 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanMoVLM: Large Vision-Language Models for Professional Artistic Painting Evaluation
Mar 11, 2026While Large Vision-Language Models (VLMs) demonstrate impressive general visual capabilities, they remain artistically blind and unable to offer professional evaluation of artworks within specific artistic domains like human experts. To bridge this gap, we transform VLMs into experts capable of professional-grade painting evaluation in the Chinese Artistic Domain, which is more abstract and demands extensive artistic training for evaluation. We introduce HanMo-Bench, a new dataset that features authentic auction-grade masterpieces and AI-generated works, grounded in real-world market valuations. To realize the rigorous judgment, we propose the HanMoVLM and construct a Chain-of-Thought (CoT) validated by experts. This CoT guides the model to perform expert-level reasoning: from content identification and Region of Interest (RoI) localization to professional evaluation, guided by both theme-specific evaluation and typical three-tier evaluation in Chinese paintings. Furthermore, we design a reward function to refine the reasoning process of the HanMoVLM to improve the accuracy. We demonstrate that HanMoVLM can serve as a critical backbone for Test-time Scaling in image generation. By acting as a high-quality verifier, HanMoVLM enables generative models to select the most artistically superior outputs from multiple candidates. Experimental results and human studies confirm that the proposed HanMoVLM effectively bridges the gap, achieving a high consistency with professional experts and significantly improving the quality of Chinese Painting generation.
Self-Rewarding Large Vision-Language Models for Optimizing Prompts in Text-to-Image Generation
May 22, 2025



Text-to-image models are powerful for producing high-quality images based on given text prompts, but crafting these prompts often requires specialized vocabulary. To address this, existing methods train rewriting models with supervision from large amounts of manually annotated data and trained aesthetic assessment models. To alleviate the dependence on data scale for model training and the biases introduced by trained models, we propose a novel prompt optimization framework, designed to rephrase a simple user prompt into a sophisticated prompt to a text-to-image model. Specifically, we employ the large vision language models (LVLMs) as the solver to rewrite the user prompt, and concurrently, employ LVLMs as a reward model to score the aesthetics and alignment of the images generated by the optimized prompt. Instead of laborious human feedback, we exploit the prior knowledge of the LVLM to provide rewards, i.e., AI feedback. Simultaneously, the solver and the reward model are unified into one model and iterated in reinforcement learning to achieve self-improvement by giving a solution and judging itself. Results on two popular datasets demonstrate that our method outperforms other strong competitors.
DC-ControlNet: Decoupling Inter- and Intra-Element Conditions in Image Generation with Diffusion Models
Feb 20, 2025



In this paper, we introduce DC (Decouple)-ControlNet, a highly flexible and precisely controllable framework for multi-condition image generation. The core idea behind DC-ControlNet is to decouple control conditions, transforming global control into a hierarchical system that integrates distinct elements, contents, and layouts. This enables users to mix these individual conditions with greater flexibility, leading to more efficient and accurate image generation control. Previous ControlNet-based models rely solely on global conditions, which affect the entire image and lack the ability of element- or region-specific control. This limitation reduces flexibility and can cause condition misunderstandings in multi-conditional image generation. To address these challenges, we propose both intra-element and Inter-element Controllers in DC-ControlNet. The Intra-Element Controller handles different types of control signals within individual elements, accurately describing the content and layout characteristics of the object. For interactions between elements, we introduce the Inter-Element Controller, which accurately handles multi-element interactions and occlusion based on user-defined relationships. Extensive evaluations show that DC-ControlNet significantly outperforms existing ControlNet models and Layout-to-Image generative models in terms of control flexibility and precision in multi-condition control.
