 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency effects in Linear Discriminative Learning
Jun 19, 2023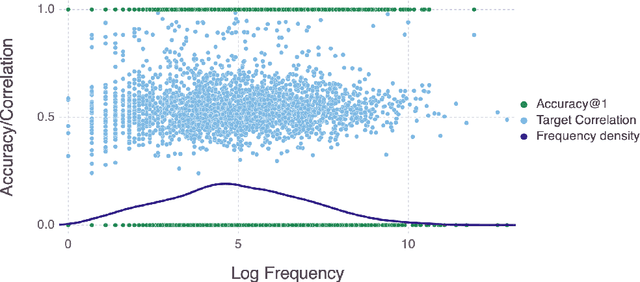
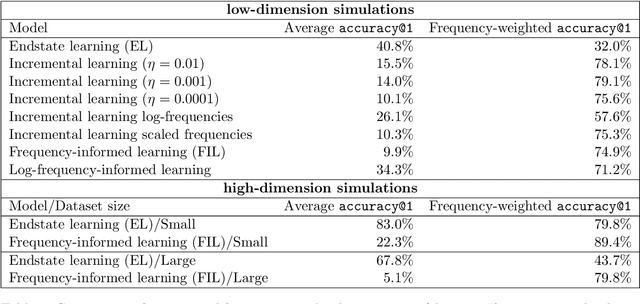
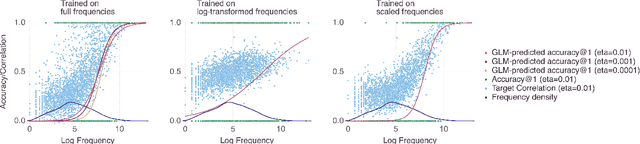
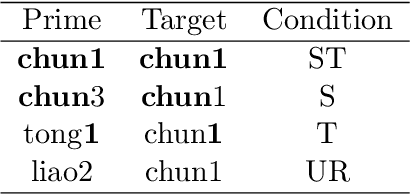
Word frequency is a strong predictor in most lexical processing tasks. Thus, any model of word recognition needs to account for how word frequency effects arise. The Discriminative Lexicon Model (DLM; Baayen et al., 2018a, 2019) models lexical processing with linear mappings between words' forms and their meanings. So far, the mappings can either be obtained incrementally via error-driven learning, a computationally expensive process able to capture frequency effects, or in an efficient, but frequency-agnostic closed-form solution modelling the theoretical endstate of learning (EL) where all words are learned optimally. In this study we show how an efficient, yet frequency-informed mapping between form and meaning can be obtained (Frequency-informed learning; FIL). We find that FIL well approximates an incremental solution while being computationally much cheaper. FIL shows a relatively low type- and high token-accuracy, demonstrating that the model is able to process most word tokens encountered by speakers in daily life correctly. We use FIL to model reaction times in the Dutch Lexicon Project (Keuleers et al., 2010) and find that FIL predicts well the S-shaped relationship between frequency and the mean of reaction times but underestimates the variance of reaction times for low frequency words. FIL is also better able to account for priming effects in an auditory lexical decision task in Mandarin Chinese (Lee, 2007), compared to EL. Finally, we used ordered data from CHILDES (Brown, 1973; Demuth et al., 2006) to compare mappings obtained with FIL and incremental learning. The mappings are highly correlated, but with FIL some nuances based on word ordering effects are lost. Our results show how frequency effects in a learning model can be simulated efficiently by means of a closed-form solution, and raise questions about how to best account for low-frequency words in cognitive models.
Spatiotemporal modeling of European paleoclimate using doubly sparse Gaussian processes
Nov 15, 2022Paleoclimatology -- the study of past climate -- is relevant beyond climate science itself, such as in archaeology and anthropology for understanding past human dispersal. Information about the Earth's paleoclimate comes from simulations of physical and biogeochemical processes and from proxy records found in naturally occurring archives. Climate-field reconstructions (CFRs) combine these data into a statistical spatial or spatiotemporal model. To date, there exists no consensus spatiotemporal paleoclimate model that is continuous in space and time, produces predictions with uncertainty, and can include data from various sources. A Gaussian process (GP) model would have these desired properties; however, GPs scale unfavorably with data of the magnitude typical for building CFRs. We propose to build on recent advances in sparse spatiotemporal GPs that reduce the computational burden by combining variational methods based on inducing variables with the state-space formulation of GPs. We successfully employ such a doubly sparse GP to construct a probabilistic model of European paleoclimate from the Last Glacial Maximum (LGM) to the mid-Holocene (MH) that synthesizes paleoclimate simulations and fossilized pollen proxy data.