 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Offloading: Decomposing LLMs into Sparse Backbones and Memory Modules
May 27, 2026LLMs encode both general capabilities and domain-specific knowledge in a single set of parameters. We ask whether this capacity can be reorganized: keeping broadly useful computation in a shared backbone, while moving specialized knowledge into external memory modules. We propose \emph{knowledge offloading} (KOFF), a framework for decomposing a pretrained LLM into a sparse shared backbone and domain-specific memories. Starting from a frozen base model, we jointly learn a structured pruning mask and lightweight recovery modules, implemented as LoRA adapters and learned key-value caches. Across Llama and Qwen models from 3B to 8B, we find that non-trivial capacity can be moved out of the shared backbone without a large loss in model ability. At around 12\% global sparsity, KOFF preserves much of the unpruned model's performance, while pruning the same frozen model without memories degrades sharply. Ablations show that LoRA and learned KV memories are complementary, and specialization analyses suggest that the learned decomposition is meaningful: language-specific neurons are preferentially removed while language-general neurons largely remain in the backbone. These results suggest that knowledge can be reallocated between a shared core and swappable external memories.
Best-of-L: Cross-Lingual Reward Modeling for Mathematical Reasoning
Sep 19, 2025While the reasoning abilities of large language models (LLMs) continue to advance, it remains unclear how such ability varies across languages in multilingual LLMs and whether different languages produce reasoning paths that complement each other. To investigate this question, we train a reward model to rank generated responses for a given question across languages. Our results show that our cross-lingual reward model substantially improves mathematical reasoning performance compared to using reward modeling within a single language, benefiting even high-resource languages. While English often exhibits the highest performance in multilingual models, we find that cross-lingual sampling particularly benefits English under low sampling budgets. Our findings reveal new opportunities to improve multilingual reasoning by leveraging the complementary strengths of diverse languages.
M-Wanda: Improving One-Shot Pruning for Multilingual LLMs
May 27, 2025



Multilingual LLM performance is often critically dependent on model size. With an eye on efficiency, this has led to a surge in interest in one-shot pruning methods that retain the benefits of large-scale pretraining while shrinking the model size. However, as pruning tends to come with performance loss, it is important to understand the trade-offs between multilinguality and sparsification. In this work, we study multilingual performance under different sparsity constraints and show that moderate ratios already substantially harm performance. To help bridge this gap, we propose M-Wanda, a pruning method that models cross-lingual variation by incorporating language-aware activation statistics into its pruning criterion and dynamically adjusts layerwise sparsity based on cross-lingual importance. We show that M-Wanda consistently improves performance at minimal additional costs. We are the first to explicitly optimize pruning to retain multilingual performance, and hope to inspire future advances in multilingual pruning.
Local Contrastive Editing of Gender Stereotypes
Oct 23, 2024Stereotypical bias encoded in language models (LMs) poses a threat to safe language technology, yet our understanding of how bias manifests in the parameters of LMs remains incomplete. We introduce local contrastive editing that enables the localization and editing of a subset of weights in a target model in relation to a reference model. We deploy this approach to identify and modify subsets of weights that are associated with gender stereotypes in LMs. Through a series of experiments, we demonstrate that local contrastive editing can precisely localize and control a small subset (< 0.5%) of weights that encode gender bias. Our work (i) advances our understanding of how stereotypical biases can manifest in the parameter space of LMs and (ii) opens up new avenues for developing parameter-efficient strategies for controlling model properties in a contrastive manner.
Self-Alignment: Improving Alignment of Cultural Values in LLMs via In-Context Learning
Aug 29, 2024Improving the alignment of Large Language Models (LLMs) with respect to the cultural values that they encode has become an increasingly important topic. In this work, we study whether we can exploit existing knowledge about cultural values at inference time to adjust model responses to cultural value probes. We present a simple and inexpensive method that uses a combination of in-context learning (ICL) and human survey data, and show that we can improve the alignment to cultural values across 5 models that include both English-centric and multilingual LLMs. Importantly, we show that our method could prove useful in test languages other than English and can improve alignment to the cultural values that correspond to a range of culturally diverse countries.
On the Evaluation Practices in Multilingual NLP: Can Machine Translation Offer an Alternative to Human Translations?
Jun 20, 2024



While multilingual language models (MLMs) have been trained on 100+ languages, they are typically only evaluated across a handful of them due to a lack of available test data in most languages. This is particularly problematic when assessing MLM's potential for low-resource and unseen languages. In this paper, we present an analysis of existing evaluation frameworks in multilingual NLP, discuss their limitations, and propose several directions for more robust and reliable evaluation practices. Furthermore, we empirically study to what extent machine translation offers a {reliable alternative to human translation} for large-scale evaluation of MLMs across a wide set of languages. We use a SOTA translation model to translate test data from 4 tasks to 198 languages and use them to evaluate three MLMs. We show that while the selected subsets of high-resource test languages are generally sufficiently representative of a wider range of high-resource languages, we tend to overestimate MLMs' ability on low-resource languages. Finally, we show that simpler baselines can achieve relatively strong performance without having benefited from large-scale multilingual pretraining.
The Echoes of Multilinguality: Tracing Cultural Value Shifts during LM Fine-tuning
May 21, 2024Texts written in different languages reflect different culturally-dependent beliefs of their writers. Thus, we expect multilingual LMs (MLMs), that are jointly trained on a concatenation of text in multiple languages, to encode different cultural values for each language. Yet, as the 'multilinguality' of these LMs is driven by cross-lingual sharing, we also have reason to belief that cultural values bleed over from one language into another. This limits the use of MLMs in practice, as apart from being proficient in generating text in multiple languages, creating language technology that can serve a community also requires the output of LMs to be sensitive to their biases (Naous et al., 2023). Yet, little is known about how cultural values emerge and evolve in MLMs (Hershcovich et al., 2022a). We are the first to study how languages can exert influence on the cultural values encoded for different test languages, by studying how such values are revised during fine-tuning. Focusing on the fine-tuning stage allows us to study the interplay between value shifts when exposed to new linguistic experience from different data sources and languages. Lastly, we use a training data attribution method to find patterns in the fine-tuning examples, and the languages that they come from, that tend to instigate value shifts.
Metaphor Understanding Challenge Dataset for LLMs
Mar 18, 2024



