 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLMs for Targeted Concept Simplification forDomain-Specific Texts
Oct 28, 2024


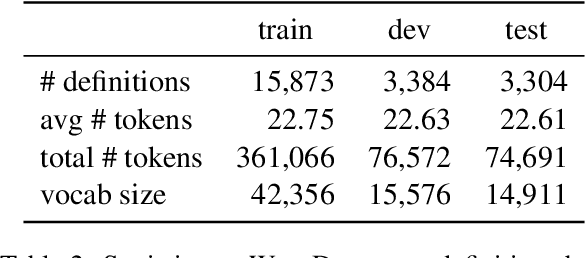
One useful application of NLP models is to support people in reading complex text from unfamiliar domains (e.g., scientific articles). Simplifying the entire text makes it understandable but sometimes removes important details. On the contrary, helping adult readers understand difficult concepts in context can enhance their vocabulary and knowledge. In a preliminary human study, we first identify that lack of context and unfamiliarity with difficult concepts is a major reason for adult readers' difficulty with domain-specific text. We then introduce "targeted concept simplification," a simplification task for rewriting text to help readers comprehend text containing unfamiliar concepts. We also introduce WikiDomains, a new dataset of 22k definitions from 13 academic domains paired with a difficult concept within each definition. We benchmark the performance of open-source and commercial LLMs and a simple dictionary baseline on this task across human judgments of ease of understanding and meaning preservation. Interestingly, our human judges preferred explanations about the difficult concept more than simplification of the concept phrase. Further, no single model achieved superior performance across all quality dimensions, and automated metrics also show low correlations with human evaluations of concept simplification ($\sim0.2$), opening up rich avenues for research on personalized human reading comprehension support.
Agents' Room: Narrative Generation through Multi-step Collaboration
Oct 03, 2024Writing compelling fiction is a multifaceted process combining elements such as crafting a plot, developing interesting characters, and using evocative language. While large language models (LLMs) show promise for story writing, they currently rely heavily on intricate prompting, which limits their use. We propose Agents' Room, a