 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs deeper always better? Replacing linear mappings with deep learning networks in the Discriminative Lexicon Model
Oct 05, 2024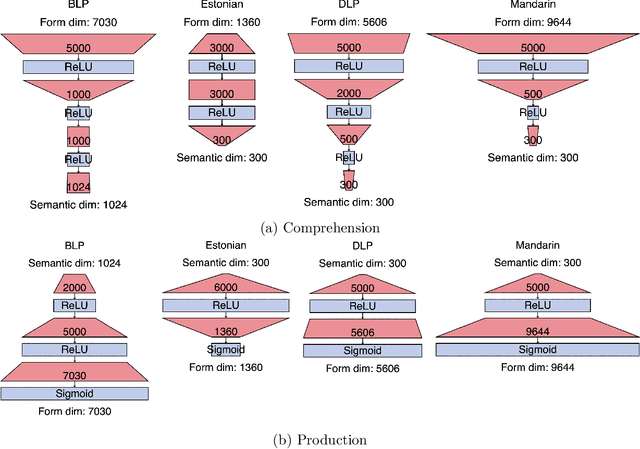
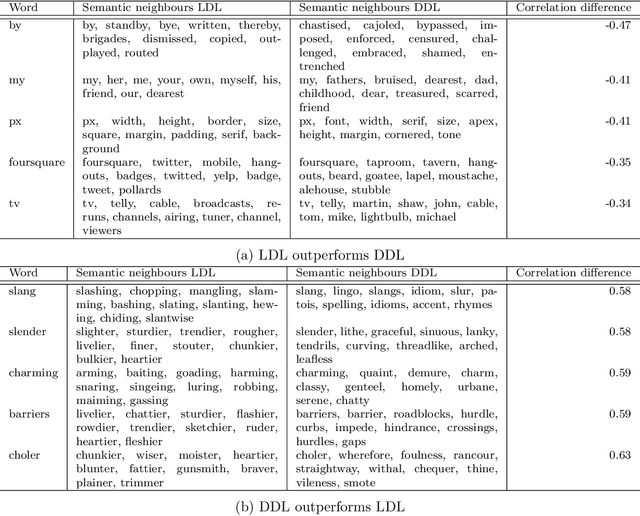
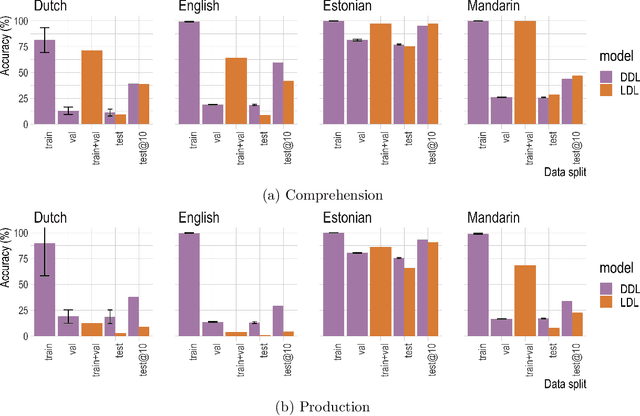
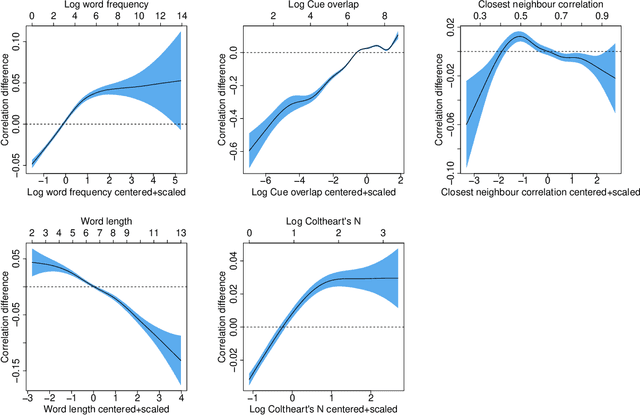
Recently, deep learning models have increasingly been used in cognitive modelling of language. This study asks whether deep learning can help us to better understand the learning problem that needs to be solved by speakers, above and beyond linear methods. We utilise the Discriminative Lexicon Model (DLM, Baayen et al., 2019), which models comprehension and production with mappings between numeric form and meaning vectors. While so far, these mappings have been linear (Linear Discriminative Learning, LDL), in the present study we replace them with deep dense neural networks (Deep Discriminative Learning, DDL). We find that DDL affords more accurate mappings for large and diverse datasets from English and Dutch, but not necessarily for Estonian and Taiwan Mandarin. DDL outperforms LDL in particular for words with pseudo-morphological structure such as slend+er. Applied to average reaction times, we find that DDL is outperformed by frequency-informed linear mappings (FIL). However, DDL trained in a frequency-informed way ('frequency-informed' deep learning, FIDDL) substantially outperforms FIL. Finally, while linear mappings can very effectively be updated from trial-to-trial to model incremental lexical learning (Heitmeier et al., 2023), deep mappings cannot do so as effectively. At present, both linear and deep mappings are informative for understanding language.
