 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-guided Cross-view Image Synthesis
Nov 29, 2024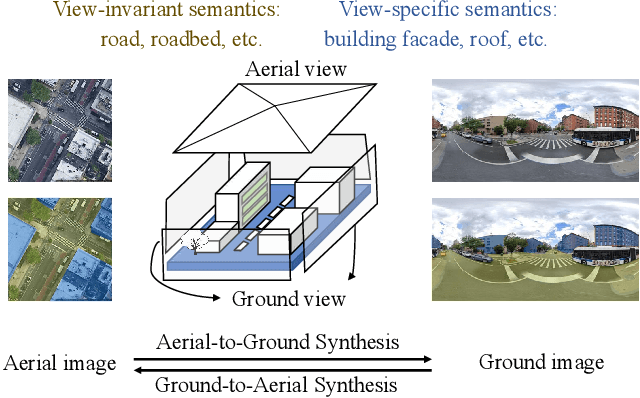


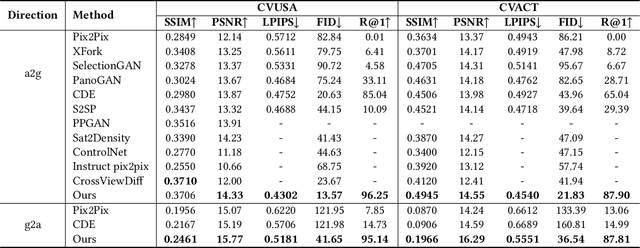
Cross-view image synthesis involves generating new images of a scene from different viewpoints or perspectives, given one input image from other viewpoints. Despite recent advancements, there are several limitations in existing methods: 1) reliance on additional data such as semantic segmentation maps or preprocessing modules to bridge the domain gap; 2) insufficient focus on view-specific semantics, leading to compromised image quality and realism; and 3) a lack of diverse datasets representing complex urban environments. To tackle these challenges, we propose: 1) a novel retrieval-guided framework that employs a retrieval network as an embedder to address the domain gap; 2) an innovative generator that enhances semantic consistency and diversity specific to the target view to improve image quality and realism; and 3) a new dataset, VIGOR-GEN, providing diverse cross-view image pairs in urban settings to enrich dataset diversity. Extensive experiments on well-known CVUSA, CVACT, and new VIGOR-GEN datasets demonstrate that our method generates images of superior realism, significantly outperforming current leading approaches, particularly in SSIM and FID evaluations.
A Survey of Large Language Models in Medicine: Progress, Application, and Challenge
Nov 09, 2023

Large language models (LLMs), such as ChatGPT, have achieved substantial attention due to their impressive human language understanding and generation capabilities. Therefore, the application of LLMs in medicine to assist physicians and patient care emerges as a promising research direction in both artificial intelligence and clinical medicine. To this end, this survey provides a comprehensive overview of the current progress, applications, and challenges faced by LLMs in medicine. Specifically, we aim to address the following questions: 1) What are LLMs and how can medical LLMs be built? 2) What are the downstream performances of medical LLMs? 3) How can medical LLMs be utilized in real-world clinical practice? 4) What challenges arise from the use of medical LLMs? 5) How can we better construct and utilize medical LLMs? As a result, this survey aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a valuable resource for constructing practical and effective medical LLMs. A regularly updated list of practical guide resources of medical LLMs can be found at https://github.com/AI-in-Health/MedLLMsPracticalGuide.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023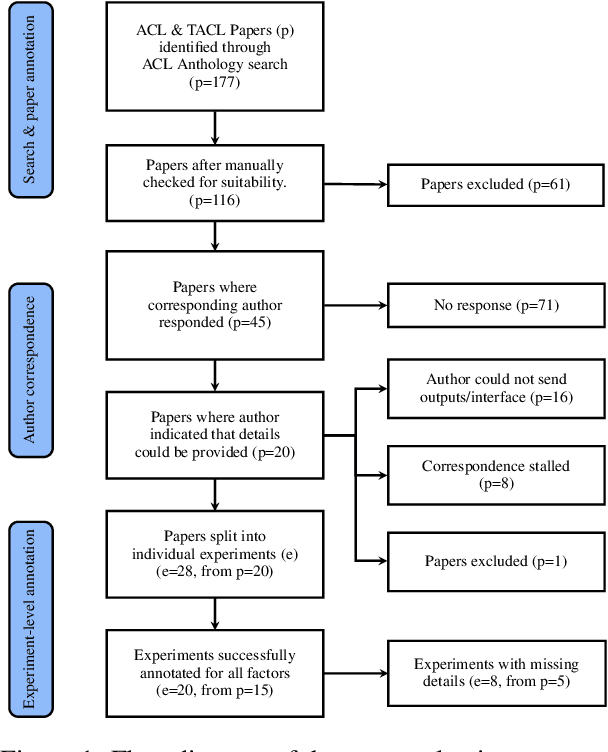
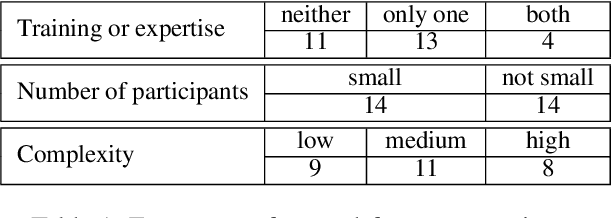


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.