generation framework inspired by narrative theory, that decomposes narrative writing into subtasks tackled by specialized agents. To illustrate our method, we introduce Tell Me A Story, a high-quality dataset of complex writing prompts and human-written stories, and a novel evaluation framework designed specifically for assessing long narratives. We show that Agents' Room generates stories that are preferred by expert evaluators over those produced by baseline systems by leveraging collaboration and specialization to decompose the complex story writing task into tractable components. We provide extensive analysis with automated and human-based metrics of the generated output.
SEAHORSE: A Multilingual, Multifaceted Dataset for Summarization Evaluation
May 22, 2023
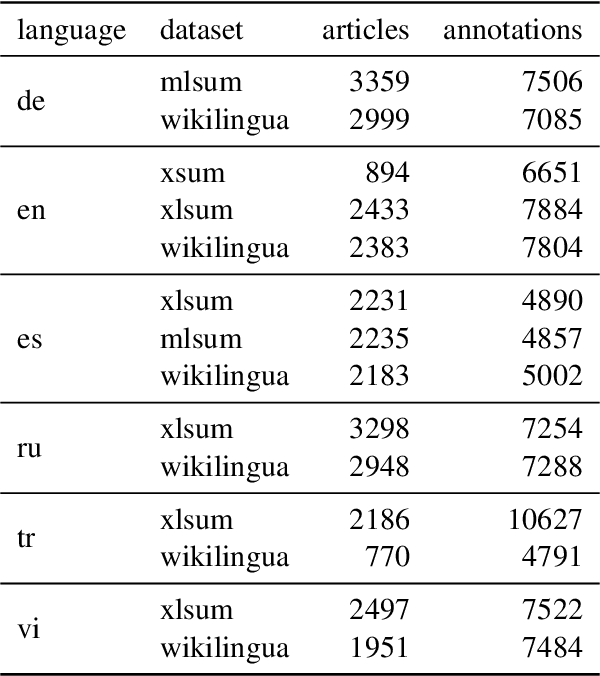
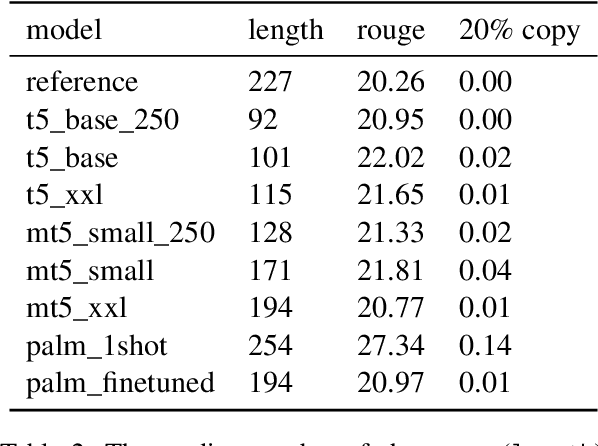
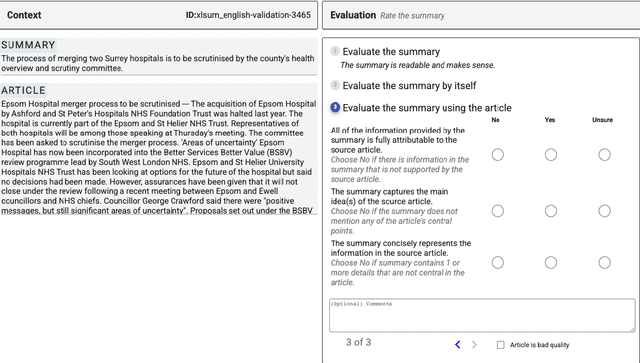
Reliable automatic evaluation of summarization systems is challenging due to the multifaceted and subjective nature of the task. This is especially the case for languages other than English, where human evaluations are scarce. In this work, we introduce SEAHORSE, a dataset for multilingual, multifaceted summarization evaluation. SEAHORSE consists of 96K summaries with human ratings along 6 quality dimensions: comprehensibility, repetition, grammar, attribution, main ideas, and conciseness, covering 6 languages, 9 systems and 4 datasets. As a result of its size and scope, SEAHORSE can serve both as a benchmark to evaluate learnt metrics, as well as a large-scale resource for training such metrics. We show that metrics trained with SEAHORSE achieve strong performance on the out-of-domain meta-evaluation benchmarks TRUE (Honovich et al., 2022) and mFACE (Aharoni et al., 2022). We make SEAHORSE publicly available for future research on multilingual and multifaceted summarization evaluation.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023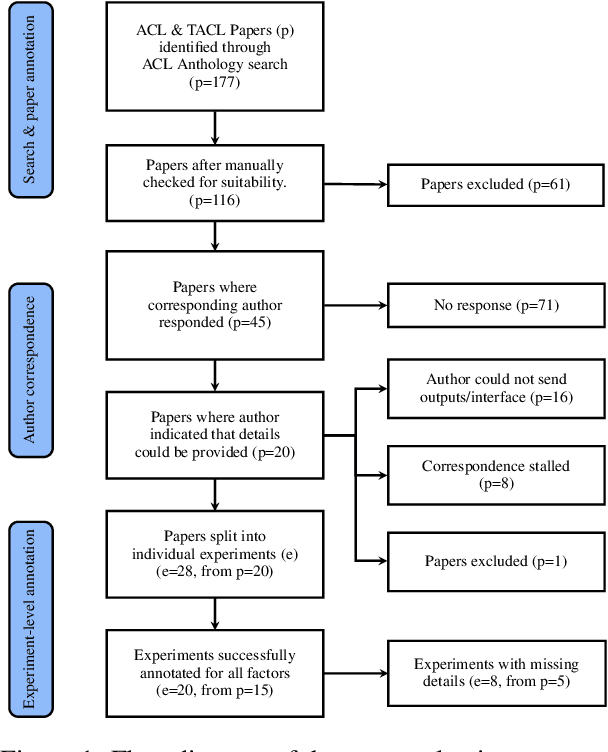
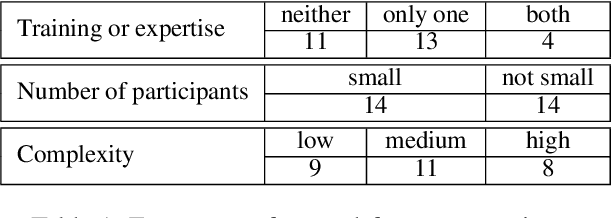