Frequency effects in Linear Discriminative Learning
Jun 19, 2023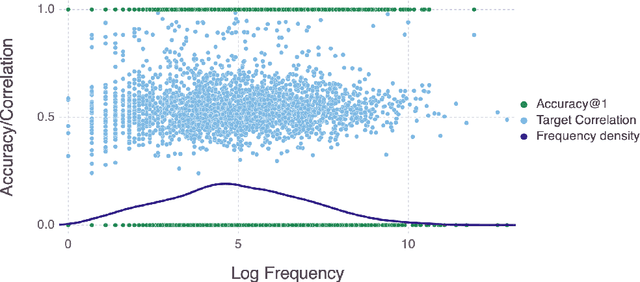
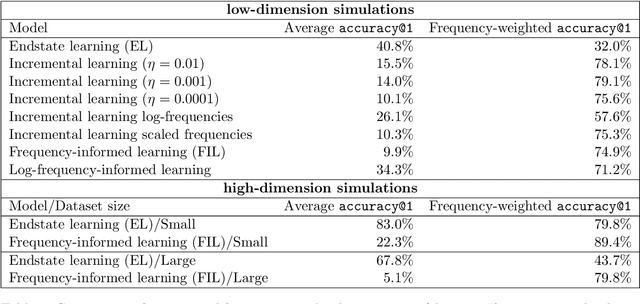
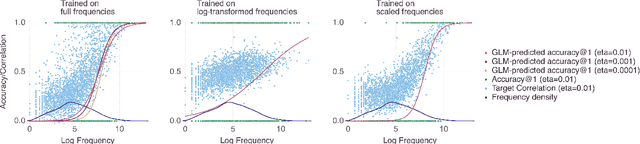
Word frequency is a strong predictor in most lexical processing tasks. Thus, any model of word recognition needs to account for how word frequency effects arise. The Discriminative Lexicon Model (DLM; Baayen et al., 2018a, 2019) models lexical processing with linear mappings between words' forms and their meanings. So far, the mappings can either be obtained incrementally via error-driven learning, a computationally expensive process able to capture frequency effects, or in an efficient, but frequency-agnostic closed-form solution modelling the theoretical endstate of learning (EL) where all words are learned optimally. In this study we show how an efficient, yet frequency-informed mapping between form and meaning can be obtained (Frequency-informed learning; FIL). We find that FIL well approximates an incremental solution while being computationally much cheaper. FIL shows a relatively low type- and high token-accuracy, demonstrating that the model is able to process most word tokens encountered by speakers in daily life correctly. We use FIL to model reaction times in the Dutch Lexicon Project (Keuleers et al., 2010) and find that FIL predicts well the S-shaped relationship between frequency and the mean of reaction times but underestimates the variance of reaction times for low frequency words. FIL is also better able to account for priming effects in an auditory lexical decision task in Mandarin Chinese (Lee, 2007), compared to EL. Finally, we used ordered data from CHILDES (Brown, 1973; Demuth et al., 2006) to compare mappings obtained with FIL and incremental learning. The mappings are highly correlated, but with FIL some nuances based on word ordering effects are lost. Our results show how frequency effects in a learning model can be simulated efficiently by means of a closed-form solution, and raise questions about how to best account for low-frequency words in cognitive models.
