 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Finnish Inflectional Classes through Discriminative Lexicon and Deep Learning Models
Sep 05, 2025Descriptions of complex nominal or verbal systems make use of inflectional classes. Inflectional classes bring together nouns which have similar stem changes and use similar exponents in their paradigms. Although inflectional classes can be very useful for language teaching as well as for setting up finite state morphological systems, it is unclear whether inflectional classes are cognitively real, in the sense that native speakers would need to discover these classes in order to learn how to properly inflect the nouns of their language. This study investigates whether the Discriminative Lexicon Model (DLM) can understand and produce Finnish inflected nouns without setting up inflectional classes, using a dataset with 55,271 inflected nouns of 2000 high-frequency Finnish nouns from 49 inflectional classes. Several DLM comprehension and production models were set up. Some models were not informed about frequency of use, and provide insight into learnability with infinite exposure (endstate learning). Other models were set up from a usage based perspective, and were trained with token frequencies being taken into consideration (frequency-informed learning). On training data, models performed with very high accuracies. For held-out test data, accuracies decreased, as expected, but remained acceptable. Across most models, performance increased for inflectional classes with more types, more lower-frequency words, and more hapax legomena, mirroring the productivity of the inflectional classes. The model struggles more with novel forms of unproductive and less productive classes, and performs far better for unseen forms belonging to productive classes. However, for usage-based production models, frequency was the dominant predictor of model performance, and correlations with measures of productivity were tenuous or absent.
The realization of tones in spontaneous spoken Taiwan Mandarin: a corpus-based survey and theory-driven computational modeling
Mar 29, 2025



A growing body of literature has demonstrated that semantics can co-determine fine phonetic detail. However, the complex interplay between phonetic realization and semantics remains understudied, particularly in pitch realization. The current study investigates the tonal realization of Mandarin disyllabic words with all 20 possible combinations of two tones, as found in a corpus of Taiwan Mandarin spontaneous speech. We made use of Generalized Additive Mixed Models (GAMs) to model f0 contours as a function of a series of predictors, including gender, tonal context, tone pattern, speech rate, word position, bigram probability, speaker and word. In the GAM analysis, word and sense emerged as crucial predictors of f0 contours, with effect sizes that exceed those of tone pattern. For each word token in our dataset, we then obtained a contextualized embedding by applying the GPT-2 large language model to the context of that token in the corpus. We show that the pitch contours of word tokens can be predicted to a considerable extent from these contextualized embeddings, which approximate token-specific meanings in contexts of use. The results of our corpus study show that meaning in context and phonetic realization are far more entangled than standard linguistic theory predicts.
Form and meaning co-determine the realization of tone in Taiwan Mandarin spontaneous speech: the case of Tone 3 sandhi
Aug 28, 2024



In Standard Chinese, Tone 3 (the dipping tone) becomes Tone 2 (rising tone) when followed by another Tone 3. Previous studies have noted that this sandhi process may be incomplete, in the sense that the assimilated Tone 3 is still distinct from a true Tone 2. While Mandarin Tone 3 sandhi is widely studied using carefully controlled laboratory speech (Xu, 1997) and more formal registers of Beijing Mandarin (Yuan and Chen, 2014), less is known about its realization in spontaneous speech, and about the effect of contextual factors on tonal realization. The present study investigates the pitch contours of two-character words with T2-T3 and T3-T3 tone patterns in spontaneous Taiwan Mandarin conversations. Our analysis makes use of the Generative Additive Mixed Model (GAMM, Wood, 2017) to examine fundamental frequency (f0) contours as a function of normalized time. We consider various factors known to influence pitch contours, including gender, speaking rate, speaker, neighboring tones, word position, bigram probability, and also novel predictors, word and word sense (Chuang et al., 2024). Our analyses revealed that in spontaneous Taiwan Mandarin, T3-T3 words become indistinguishable from T2-T3 words, indicating complete sandhi, once the strong effect of word (or word sense) is taken into account. For our data, the shape of f0 contours is not co-determined by word frequency. In contrast, the effect of word meaning on f0 contours is robust, as strong as the effect of adjacent tones, and is present for both T2-T3 and T3-T3 words.
