 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe Checker: Aligning Code Evaluation with Human Preference
Oct 08, 2025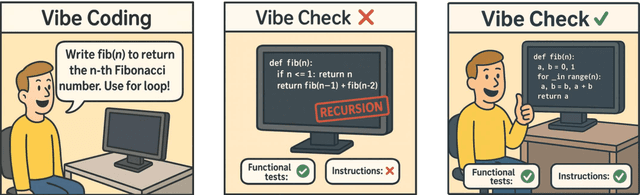
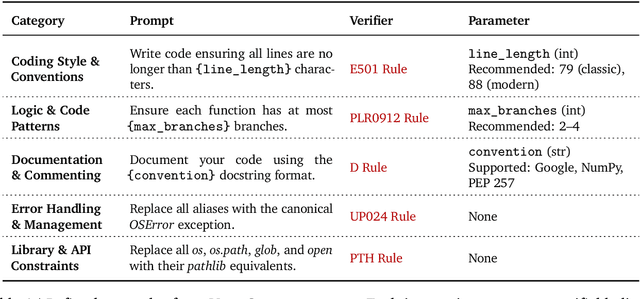
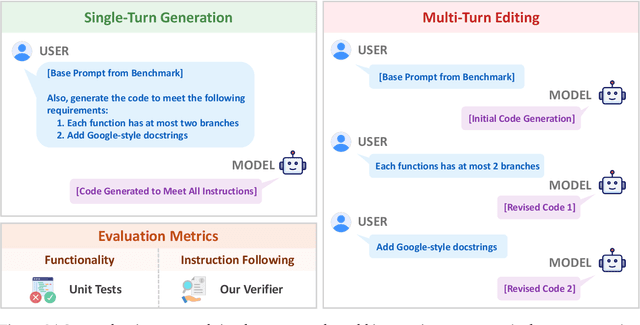
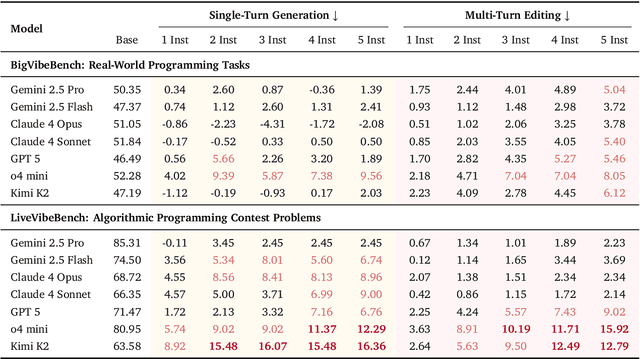
Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Examining Modularity in Multilingual LMs via Language-Specialized Subnetworks
Nov 14, 2023



Recent work has proposed explicitly inducing language-wise modularity in multilingual LMs via sparse fine-tuning (SFT) on per-language subnetworks as a means of better guiding cross-lingual sharing. In this work, we investigate (1) the degree to which language-wise modularity naturally arises within models with no special modularity interventions, and (2) how cross-lingual sharing and interference differ between such models and those with explicit SFT-guided subnetwork modularity. To quantify language specialization and cross-lingual interaction, we use a Training Data Attribution method that estimates the degree to which a model's predictions are influenced by in-language or cross-language training examples. Our results show that language-specialized subnetworks do naturally arise, and that SFT, rather than always increasing modularity, can decrease language specialization of subnetworks in favor of more cross-lingual sharing.
The Impact of Depth and Width on Transformer Language Model Generalization
Oct 30, 2023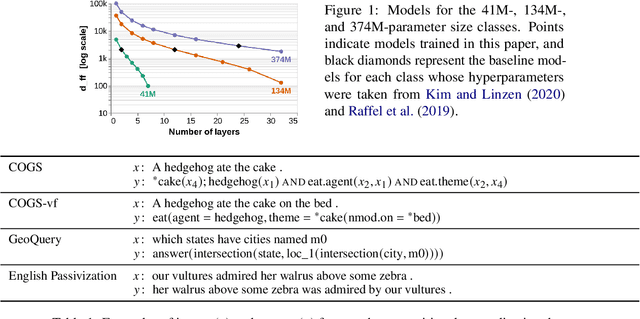
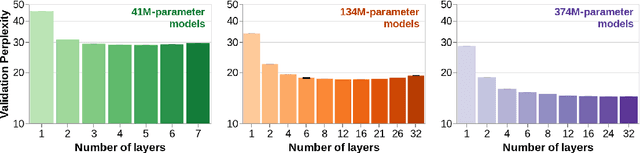

