 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel VAE-DML fusion framework for casual analysis of greenwashing in the mining industry
Jan 31, 2026Against the backdrop of the global green transition and "dual carbon" goals, mining industry chain enterprises are pivotal entities in terms of resource consumption and environmental impact. Their environmental performance directly affects regional ecological security and is closely tied to national resource strategies and green transformation outcomes. Ensuring the authenticity and reliability of their environmental disclosure is thus a core and urgent issue for sustainable development and national strategic objectives.From a corporate governance perspective, this study examines equity balance as a fundamental governance mechanism, investigating its inhibitory effect on greenwashing behavior among these enterprises and the underlying pathways involved. Methodologically, the paper innovatively employs a Variational Autoencoder (VAE) and a Double Machine Learning (DML) model to construct counterfactual scenarios, mitigating endogeneity concerns and precisely identifying the causal relationship between equity balance and greenwashing. The findings indicate, first, a significant negative causal relationship between equity balance and corporate greenwashing, confirming its substantive governance effect. Second, this inhibitory effect exhibits notable heterogeneity, manifesting more strongly in western regions, upstream segments of the industrial chain, and industries with high environmental sensitivity. Third, the governance effect demonstrates clear temporal dynamics, with the strongest impact occurring in the current period, followed by a diminishing yet statistically significant lagged effect, and ultimately a stable long-term cumulative influence. Finally, mechanism analysis reveals that equity balance operates through three distinct channels to curb greenwashing: alleviating management performance pressure, enhancing the stability of the executive team, and intensifying media scrutiny.
The realization of tones in spontaneous spoken Taiwan Mandarin: a corpus-based survey and theory-driven computational modeling
Mar 29, 2025



A growing body of literature has demonstrated that semantics can co-determine fine phonetic detail. However, the complex interplay between phonetic realization and semantics remains understudied, particularly in pitch realization. The current study investigates the tonal realization of Mandarin disyllabic words with all 20 possible combinations of two tones, as found in a corpus of Taiwan Mandarin spontaneous speech. We made use of Generalized Additive Mixed Models (GAMs) to model f0 contours as a function of a series of predictors, including gender, tonal context, tone pattern, speech rate, word position, bigram probability, speaker and word. In the GAM analysis, word and sense emerged as crucial predictors of f0 contours, with effect sizes that exceed those of tone pattern. For each word token in our dataset, we then obtained a contextualized embedding by applying the GPT-2 large language model to the context of that token in the corpus. We show that the pitch contours of word tokens can be predicted to a considerable extent from these contextualized embeddings, which approximate token-specific meanings in contexts of use. The results of our corpus study show that meaning in context and phonetic realization are far more entangled than standard linguistic theory predicts.
Form and meaning co-determine the realization of tone in Taiwan Mandarin spontaneous speech: the case of Tone 3 sandhi
Aug 28, 2024



In Standard Chinese, Tone 3 (the dipping tone) becomes Tone 2 (rising tone) when followed by another Tone 3. Previous studies have noted that this sandhi process may be incomplete, in the sense that the assimilated Tone 3 is still distinct from a true Tone 2. While Mandarin Tone 3 sandhi is widely studied using carefully controlled laboratory speech (Xu, 1997) and more formal registers of Beijing Mandarin (Yuan and Chen, 2014), less is known about its realization in spontaneous speech, and about the effect of contextual factors on tonal realization. The present study investigates the pitch contours of two-character words with T2-T3 and T3-T3 tone patterns in spontaneous Taiwan Mandarin conversations. Our analysis makes use of the Generative Additive Mixed Model (GAMM, Wood, 2017) to examine fundamental frequency (f0) contours as a function of normalized time. We consider various factors known to influence pitch contours, including gender, speaking rate, speaker, neighboring tones, word position, bigram probability, and also novel predictors, word and word sense (Chuang et al., 2024). Our analyses revealed that in spontaneous Taiwan Mandarin, T3-T3 words become indistinguishable from T2-T3 words, indicating complete sandhi, once the strong effect of word (or word sense) is taken into account. For our data, the shape of f0 contours is not co-determined by word frequency. In contrast, the effect of word meaning on f0 contours is robust, as strong as the effect of adjacent tones, and is present for both T2-T3 and T3-T3 words.
Simple, Effective and General: A New Backbone for Cross-view Image Geo-localization
Feb 03, 2023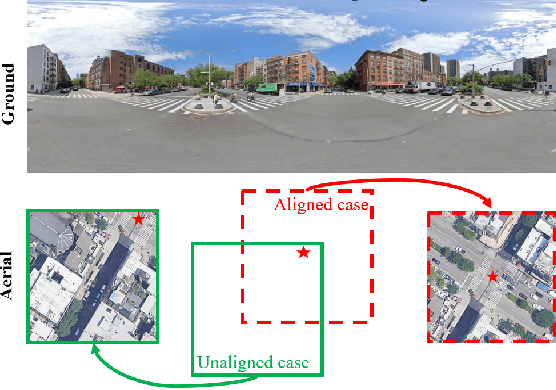
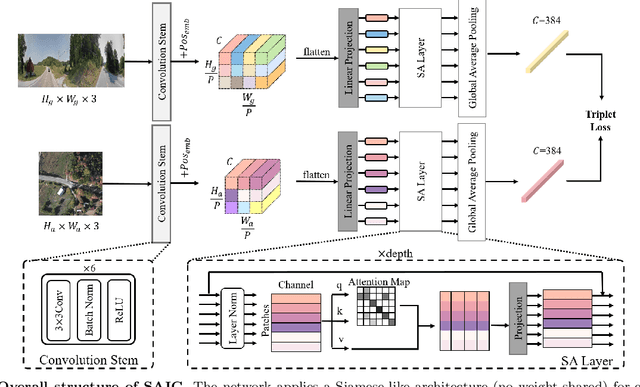