Word-specific tonal realizations in Mandarin
May 11, 2024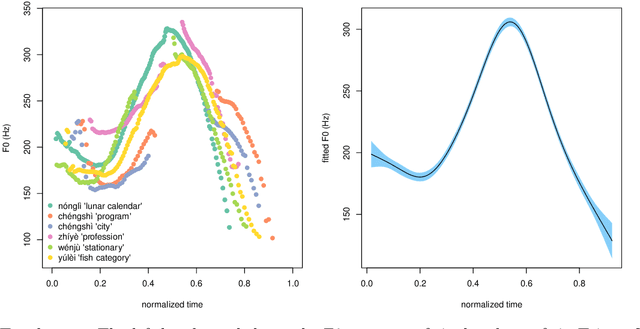
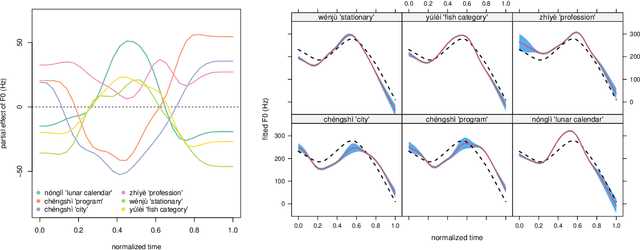
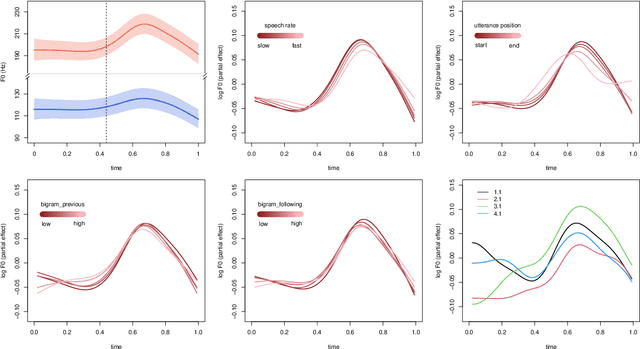
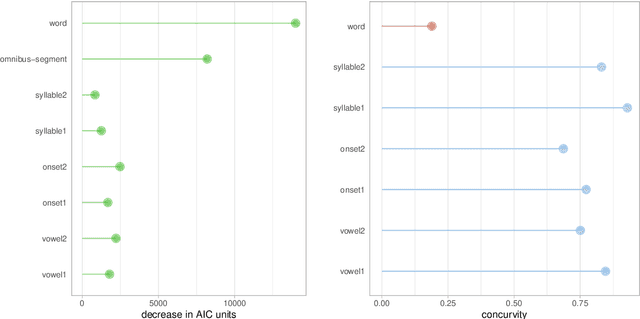
The pitch contours of Mandarin two-character words are generally understood as being shaped by the underlying tones of the constituent single-character words, in interaction with articulatory constraints imposed by factors such as speech rate, co-articulation with adjacent tones, segmental make-up, and predictability. This study shows that tonal realization is also partially determined by words' meanings. We first show, on the basis of a Taiwan corpus of spontaneous conversations, using the generalized additive regression model, and focusing on the rise-fall tone pattern, that after controlling for effects of speaker and context, word type is a stronger predictor of pitch realization than all the previously established word-form related predictors combined. Importantly, the addition of information about meaning in context improves prediction accuracy even further. We then proceed to show, using computational modeling with context-specific word embeddings, that token-specific pitch contours predict word type with 50% accuracy on held-out data, and that context-sensitive, token-specific embeddings can predict the shape of pitch contours with 30% accuracy. These accuracies, which are an order of magnitude above chance level, suggest that the relation between words' pitch contours and their meanings are sufficiently strong to be functional for language users. The theoretical implications of these empirical findings are discussed.
Investigating differences in lab-quality and remote recording methods with dynamic acoustic measures
Apr 25, 2024Increasingly, phonetic research utilizes data collected from participants who record themselves on readily available devices. Though such recordings are convenient, their suitability for acoustic analysis remains an open question, especially regarding how the individual methods affect acoustic measures over time. We used Quantile Generalized Additive Mixed Models (QGAMMs) to analyze measures of F0, intensity, and the first and second formants, comparing files recorded using a laboratory-standard recording method (Zoom H6 Recorder with an external microphone), to three remote recording methods, (1) the Awesome Voice Recorder application on a smartphone (AVR), (2) the Zoom meeting application with default settings (Zoom-default), and (3) the Zoom meeting application with the "Turn on Original Sound" setting (Zoom-raw). A linear temporal alignment issue was observed for the Zoom methods over the course of the long, recording session files. However, the difference was not significant for utterance-length files. F0 was reliably measured using all methods. Intensity and formants presented non-linear differences across methods that could not be corrected for simply. Overall, the AVR files were most similar to the H6's, and so AVR is deemed to be a more reliable recording method than either Zoom-default or Zoom-raw.