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Needle in a Haystack: An Analysis of Finding Qualified Workers on MTurk for Summarization
Dec 28, 2022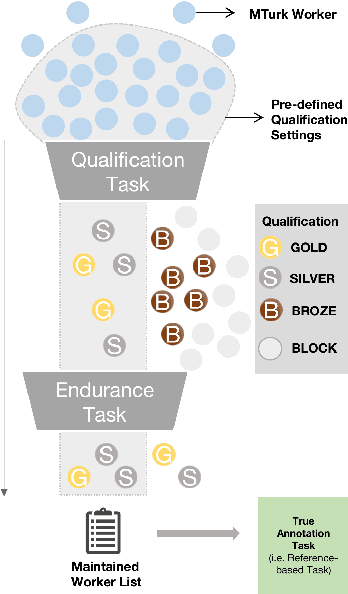


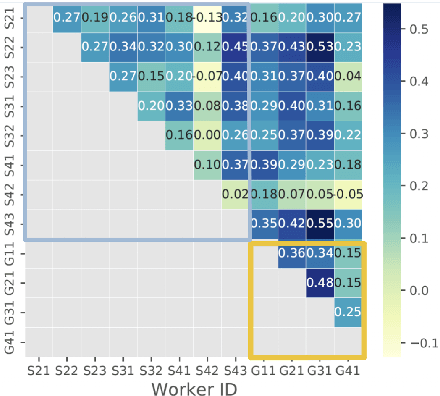
The acquisition of high-quality human annotations through crowdsourcing platforms like Amazon Mechanical Turk (MTurk) is more challenging than expected. The annotation quality might be affected by various aspects like annotation instructions, Human Intelligence Task (HIT) design, and wages paid to annotators, etc. To avoid potentially low-quality annotations which could mislead the evaluation of automatic summarization system outputs, we investigate the recruitment of high-quality MTurk workers via a three-step qualification pipeline. We show that we can successfully filter out bad workers before they carry out the evaluations and obtain high-quality annotations while optimizing the use of resources. This paper can serve as basis for the recruitment of qualified annotators in other challenging annotation tasks.
mFACE: Multilingual Summarization with Factual Consistency Evaluation
Dec 20, 2022



Abstractive summarization has enjoyed renewed interest in recent years, thanks to pre-trained language models and the availability of large-scale datasets. Despite promising results, current models still suffer from generating factually inconsistent summaries, reducing their utility for real-world application. Several recent efforts attempt to address this by devising models that automatically detect factual inconsistencies in machine generated summaries. However, they focus exclusively on English, a language with abundant resources. In this work, we leverage factual consistency evaluation models to improve multilingual summarization. We explore two intuitive approaches to mitigate hallucinations based on the signal provided by a multilingual NLI model, namely data filtering and controlled generation. Experimental results in the 45 languages from the XLSum dataset show gains over strong baselines in both automatic and human evaluation.
Dialect-robust Evaluation of Generated Text
Nov 02, 2022
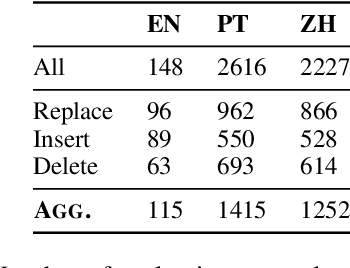


Evaluation metrics that are not robust to dialect variation make it impossible to tell how well systems perform for many groups of users, and can even penalize systems for producing text in lower-resource dialects. However, currently, there exists no way to quantify how metrics respond to change in the dialect of a generated utterance. We thus formalize dialect robustness and dialect awareness as goals for NLG evaluation metrics. We introduce a suite of methods and corresponding statistical tests one can use to assess metrics in light of the two goals. Applying the suite to current state-of-the-art metrics, we demonstrate that they are not dialect-robust and that semantic perturbations frequently lead to smaller decreases in a metric than the introduction of dialect features. As a first step to overcome this limitation, we propose a training schema, NANO, which introduces regional and language information to the pretraining process of a metric. We demonstrate that NANO provides a size-efficient way for models to improve the dialect robustness while simultaneously improving their performance on the standard metric benchmark.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Repairing the Cracked Foundation: A Survey of Obstacles in Evaluation Practices for Generated Text
Feb 14, 2022