Retrieval-guided Cross-view Image Synthesis
Nov 29, 2024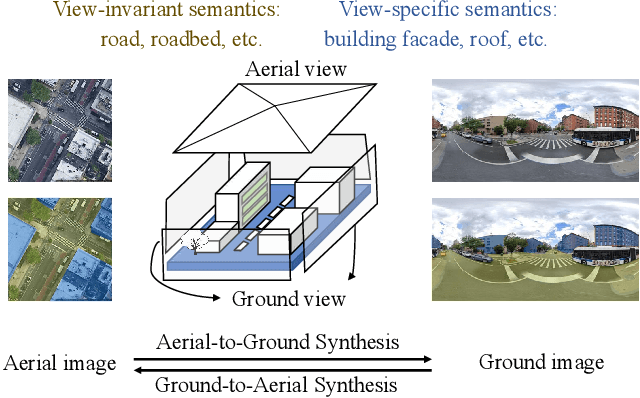


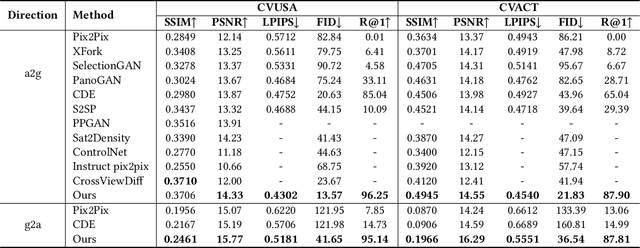
Cross-view image synthesis involves generating new images of a scene from different viewpoints or perspectives, given one input image from other viewpoints. Despite recent advancements, there are several limitations in existing methods: 1) reliance on additional data such as semantic segmentation maps or preprocessing modules to bridge the domain gap; 2) insufficient focus on view-specific semantics, leading to compromised image quality and realism; and 3) a lack of diverse datasets representing complex urban environments. To tackle these challenges, we propose: 1) a novel retrieval-guided framework that employs a retrieval network as an embedder to address the domain gap; 2) an innovative generator that enhances semantic consistency and diversity specific to the target view to improve image quality and realism; and 3) a new dataset, VIGOR-GEN, providing diverse cross-view image pairs in urban settings to enrich dataset diversity. Extensive experiments on well-known CVUSA, CVACT, and new VIGOR-GEN datasets demonstrate that our method generates images of superior realism, significantly outperforming current leading approaches, particularly in SSIM and FID evaluations.
Simple, Effective and General: A New Backbone for Cross-view Image Geo-localization
Feb 03, 2023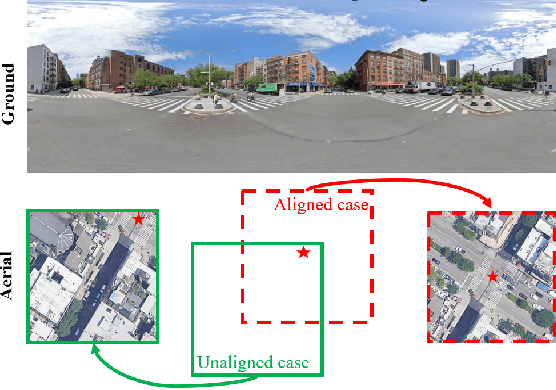
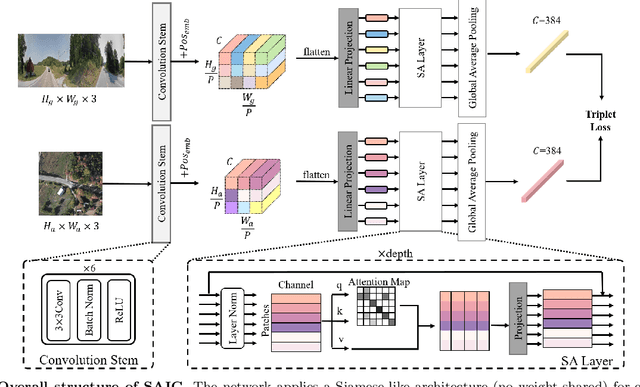

In this work, we aim at an important but less explored problem of a simple yet effective backbone specific for cross-view geo-localization task. Existing methods for cross-view geo-localization tasks are frequently characterized by 1) complicated methodologies, 2) GPU-consuming computations, and 3) a stringent assumption that aerial and ground images are centrally or orientation aligned. To address the above three challenges for cross-view image matching, we propose a new backbone network, named Simple Attention-based Image Geo-localization network (SAIG). The proposed SAIG effectively represents long-range interactions among patches as well as cross-view correspondence with multi-head self-attention layers. The "narrow-deep" architecture of our SAIG improves the feature richness without degradation in performance, while its shallow and effective convolutional stem preserves the locality, eliminating the loss of patchify boundary information. Our SAIG achieves state-of-the-art results on cross-view geo-localization, while being far simpler than previous works. Furthermore, with only 15.9% of the model parameters and half of the output dimension compared to the state-of-the-art, the SAIG