 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMy Life in Artificial Intelligence: People, anecdotes, and some lessons learnt
Apr 05, 2025In this very personal workography, I relate my 40-year experiences as a researcher and educator in and around Artificial Intelligence (AI), more specifically Natural Language Processing. I describe how curiosity, and the circumstances of the day, led me to work in both industry and academia, and in various countries, including The Netherlands (Amsterdam, Eindhoven, and Utrecht), the USA (Stanford), England (Brighton), Scotland (Aberdeen), and China (Beijing and Harbin). People and anecdotes play a large role in my story; the history of AI forms its backdrop. I focus on things that might be of interest to (even) younger colleagues, given the choices they face in their own work and life at a time when AI is finally emerging from the shadows.
Reference-free Evaluation Metrics for Text Generation: A Survey
Jan 21, 2025
A number of automatic evaluation metrics have been proposed for natural language generation systems. The most common approach to automatic evaluation is the use of a reference-based metric that compares the model's output with gold-standard references written by humans. However, it is expensive to create such references, and for some tasks, such as response generation in dialogue, creating references is not a simple matter. Therefore, various reference-free metrics have been developed in recent years. In this survey, which intends to cover the full breadth of all NLG tasks, we investigate the most commonly used approaches, their application, and their other uses beyond evaluating models. The survey concludes by highlighting some promising directions for future research.
Computational Modelling of Plurality and Definiteness in Chinese Noun Phrases
Mar 07, 2024



Theoretical linguists have suggested that some languages (e.g., Chinese and Japanese) are "cooler" than other languages based on the observation that the intended meaning of phrases in these languages depends more on their contexts. As a result, many expressions in these languages are shortened, and their meaning is inferred from the context. In this paper, we focus on the omission of the plurality and definiteness markers in Chinese noun phrases (NPs) to investigate the predictability of their intended meaning given the contexts. To this end, we built a corpus of Chinese NPs, each of which is accompanied by its corresponding context, and by labels indicating its singularity/plurality and definiteness/indefiniteness. We carried out corpus assessments and analyses. The results suggest that Chinese speakers indeed drop plurality and definiteness markers very frequently. Building on the corpus, we train a bank of computational models using both classic machine learning models and state-of-the-art pre-trained language models to predict the plurality and definiteness of each NP. We report on the performance of these models and analyse their behaviours.
Intrinsic Task-based Evaluation for Referring Expression Generation
Feb 12, 2024



Recently, a human evaluation study of Referring Expression Generation (REG) models had an unexpected conclusion: on \textsc{webnlg}, Referring Expressions (REs) generated by the state-of-the-art neural models were not only indistinguishable from the REs in \textsc{webnlg} but also from the REs generated by a simple rule-based system. Here, we argue that this limitation could stem from the use of a purely ratings-based human evaluation (which is a common practice in Natural Language Generation). To investigate these issues, we propose an intrinsic task-based evaluation for REG models, in which, in addition to rating the quality of REs, participants were asked to accomplish two meta-level tasks. One of these tasks concerns the referential success of each RE; the other task asks participants to suggest a better alternative for each RE. The outcomes suggest that, in comparison to previous evaluations, the new evaluation protocol assesses the performance of each REG model more comprehensively and makes the participants' ratings more reliable and discriminable.
The Pitfalls of Defining Hallucination
Jan 15, 2024Despite impressive advances in Natural Language Generation (NLG) and Large Language Models (LLMs), researchers are still unclear about important aspects of NLG evaluation. To substantiate this claim, I examine current classifications of hallucination and omission in Data-text NLG, and I propose a logic-based synthesis of these classfications. I conclude by highlighting some remaining limitations of all current thinking about hallucination and by discussing implications for LLMs.
Models of reference production: How do they withstand the test of time?
Jul 27, 2023



In recent years, many NLP studies have focused solely on performance improvement. In this work, we focus on the linguistic and scientific aspects of NLP. We use the task of generating referring expressions in context (REG-in-context) as a case study and start our analysis from GREC, a comprehensive set of shared tasks in English that addressed this topic over a decade ago. We ask what the performance of models would be if we assessed them (1) on more realistic datasets, and (2) using more advanced methods. We test the models using different evaluation metrics and feature selection experiments. We conclude that GREC can no longer be regarded as offering a reliable assessment of models' ability to mimic human reference production, because the results are highly impacted by the choice of corpus and evaluation metrics. Our results also suggest that pre-trained language models are less dependent on the choice of corpus than classic Machine Learning models, and therefore make more robust class predictions.
Does ChatGPT have Theory of Mind?
May 23, 2023



``Theory of Mind" (ToM) is the ability to understand human thinking and decision-making, an ability that plays a crucial role in many types of social interaction between people, including linguistic communication. This paper investigates to what extent recent Large Language Models in the ChatGPT tradition possess ToM. Focussing on six well-known ToM problems, we posed each problem to two versions of ChatGPT and compared the results under a range of prompting strategies. While the results concerning ChatGPT-3 were somewhat inconclusive, ChatGPT-4 was shown to arrive at the correct answers more often than would be expected based on chance, although correct answers were often arrived at on the basis of false assumptions or invalid reasoning.
Interpreting Vision and Language Generative Models with Semantic Visual Priors
May 04, 2023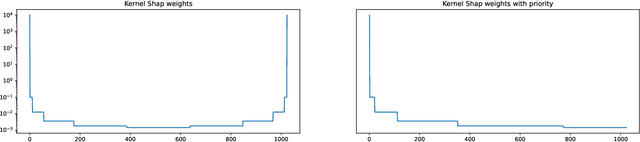