Metaphors in natural language are a reflection of fundamental cognitive processes such as analogical reasoning and categorisation, and are deeply rooted in everyday communication. Metaphor understanding is therefore an essential task for large language models (LLMs). We release the Metaphor Understanding Challenge Dataset (MUNCH), designed to evaluate the metaphor understanding capabilities of LLMs. The dataset provides over 10k paraphrases for sentences containing metaphor use, as well as 1.5k instances containing inapt paraphrases. The inapt paraphrases were carefully selected to serve as control to determine whether the model indeed performs full metaphor interpretation or rather resorts to lexical similarity. All apt and inapt paraphrases were manually annotated. The metaphorical sentences cover natural metaphor uses across 4 genres (academic, news, fiction, and conversation), and they exhibit different levels of novelty. Experiments with LLaMA and GPT-3.5 demonstrate that MUNCH presents a challenging task for LLMs. The dataset is freely accessible at https://github.com/xiaoyuisrain/metaphor-understanding-challenge.
Examining Modularity in Multilingual LMs via Language-Specialized Subnetworks
Nov 14, 2023



Recent work has proposed explicitly inducing language-wise modularity in multilingual LMs via sparse fine-tuning (SFT) on per-language subnetworks as a means of better guiding cross-lingual sharing. In this work, we investigate (1) the degree to which language-wise modularity naturally arises within models with no special modularity interventions, and (2) how cross-lingual sharing and interference differ between such models and those with explicit SFT-guided subnetwork modularity. To quantify language specialization and cross-lingual interaction, we use a Training Data Attribution method that estimates the degree to which a model's predictions are influenced by in-language or cross-language training examples. Our results show that language-specialized subnetworks do naturally arise, and that SFT, rather than always increasing modularity, can decrease language specialization of subnetworks in favor of more cross-lingual sharing.
Do large language models solve verbal analogies like children do?
Oct 31, 2023
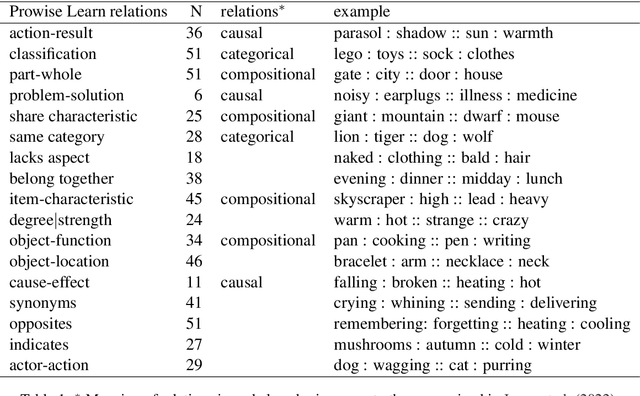
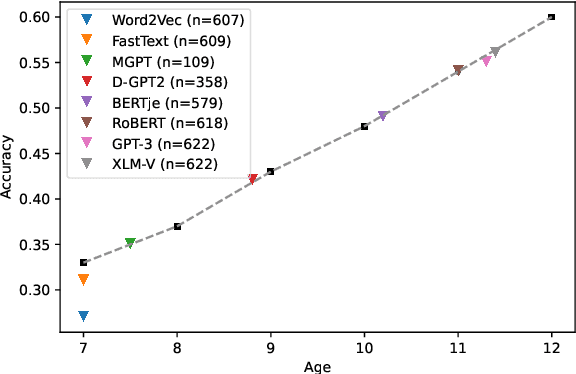
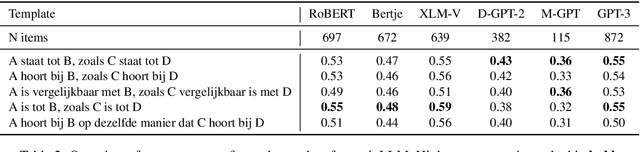
Analogy-making lies at the heart of human cognition. Adults solve analogies such as \textit{Horse belongs to stable like chicken belongs to ...?} by mapping relations (\textit{kept in}) and answering \textit{chicken coop}. In contrast, children often use association, e.g., answering \textit{egg}. This paper investigates whether large language models (LLMs) solve verbal analogies in A:B::C:? form using associations, similar to what children do. We use verbal analogies extracted from an online adaptive learning environment, where 14,002 7-12 year-olds from the Netherlands solved 622 analogies in Dutch. The six tested Dutch monolingual and multilingual LLMs performed around the same level as children, with MGPT performing worst, around the 7-year-old level, and XLM-V and GPT-3 the best, slightly above the 11-year-old level. However, when we control for associative processes this picture changes and each model's performance level drops 1-2 years. Further experiments demonstrate that associative processes often underlie correctly solved analogies. We conclude that the LLMs we tested indeed tend to solve verbal analogies by association with C like children do.