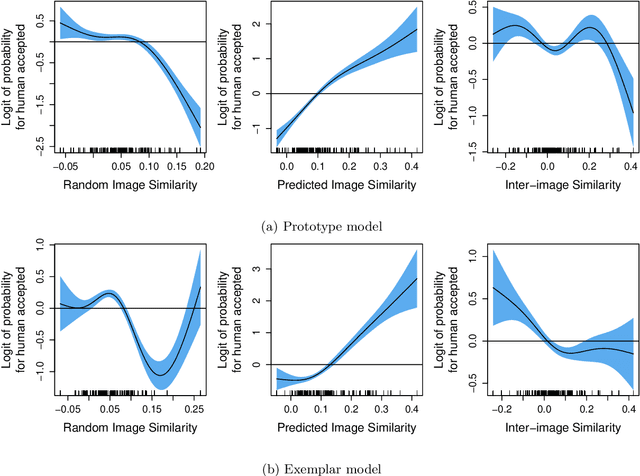
Current computational models capturing words' meaning mostly rely on textual corpora. While these approaches have been successful over the last decades, their lack of grounding in the real world is still an ongoing problem. In this paper, we focus on visual grounding of word embeddings and target two important questions. First, how can language benefit from vision in the process of visual grounding? And second, is there a link between visual grounding and abstract concepts? We investigate these questions by proposing a simple yet effective approach where language benefits from vision specifically with respect to the modeling of both concrete and abstract words. Our model aligns word embeddings with their corresponding visual representation without deteriorating the knowledge captured by textual distributional information. We apply our model to a behavioral experiment reported by G\"unther et al. (2020), which addresses the plausibility of having visual mental representations for abstract words. Our evaluation results show that: (1) It is possible to predict human behaviour to a large degree using purely textual embeddings. (2) Our grounded embeddings model human behavior better compared to their textual counterparts. (3) Abstract concepts benefit from visual grounding implicitly through their connections to concrete concepts, rather than from having corresponding visual representations.
Language with Vision: a Study on Grounded Word and Sentence Embeddings
Jun 17, 2022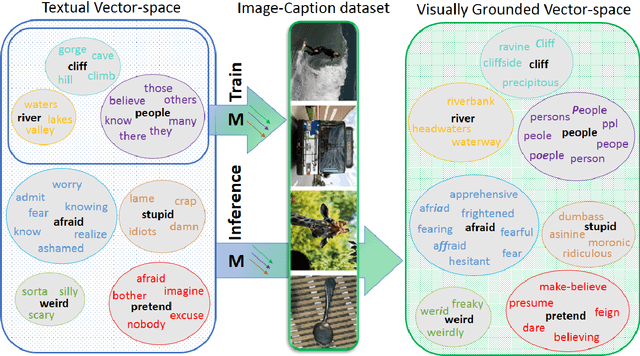
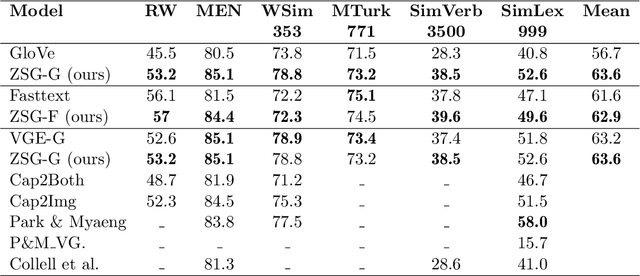
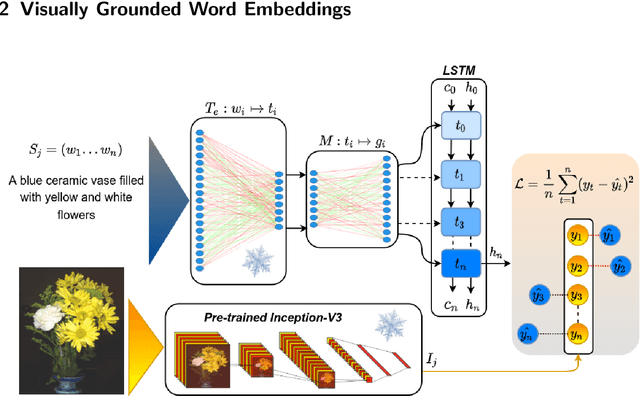

Language grounding to vision is an active field of research aiming to enrich text-based representations of word meanings by leveraging perceptual knowledge from vision. Despite many attempts at language grounding, it is still unclear how to effectively inject visual knowledge into the word embeddings of a language in such a way that a proper balance of textual and visual knowledge is maintained. Some common concerns are the following. Is visual grounding beneficial for abstract words or is its contribution only limited to concrete words? What is the optimal way of bridging the gap between text and vision? How much do we gain by visually grounding textual embeddings? The present study addresses these questions by proposing a simple yet very effective grounding approach for pre-trained word embeddings. Our model aligns textual embeddings with vision while largely preserving the distributional statistics that characterize word use in text corpora. By applying a learned alignment, we are able to generate visually grounded embeddings for unseen words, including abstract words. A series of evaluations on word similarity benchmarks shows that visual grounding is beneficial not only for concrete words, but also for abstract words. We also show that our method for visual grounding offers advantages for contextualized embeddings, but only when these are trained on corpora of relatively modest size. Code and grounded embeddings for English are available at https://github.com/Hazel1994/Visually_Grounded_Word_Embeddings_2.