Frequency effects in Linear Discriminative Learning
Jun 19, 2023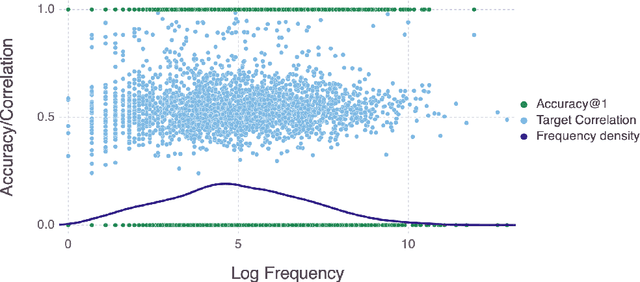
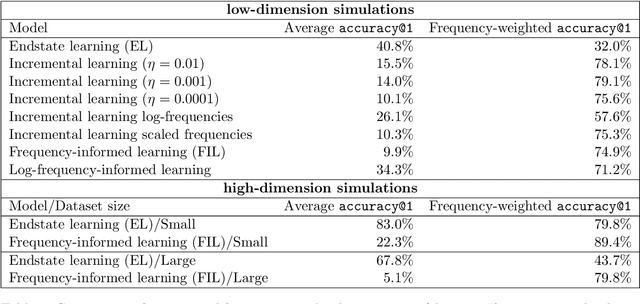
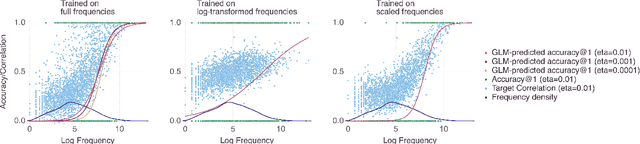
Word frequency is a strong predictor in most lexical processing tasks. Thus, any model of word recognition needs to account for how word frequency effects arise. The Discriminative Lexicon Model (DLM; Baayen et al., 2018a, 2019) models lexical processing with linear mappings between words' forms and their meanings. So far, the mappings can either be obtained incrementally via error-driven learning, a computationally expensive process able to capture frequency effects, or in an efficient, but frequency-agnostic closed-form solution modelling the theoretical endstate of learning (EL) where all words are learned optimally. In this study we show how an efficient, yet frequency-informed mapping between form and meaning can be obtained (Frequency-informed learning; FIL). We find that FIL well approximates an incremental solution while being computationally much cheaper. FIL shows a relatively low type- and high token-accuracy, demonstrating that the model is able to process most word tokens encountered by speakers in daily life correctly. We use FIL to model reaction times in the Dutch Lexicon Project (Keuleers et al., 2010) and find that FIL predicts well the S-shaped relationship between frequency and the mean of reaction times but underestimates the variance of reaction times for low frequency words. FIL is also better able to account for priming effects in an auditory lexical decision task in Mandarin Chinese (Lee, 2007), compared to EL. Finally, we used ordered data from CHILDES (Brown, 1973; Demuth et al., 2006) to compare mappings obtained with FIL and incremental learning. The mappings are highly correlated, but with FIL some nuances based on word ordering effects are lost. Our results show how frequency effects in a learning model can be simulated efficiently by means of a closed-form solution, and raise questions about how to best account for low-frequency words in cognitive models.
How trial-to-trial learning shapes mappings in the mental lexicon: Modelling Lexical Decision with Linear Discriminative Learning
Jul 01, 2022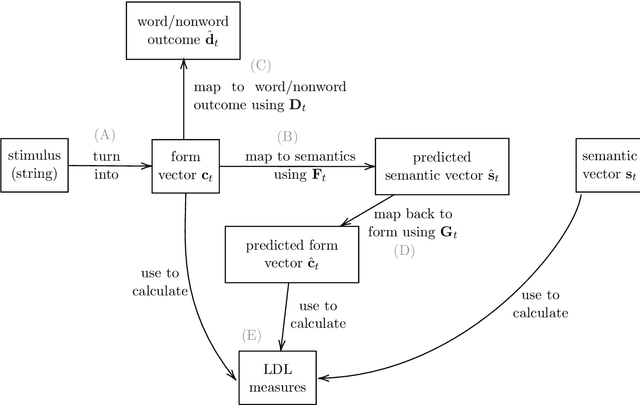


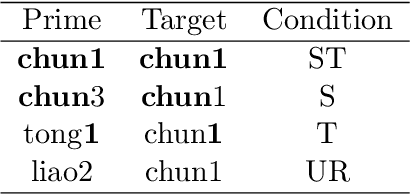
Priming and antipriming can be modelled with error-driven learning (Marsolek, 2008), by assuming that the learning of the prime influences processing of the target stimulus. This implies that participants are continuously learning in priming studies, and predicts that they are also learning in each trial of other psycholinguistic experiments. This study investigates whether trial-to-trial learning can be detected in lexical decision experiments. We used the Discriminative Lexicon Model (DLM; Baayen et al., 2019), a model of the mental lexicon with meaning representations from distributional semantics, which models incremental learning with the Widrow-Hoff rule. We used data from the British Lexicon Project (BLP; Keuleers et al., 2012) and simulated the lexical decision experiment with the DLM on a trial-by-trial basis for each subject individually. Then, reaction times for words and nonwords were predicted with Generalised Additive Models, using measures derived from the DLM simulations as predictors. Models were developed with the data of two subjects and tested on all other subjects. We extracted measures from two simulations for each subject (one with learning updates between trials and one without), and used them as input to two GAMs. Learning-based models showed better model fit than the non-learning ones for the majority of subjects. Our measures also provided insights into lexical processing and enabled us to explore individual differences with Linear Mixed Models. This demonstrates the potential of the DLM to model behavioural data and leads to the conclusion that trial-to-trial learning can indeed be detected in psycholinguistic experiments.