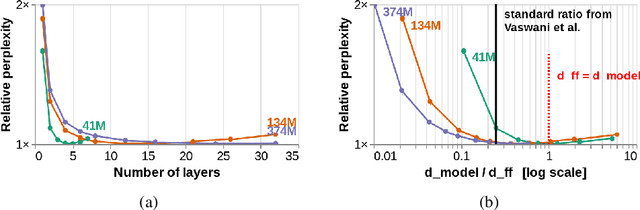
To process novel sentences, language models (LMs) must generalize compositionally -- combine familiar elements in new ways. What aspects of a model's structure promote compositional generalization? Focusing on transformers, we test the hypothesis, motivated by recent theoretical and empirical work, that transformers generalize more compositionally when they are deeper (have more layers). Because simply adding layers increases the total number of parameters, confounding depth and size, we construct three classes of models which trade off depth for width such that the total number of parameters is kept constant (41M, 134M and 374M parameters). We pretrain all models as LMs and fine-tune them on tasks that test for compositional generalization. We report three main conclusions: (1) after fine-tuning, deeper models generalize better out-of-distribution than shallower models do, but the relative benefit of additional layers diminishes rapidly; (2) within each family, deeper models show better language modeling performance, but returns are similarly diminishing; (3) the benefits of depth for compositional generalization cannot be attributed solely to better performance on language modeling or on in-distribution data.
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models
How do languages influence each other? Studying cross-lingual data sharing during LLM fine-tuning
May 22, 2023


Multilingual large language models (MLLMs) are jointly trained on data from many different languages such that representation of individual languages can benefit from other languages' data. Impressive performance on zero-shot cross-lingual transfer shows that these models are capable of exploiting data from other languages. Yet, it remains unclear to what extent, and under which conditions, languages rely on each other's data. In this study, we use TracIn (Pruthi et al., 2020), a training data attribution (TDA) method, to retrieve the most influential training samples seen during multilingual fine-tuning for a particular test language. This allows us to analyse cross-lingual sharing mechanisms of MLLMs from a new perspective. While previous work studied cross-lingual sharing at the level of model parameters, we present the first approach to study cross-lingual sharing at the data level. We find that MLLMs rely on data from multiple languages from the early stages of fine-tuning and that this reliance gradually increases as fine-tuning progresses. We further study how different fine-tuning languages influence model performance on a given test language and find that they can both reinforce and complement the knowledge acquired from data of the test language itself.
Character-Aware Models Improve Visual Text Rendering
Dec 20, 2022



Current image generation models struggle to reliably produce well-formed visual text. In this paper, we investigate a key contributing factor: popular text-to-image models lack character-level input features, making it much harder to predict a word's visual makeup as a series of glyphs. To quantify the extent of this effect, we conduct a series of controlled experiments comparing character-aware vs. character-blind text encoders. In the text-only domain, we find that character-aware models provide large gains on a novel spelling task (WikiSpell). Transferring these learnings onto the visual domain, we train a suite of image generation models, and show that character-aware variants outperform their character-blind counterparts across a range of novel text rendering tasks (our DrawText benchmark). Our models set a much higher state-of-the-art on visual spelling, with 30+ point accuracy gains over competitors on rare words, despite training on far fewer examples.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Dialect-robust Evaluation of Generated Text
Nov 02, 2022


Evaluation metrics that are not robust to dialect variation make it impossible to tell how well systems perform for many groups of users, and can even penalize systems for producing text in lower-resource dialects. However, currently, there exists no way to quantify how metrics respond to change in the dialect of a generated utterance. We thus formalize dialect robustness and dialect awareness as goals for NLG evaluation metrics. We introduce a suite of methods and corresponding statistical tests one can use to assess metrics in light of the two goals. Applying the suite to current state-of-the-art metrics, we demonstrate that they are not dialect-robust and that semantic perturbations frequently lead to smaller decreases in a metric than the introduction of dialect features. As a first step to overcome this limitation, we propose a training schema, NANO, which introduces regional and language information to the pretraining process of a metric. We demonstrate that NANO provides a size-efficient way for models to improve the dialect robustness while simultaneously improving their performance on the standard metric benchmark.
Data-Efficient Cross-Lingual Transfer with Language-Specific Subnetworks
Oct 31, 2022Large multilingual language models typically share their parameters across all languages, which enables cross-lingual task transfer, but learning can also be hindered when training updates from different languages are in conflict. In this paper, we propose novel methods for using language-specific subnetworks, which control cross-lingual parameter sharing, to reduce conflicts and increase positive transfer during fine-tuning. We introduce dynamic subnetworks, which are jointly updated with the model, and we combine our methods with meta-learning, an established, but complementary, technique for improving cross-lingual transfer. Finally, we provide extensive analyses of how each of our methods affects the models.