Semantic properties of English nominal pluralization: Insights from word embeddings
Mar 29, 2022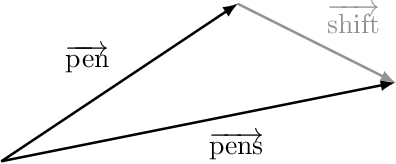
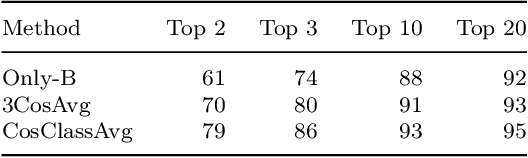
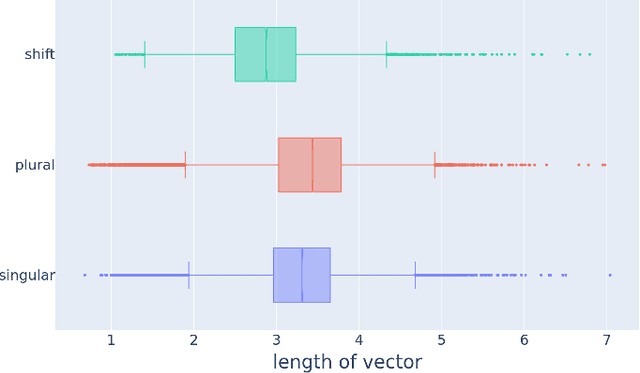
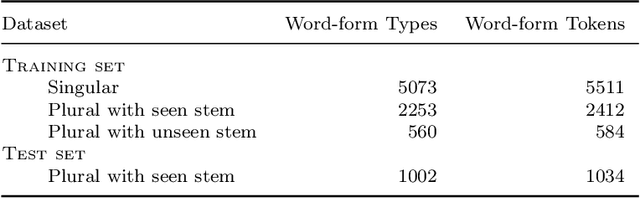
Semantic differentiation of nominal pluralization is grammaticalized in many languages. For example, plural markers may only be relevant for human nouns. English does not appear to make such distinctions. Using distributional semantics, we show that English nominal pluralization exhibits semantic clusters. For instance, pluralization of fruit words is more similar to one another and less similar to pluralization of other semantic classes. Therefore, reduction of the meaning shift in plural formation to the addition of an abstract plural meaning is too simplistic. A semantically informed method, called CosClassAvg, is introduced that outperforms pluralization methods in distributional semantics which assume plural formation amounts to the addition of a fixed plural vector. In comparison with our approach, a method from compositional distributional semantics, called FRACSS, predicted plural vectors that were more similar to the corpus-extracted plural vectors in terms of direction but not vector length. A modeling study reveals that the observed difference between the two predicted semantic spaces by CosClassAvg and FRACSS carries over to how well a computational model of the listener can understand previously unencountered plural forms. Mappings from word forms, represented with triphone vectors, to predicted semantic vectors are more productive when CosClassAvg-generated semantic vectors are employed as gold standard vectors instead of FRACSS-generated vectors.