Vector Space Morphology with Linear Discriminative Learning
Jul 08, 2021
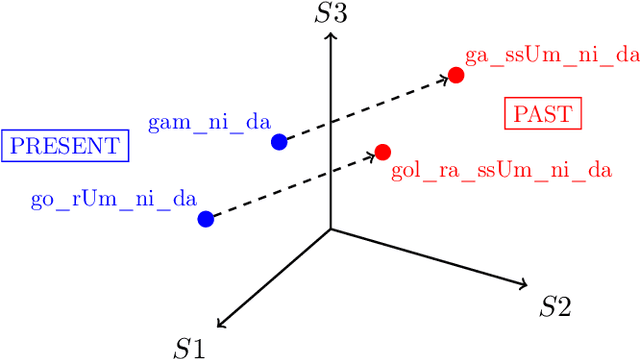

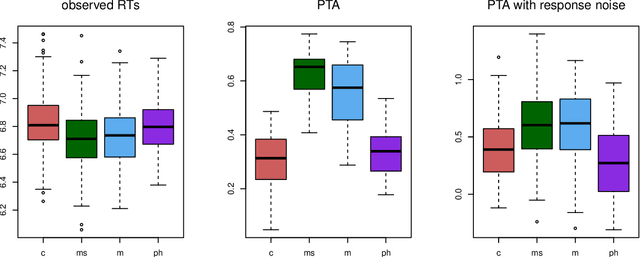
This paper presents three case studies of modeling aspects of lexical processing with Linear Discriminative Learning (LDL), the computational engine of the Discriminative Lexicon model (Baayen et al., 2019). With numeric representations of word forms and meanings, LDL learns to map one vector space onto the other, without being informed about any morphological structure or inflectional classes. The modeling results demonstrated that LDL not only performs well for understanding and producing morphologically complex words, but also generates quantitative measures that are predictive for human behavioral data. LDL models are straightforward to implement with the JudiLing package (Luo et al., 2021). Worked examples are provided for three modeling challenges: producing and understanding Korean verb inflection, predicting primed Dutch lexical decision latencies, and predicting the acoustic duration of Mandarin words.
Modeling morphology with Linear Discriminative Learning: considerations and design choices
Jun 15, 2021


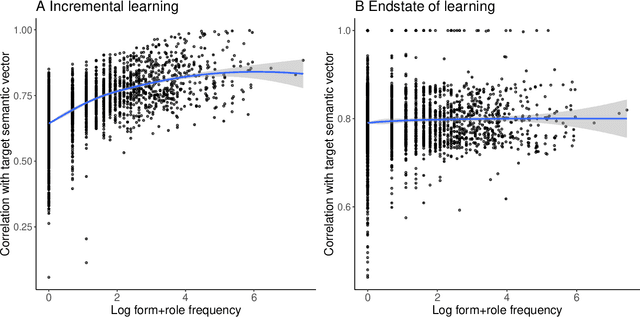
This study addresses a series of methodological questions that arise when modeling inflectional morphology with Linear Discriminative Learning. Taking the semi-productive German noun system as example, we illustrate how decisions made about the representation of form and meaning influence model performance. We clarify that for modeling frequency effects in learning, it is essential to make use of incremental learning rather than the endstate of learning. We also discuss how the model can be set up to approximate the learning of inflected words in context. In addition, we illustrate how in this approach the wug task can be modeled in considerable detail. In general, the model provides an excellent memory for known words, but appropriately shows more limited performance for unseen data, in line with the semi-productivity of German noun inflection and generalization performance of native German speakers.