How trial-to-trial learning shapes mappings in the mental lexicon: Modelling Lexical Decision with Linear Discriminative Learning
Jul 01, 2022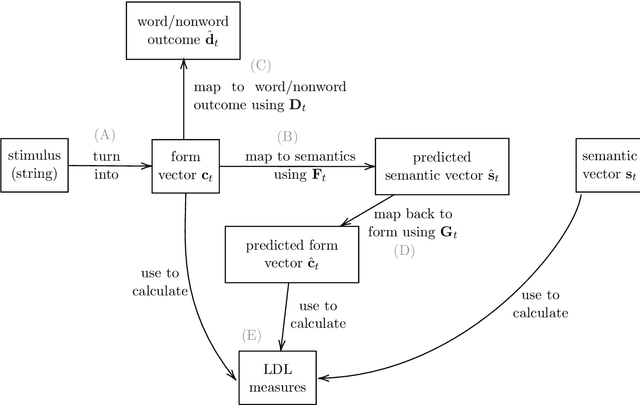


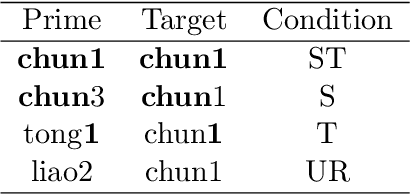
Priming and antipriming can be modelled with error-driven learning (Marsolek, 2008), by assuming that the learning of the prime influences processing of the target stimulus. This implies that participants are continuously learning in priming studies, and predicts that they are also learning in each trial of other psycholinguistic experiments. This study investigates whether trial-to-trial learning can be detected in lexical decision experiments. We used the Discriminative Lexicon Model (DLM; Baayen et al., 2019), a model of the mental lexicon with meaning representations from distributional semantics, which models incremental learning with the Widrow-Hoff rule. We used data from the British Lexicon Project (BLP; Keuleers et al., 2012) and simulated the lexical decision experiment with the DLM on a trial-by-trial basis for each subject individually. Then, reaction times for words and nonwords were predicted with Generalised Additive Models, using measures derived from the DLM simulations as predictors. Models were developed with the data of two subjects and tested on all other subjects. We extracted measures from two simulations for each subject (one with learning updates between trials and one without), and used them as input to two GAMs. Learning-based models showed better model fit than the non-learning ones for the majority of subjects. Our measures also provided insights into lexical processing and enabled us to explore individual differences with Linear Mixed Models. This demonstrates the potential of the DLM to model behavioural data and leads to the conclusion that trial-to-trial learning can indeed be detected in psycholinguistic experiments.