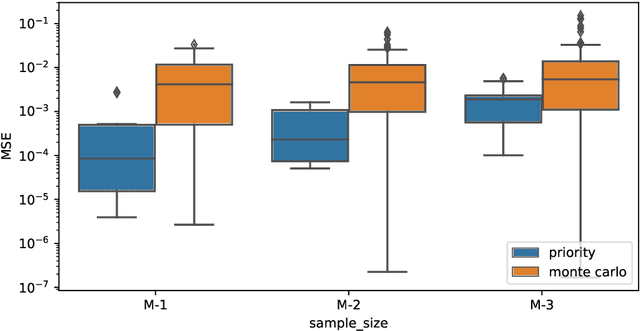
When applied to Image-to-text models, interpretability methods often provide token-by-token explanations namely, they compute a visual explanation for each token of the generated sequence. Those explanations are expensive to compute and unable to comprehensively explain the model's output. Therefore, these models often require some sort of approximation that eventually leads to misleading explanations. We develop a framework based on SHAP, that allows for generating comprehensive, meaningful explanations leveraging the meaning representation of the output sequence as a whole. Moreover, by exploiting semantic priors in the visual backbone, we extract an arbitrary number of features that allows the efficient computation of Shapley values on large-scale models, generating at the same time highly meaningful visual explanations. We demonstrate that our method generates semantically more expressive explanations than traditional methods at a lower compute cost and that it can be generalized over other explainability methods.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023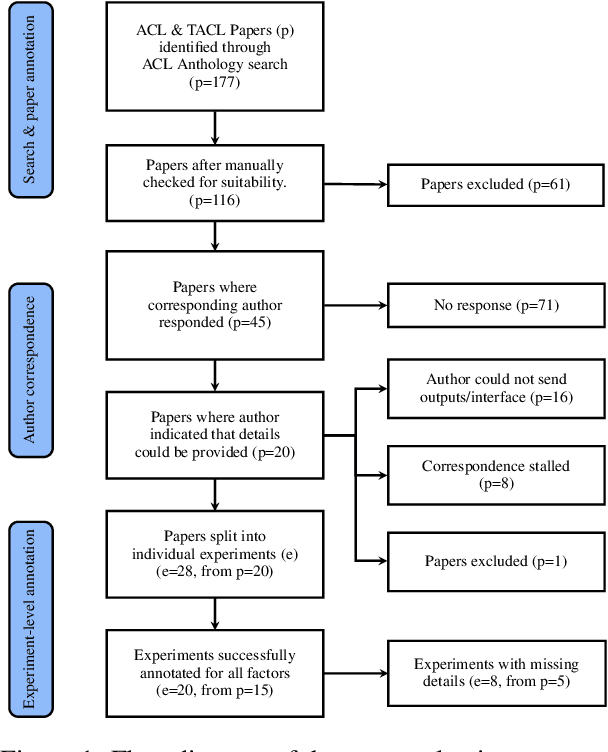
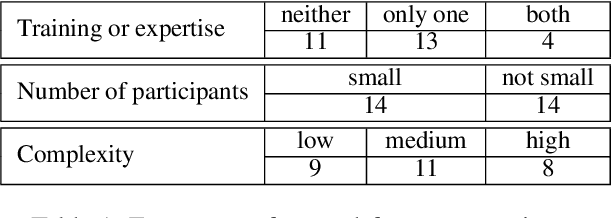


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
HL Dataset: Grounding High-Level Linguistic Concepts in Vision
Feb 23, 2023
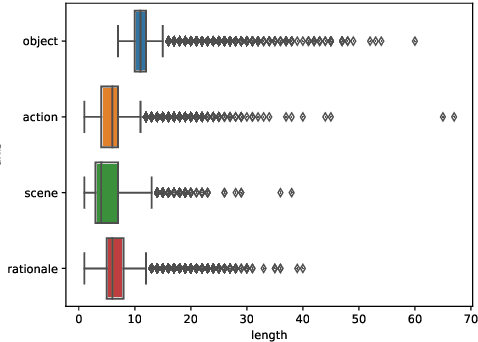
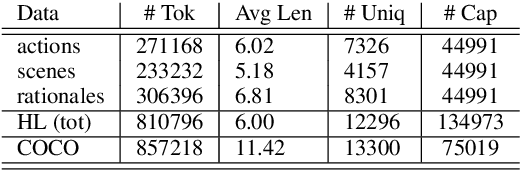
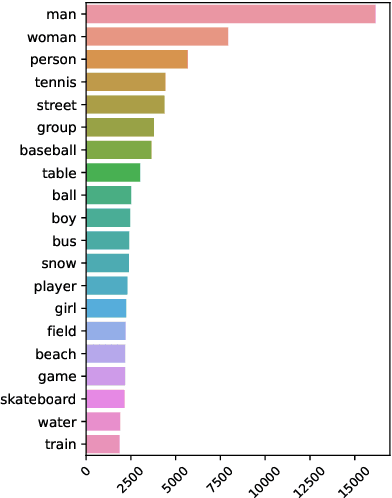
Current captioning datasets, focus on object-centric captions, describing the visible objects in the image, often ending up stating the obvious (for humans), e.g. "people eating food in a park". Although these datasets are useful to evaluate the ability of Vision & Language models to recognize the visual content, they lack in expressing trivial abstract concepts, e.g. "people having a picnic". Such concepts are licensed by human's personal experience and contribute to forming common sense assumptions. We present the High-Level Dataset; a dataset extending 14997 images of the COCO dataset with 134973 human-annotated (high-level) abstract captions collected along three axes: scenes, actions and rationales. We describe and release such dataset and we show how it can be used to assess models' multimodal grounding of abstract concepts and enrich models' visio-lingusitic representations. Moreover, we describe potential tasks enabled by this dataset involving high- and low-level concepts interactions.