adapts well across multiple cross-view datasets without employing any well-designed feature aggregation modules or feature alignment algorithms. In addition, our SAIG attains competitive scores on image retrieval benchmarks, further demonstrating its generalizability. As a backbone network, our SAIG is both easy to follow and computationally lightweight, which is meaningful in practical scenario. Moreover, we propose a simple Spatial-Mixed feature aggregation moDule (SMD) that can mix and project spatial information into a low-dimensional space to generate feature descriptors... (The code is available at https://github.com/yanghongji2007/SAIG)
Cross-view Geo-localization with Evolving Transformer
Jul 05, 2021
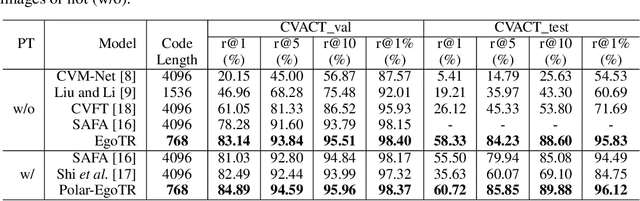
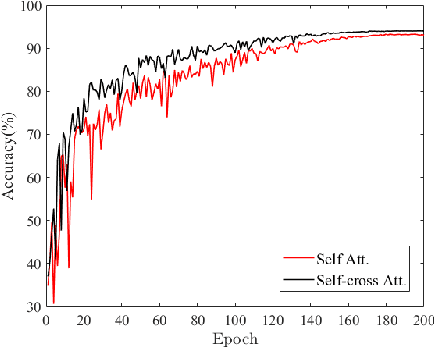
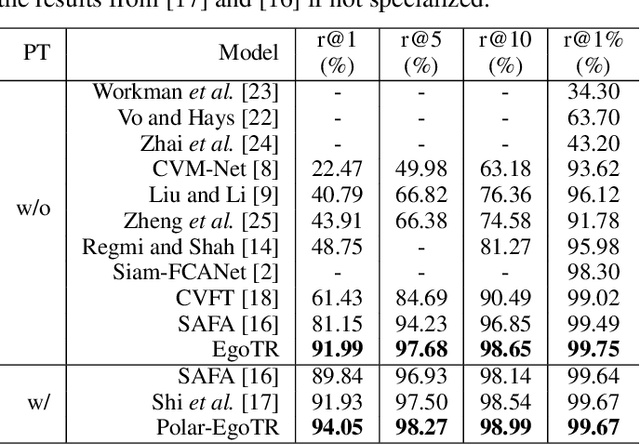
In this work, we address the problem of cross-view geo-localization, which estimates the geospatial location of a street view image by matching it with a database of geo-tagged aerial images. The cross-view matching task is extremely challenging due to drastic appearance and geometry differences across views. Unlike existing methods that predominantly fall back on CNN, here we devise a novel evolving geo-localization Transformer (EgoTR) that utilizes the properties of self-attention in Transformer to model global dependencies, thus significantly decreasing visual ambiguities in cross-view geo-localization. We also exploit the positional encoding of Transformer to help the EgoTR understand and correspond geometric configurations between ground and aerial images. Compared to state-of-the-art methods that impose strong assumption on geometry knowledge, the EgoTR flexibly learns the positional embeddings through the training objective and hence becomes more practical in many real-world scenarios. Although Transformer is well suited to our task, its vanilla self-attention mechanism independently interacts within image patches in each layer, which overlooks correlations between layers. Instead, this paper propose a simple yet effective self-cross attention mechanism to improve the quality of learned representations. The self-cross attention models global dependencies between adjacent layers, which relates between image patches while modeling how features evolve in the previous layer. As a result, the proposed self-cross attention leads to more stable training, improves the generalization ability and encourages representations to keep evolving as the network goes deeper. Extensive experiments demonstrate that our EgoTR performs favorably against state-of-the-art methods on standard, fine-grained and cross-dataset cross-view geo-localization tasks.