Visual grounding of abstract and concrete words: A response to Günther et al. (2020)
Jun 30, 2022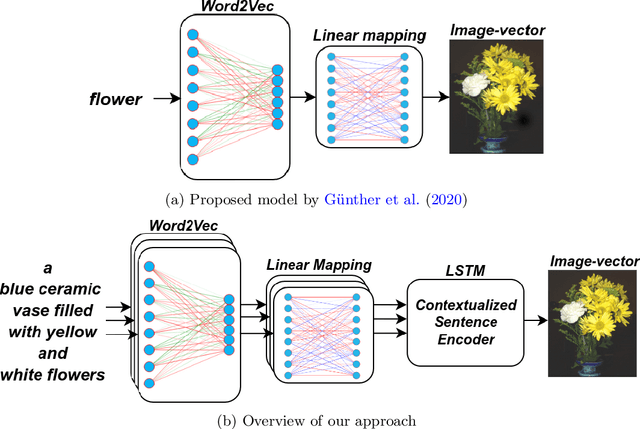

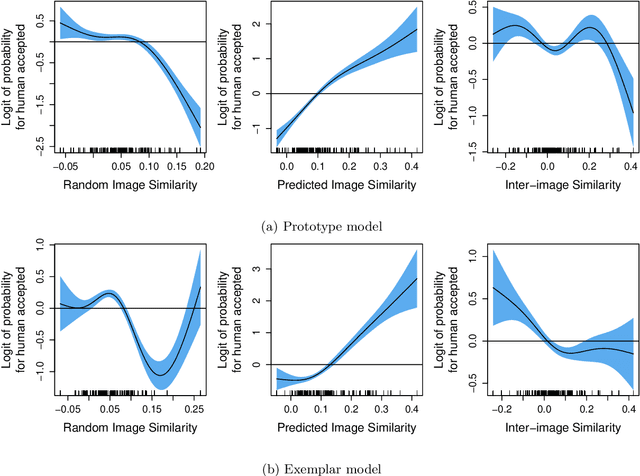
Current computational models capturing words' meaning mostly rely on textual corpora. While these approaches have been successful over the last decades, their lack of grounding in the real world is still an ongoing problem. In this paper, we focus on visual grounding of word embeddings and target two important questions. First, how can language benefit from vision in the process of visual grounding? And second, is there a link between visual grounding and abstract concepts? We investigate these questions by proposing a simple yet effective approach where language benefits from vision specifically with respect to the modeling of both concrete and abstract words. Our model aligns word embeddings with their corresponding visual representation without deteriorating the knowledge captured by textual distributional information. We apply our model to a behavioral experiment reported by G\"unther et al. (2020), which addresses the plausibility of having visual mental representations for abstract words. Our evaluation results show that: (1) It is possible to predict human behaviour to a large degree using purely textual embeddings. (2) Our grounded embeddings model human behavior better compared to their textual counterparts. (3) Abstract concepts benefit from visual grounding implicitly through their connections to concrete concepts, rather than from having corresponding visual representations.
Language with Vision: a Study on Grounded Word and Sentence Embeddings
Jun 17, 2022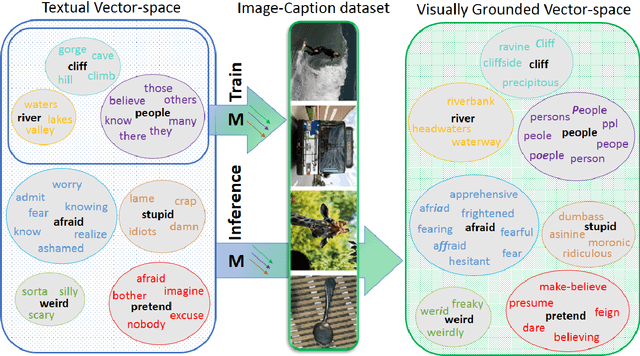
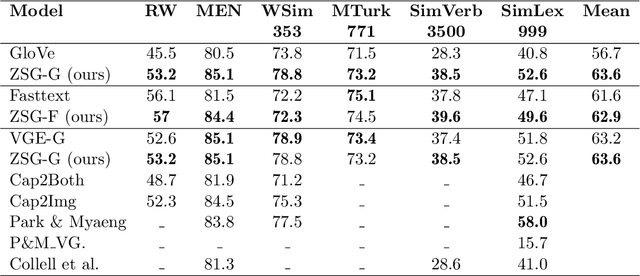
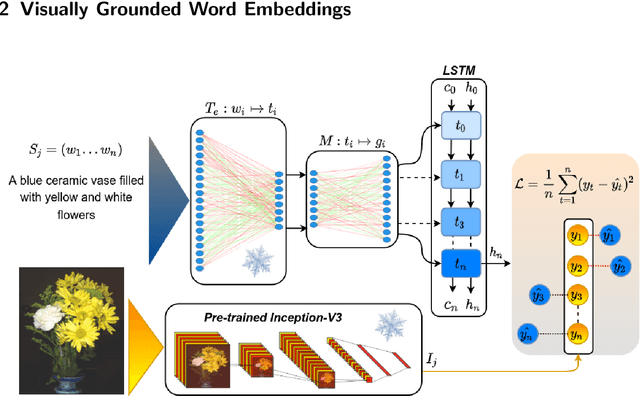

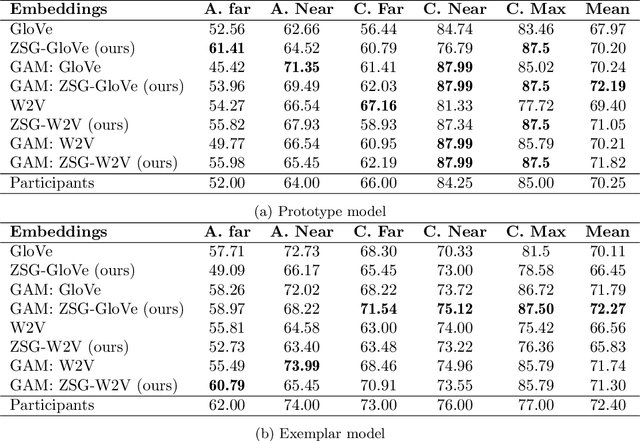
Language grounding to vision is an active field of research aiming to enrich text-based representations of word meanings by leveraging perceptual knowledge from vision. Despite many attempts at language grounding, it is still unclear how to effectively inject visual knowledge into the word embeddings of a language in such a way that a proper balance of textual and visual knowledge