 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Rational Speech Act: Pragmatic Reasoning for Multi-Turn Dialog
Jul 18, 2025As AI systems take on collaborative roles, they must reason about shared goals and beliefs-not just generate fluent language. The Rational Speech Act (RSA) framework offers a principled approach to pragmatic reasoning, but existing extensions face challenges in scaling to multi-turn, collaborative scenarios. In this paper, we introduce Collaborative Rational Speech Act (CRSA), an information-theoretic (IT) extension of RSA that models multi-turn dialog by optimizing a gain function adapted from rate-distortion theory. This gain is an extension of the gain model that is maximized in the original RSA model but takes into account the scenario in which both agents in a conversation have private information and produce utterances conditioned on the dialog. We demonstrate the effectiveness of CRSA on referential games and template-based doctor-patient dialogs in the medical domain. Empirical results show that CRSA yields more consistent, interpretable, and collaborative behavior than existing baselines-paving the way for more pragmatic and socially aware language agents.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023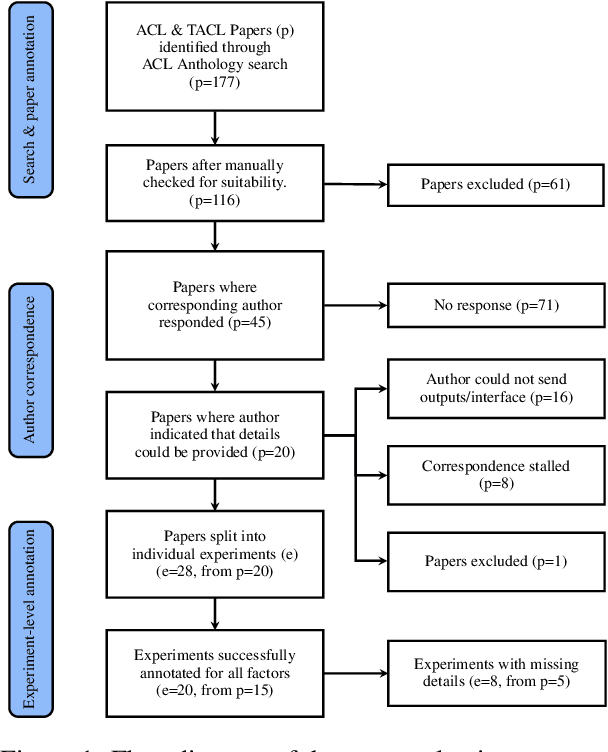
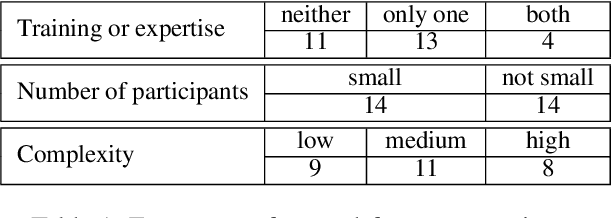


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.