Evaluation practices in natural language generation (NLG) have many known flaws, but improved evaluation approaches are rarely widely adopted. This issue has become more urgent, since neural NLG models have improved to the point where they can often no longer be distinguished based on the surface-level features that older metrics rely on. This paper surveys the issues with human and automatic model evaluations and with commonly used datasets in NLG that have been pointed out over the past 20 years. We summarize, categorize, and discuss how researchers have been addressing these issues and what their findings mean for the current state of model evaluations. Building on those insights, we lay out a long-term vision for NLG evaluation and propose concrete steps for researchers to improve their evaluation processes. Finally, we analyze 66 NLG papers from recent NLP conferences in how well they already follow these suggestions and identify which areas require more drastic changes to the status quo.
All That's 'Human' Is Not Gold: Evaluating Human Evaluation of Generated Text
Jul 07, 2021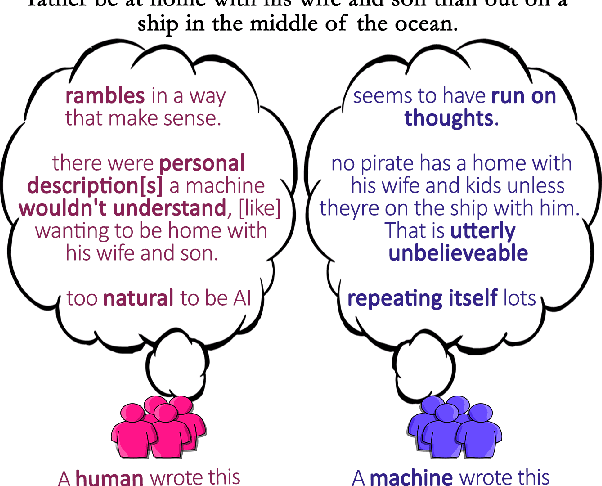
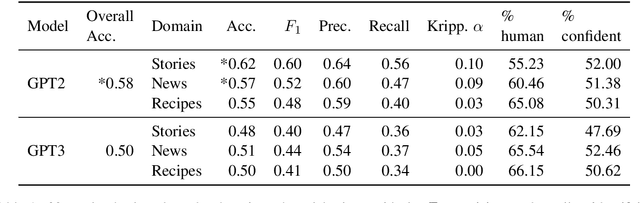

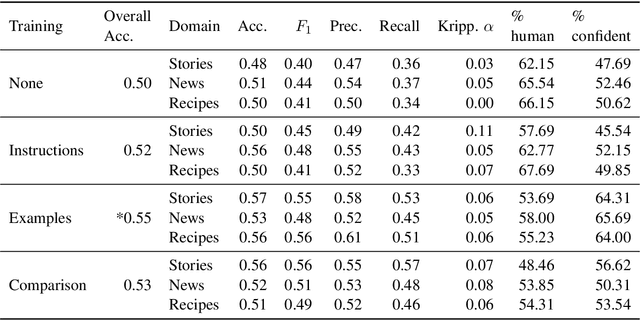
Human evaluations are typically considered the gold standard in natural language generation, but as models' fluency improves, how well can evaluators detect and judge machine-generated text? We run a study assessing non-experts' ability to distinguish between human- and machine-authored text (GPT2 and GPT3) in three domains (stories, news articles, and recipes). We find that, without training, evaluators distinguished between GPT3- and human-authored text at random chance level. We explore three approaches for quickly training evaluators to better identify GPT3-authored text (detailed instructions, annotated examples, and paired examples) and find that while evaluators' accuracy improved up to 55%, it did not significantly improve across the three domains. Given the inconsistent results across text domains and the often contradictory reasons evaluators gave for their judgments, we examine the role untrained human evaluations play in NLG evaluation and provide recommendations to NLG researchers for improving human evaluations of text generated from state-of-the-art models.