is maintained. Some common concerns are the following. Is visual grounding beneficial for abstract words or is its contribution only limited to concrete words? What is the optimal way of bridging the gap between text and vision? How much do we gain by visually grounding textual embeddings? The present study addresses these questions by proposing a simple yet very effective grounding approach for pre-trained word embeddings. Our model aligns textual embeddings with vision while largely preserving the distributional statistics that characterize word use in text corpora. By applying a learned alignment, we are able to generate visually grounded embeddings for unseen words, including abstract words. A series of evaluations on word similarity benchmarks shows that visual grounding is beneficial not only for concrete words, but also for abstract words. We also show that our method for visual grounding offers advantages for contextualized embeddings, but only when these are trained on corpora of relatively modest size. Code and grounded embeddings for English are available at https://github.com/Hazel1994/Visually_Grounded_Word_Embeddings_2.
Modeling morphology with Linear Discriminative Learning: considerations and design choices
Jun 15, 2021


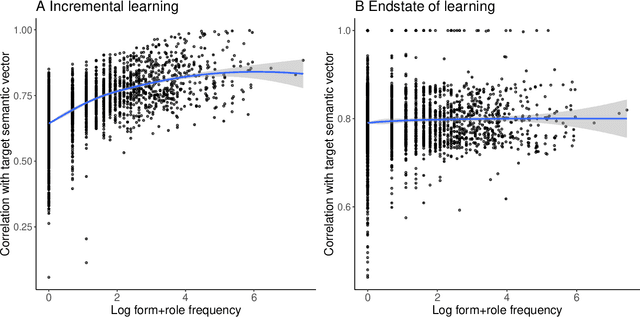
This study addresses a series of methodological questions that arise when modeling inflectional morphology with Linear Discriminative Learning. Taking the semi-productive German noun system as example, we illustrate how decisions made about the representation of form and meaning influence model performance. We clarify that for modeling frequency effects in learning, it is essential to make use of incremental learning rather than the endstate of learning. We also discuss how the model can be set up to approximate the learning of inflected words in context. In addition, we illustrate how in this approach the wug task can be modeled in considerable detail. In general, the model provides an excellent memory for known words, but appropriately shows more limited performance for unseen data, in line with the semi-productivity of German noun inflection and generalization performance of native German speakers.