In this work, we aim at an important but less explored problem of a simple yet effective backbone specific for cross-view geo-localization task. Existing methods for cross-view geo-localization tasks are frequently characterized by 1) complicated methodologies, 2) GPU-consuming computations, and 3) a stringent assumption that aerial and ground images are centrally or orientation aligned. To address the above three challenges for cross-view image matching, we propose a new backbone network, named Simple Attention-based Image Geo-localization network (SAIG). The proposed SAIG effectively represents long-range interactions among patches as well as cross-view correspondence with multi-head self-attention layers. The "narrow-deep" architecture of our SAIG improves the feature richness without degradation in performance, while its shallow and effective convolutional stem preserves the locality, eliminating the loss of patchify boundary information. Our SAIG achieves state-of-the-art results on cross-view geo-localization, while being far simpler than previous works. Furthermore, with only 15.9% of the model parameters and half of the output dimension compared to the state-of-the-art, the SAIG adapts well across multiple cross-view datasets without employing any well-designed feature aggregation modules or feature alignment algorithms. In addition, our SAIG attains competitive scores on image retrieval benchmarks, further demonstrating its generalizability. As a backbone network, our SAIG is both easy to follow and computationally lightweight, which is meaningful in practical scenario. Moreover, we propose a simple Spatial-Mixed feature aggregation moDule (SMD) that can mix and project spatial information into a low-dimensional space to generate feature descriptors... (The code is available at https://github.com/yanghongji2007/SAIG)
Deep Multi-Task Learning for Cooperative NOMA: System Design and Principles
Jul 27, 2020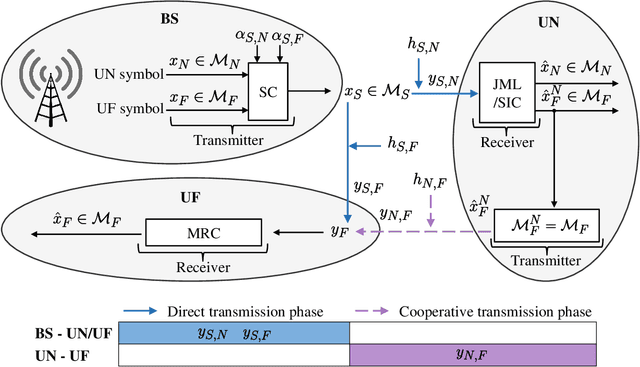
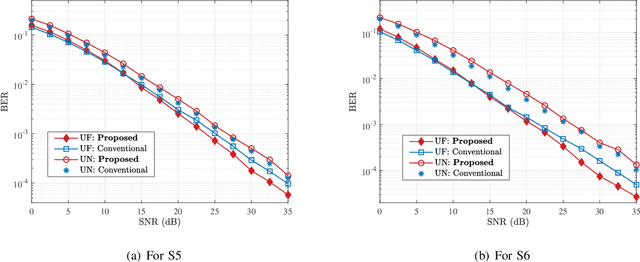
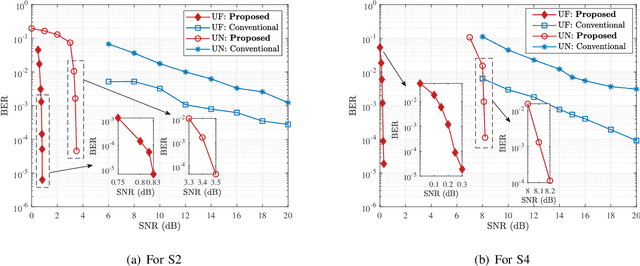
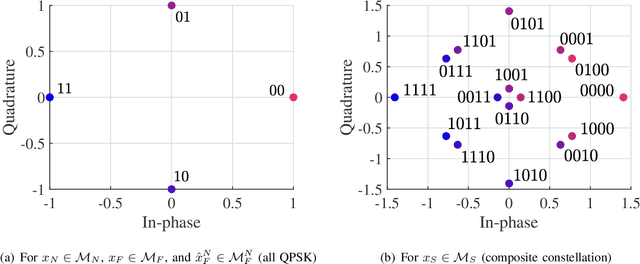
Envisioned as a promising component of the future wireless Internet-of-Things (IoT) networks, the non-orthogonal multiple access (NOMA) technique can support massive connectivity with a significantly increased spectral efficiency. Cooperative NOMA is able to further improve the communication reliability of users under poor channel conditions. However, the conventional system design suffers from several inherent limitations and is not optimized from the bit error rate (BER) perspective. In this paper, we develop a novel deep cooperative NOMA scheme, drawing upon the recent advances in deep learning (DL). We develop a novel hybrid-cascaded deep neural network (DNN) architecture such that the entire system can be optimized in a holistic manner. On this basis, we construct multiple loss functions to quantify the BER performance and propose a novel multi-task oriented two-stage training method to solve the end-to-end training problem in a self-supervised manner. The learning mechanism of each DNN module is then analyzed based on information theory, offering insights into the proposed DNN architecture and its corresponding training method. We also adapt the proposed scheme to handle the power allocation (PA) mismatch between training and inference and incorporate it with channel coding to combat signal deterioration. Simulation results verify its advantages over orthogonal multiple access (OMA) and the conventional cooperative NOMA scheme in various scenarios.